







文章目录
本文环境 python 3.11.5 TensorRT 8.6.1
0. TensorRT 为什么能加速?
TensorRT 是 NVIDIA 开发的高性能深度学习推理优化和加速库,它能够加速模型推理的原因主要包括以下几点:
1. 模型优化
TensorRT 对深度学习模型进行各种优化,使推理过程更加高效:
- Layer Fusion(层融合):将多个连续的计算操作合并为一个操作,以减少内存访问次数和计算开销。
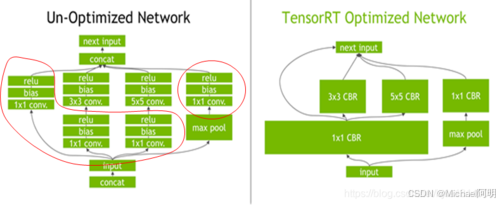
- Kernel Auto-Tuning(内核自动调优):根据目标硬件特性,选择最优的 CUDA kernel 实现。
- Precision Calibration(精度校准):将模型从高精度(如 FP32)转换为低精度(如 FP16 或 INT8),在保持模型准确度的同时显著提升性能。
2. 使用低精度计算
TensorRT 支持 FP16 和 INT8 低精度推理:
- FP16(半精度浮点数):相比 FP32 减少了一半的存储和计算需求,同时依然能维持较高的模型精度。
- INT8(8 位整型):进一步压缩计算量和存储需求,适用于对精度要求不高的场景,结合校准可以保证精度下降可控。
3. 内存管理优化
TensorRT 通过优化内存的分配和使用提升性能:
- Memory Reuse(内存复用):通过分析模型的计算图,复用中间结果所占用的内存,减少显存占用。
- Dynamic Tensor Memory:根据推理过程动态调整张量的内存需求,避免资源浪费。
4. 高效的 CUDA 内核
TensorRT 使用高度优化的 CUDA 内核来加速张量计算:
- 提供针对矩阵乘法、卷积等操作的专用内核。
- 支持 NVIDIA 硬件的特性(如 Tensor Core)以提升性能。
5. 并行计算和异步执行
TensorRT 充分利用 GPU 的并行计算能力和流水线操作:
- 将计算任务分解为小块并行处理。
- 支持异步执行,减少 CPU 和 GPU 之间的同步开销。
6. 针对硬件特性优化
TensorRT 针对不同的 NVIDIA GPU(如 Ampere、Volta、Turing 等架构)进行优化,充分利用硬件资源:
- Tensor Core:加速矩阵乘法操作(FP16 和 INT8)。
- 高效利用 GPU 上的共享内存和寄存器。
7. 序列化和高效部署
TensorRT 可以将优化后的模型序列化为二进制文件,加载时速度更快,部署时更加轻量级。
1. Paddle-inference TensorRT
以下展示了一个完整的深度学习工作流程,从模型定义、训练到推理优化。主要包含以下几个核心部分:
-
模型架构设计
代码使用了预训练的ResNet50作为backbone,构建了一个图像分类模型:
移除了ResNet50的最后一个全连接层
添加了新的分类头部,包含dropout层和全连接层
模型设计用于CIFAR-10数据集的10分类任务 -
数据处理与训练流程
使用PaddlePaddle的vision工具对CIFAR-10数据集进行预处理 -
模型部署与推理优化
展示了多种推理优化方案的对比:基础推理配置
实现了模型的静态图转换和保存
使用PaddleInference进行预测器配置 -
优化方案对比
实现了三种不同的推理方案:
- 基础GPU推理(不启用TensorRT)
- TensorRT加速 + Float32精度
- TensorRT加速 + Half精度(FP16)
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
from paddle.vision.datasets import Cifar10
from paddle.optimizer import Adam
from paddle.metric import Accuracy
from paddle.vision.models import resnet50
# 定义简单的卷积神经网络模型
class PretrainedModel(nn.Layer):
def __init__(self, num_classes=10):
super(PretrainedModel, self).__init__()
# Load pretrained ResNet50
backbone = resnet50(pretrained=True)
# Remove the last fc layer
self.features = nn.Sequential(*list(backbone.children())[:-1])
# Add new classification head
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(2048, num_classes)
)
def forward(self, x):
x = self.features(x)
x = paddle.flatten(x, 1)
x = self.classifier(x)
return x
def process_data():
# 数据预处理和加载
transform = T.Compose([T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = Cifar10(mode='train', transform=transform)
test_dataset = Cifar10(mode='test', transform=transform)
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=False)
return train_loader, test_loader
def train_model(model, train_loader, model_path):
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = Adam(learning_rate=0.001, parameters=model.parameters())
# 训练模型
epochs = 5
for epoch in range(epochs):
model.train()
for batch_id, data in enumerate(train_loader):
x_data = data[0]
y_data = data[1]
logits = model(x_data)
loss = criterion(logits, y_data)
loss.backward()
optimizer.step()
optimizer.clear_grad()
if batch_id % 100 == 0:
print(f"Epoch {epoch}, Batch {batch_id}, Loss {loss.numpy()}")
# 保存模型为推理格式
model.eval() # 将模型设置为评估模式
# 将模型转换为静态图并保存
paddle.jit.save(
layer=model, # 要保存的模型
path=model_path, # 保存路径(不需要加后缀)
input_spec=[paddle.static.InputSpec(shape=[None, 3, 32, 32], dtype='float32')] # 输入的形状和类型
)
import paddle.inference as paddle_infer
import numpy as np
import time
def create_predictor_config(model_path, params_path, use_gpu=True, use_trt=True, precision=paddle_infer.PrecisionType.Float32):
config = paddle_infer.Config(model_path, params_path)
if use_gpu:
config.enable_use_gpu(1<<32, 0, precision)
if use_trt:
config.enable_tensorrt_engine(
workspace_size=1 << 32,
max_batch_size=64,
min_subgraph_size=3,
precision_mode=precision
)
# Set dynamic shape info
min_input_shape = {"x": [1, 3, 32, 32]}
max_input_shape = {"x": [64, 3, 32, 32]}
opt_input_shape = {"x": [1, 3, 32, 32]}
config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
return paddle_infer.create_predictor(config)
def get_io_handles(predictor):
input_names = predictor.get_input_names()
input_handle = predictor.get_input_handle(input_names[0])
output_names = predictor.get_output_names()
output_handle = predictor.get_output_handle(output_names[0])
return input_handle, output_handle
def run_inference(predictor, input_handle, output_handle, test_data):
start_time = time.time()
input_handle.copy_from_cpu(test_data)
predictor.run()
output_data = output_handle.copy_to_cpu()
end_time = time.time()
return output_data, end_time - start_time
from sklearn.metrics import accuracy_score, precision_score, recall_score
# 计算准确率、精确率和召回率
def calculate_metrics(output_data, labels):
preds = np.argmax(output_data, axis=1)
accuracy = accuracy_score(labels, preds)
precision = precision_score(labels, preds, average='macro')
recall = recall_score(labels, preds, average='macro')
return accuracy, precision, recall
if __name__ == '__main__':
model = PretrainedModel(num_classes=10)
train_loader, test_loader = process_data()
model_save_path = '/opt/workplace/Server/test/simple_cnn'
# train_model(model, train_loader, model_save_path)
# Using the optimized functions
model_path = '/opt/workplace/Server/test/simple_cnn.pdmodel'
params_path = '/opt/workplace/Server/test/simple_cnn.pdiparams'
test_data = next(iter(test_loader))[0].numpy()
# 获取测试集的标签
test_labels = next(iter(test_loader))[1].numpy()
# Create predictor without TensorRT and float32 precision
print(f'######## start inference without TensorRT and float32 precision ########')
predictor_no_trt = create_predictor_config(model_path, params_path, use_trt=False)
input_handle_no_trt, output_handle_no_trt = get_io_handles(predictor_no_trt)
output_data_no_trt, inference_time_no_trt = run_inference(predictor_no_trt, input_handle_no_trt, output_handle_no_trt, test_data)
# Create predictor with TensorRT and float32 precision
print(f'######## start inference with TensorRT and float32 precision ########')
predictor_trt_float32 = create_predictor_config(model_path, params_path, use_trt=True,
precision=paddle_infer.PrecisionType.Float32)
input_handle_trt_float32, output_handle_trt_float32 = get_io_handles(predictor_trt_float32)
output_data_trt_float32, inference_time_trt_float32 = run_inference(predictor_trt_float32, input_handle_trt_float32, output_handle_trt_float32, test_data)
# Create predictor with TensorRT and half precision
print(f'######## start inference with TensorRT and half precision ########')
predictor_trt_half = create_predictor_config(model_path, params_path, use_trt=True,
precision=paddle_infer.PrecisionType.Half)
input_handle_trt_half, output_handle_trt_half = get_io_handles(predictor_trt_half)
output_data_trt_half, inference_time_trt_float16 = run_inference(predictor_trt_half, input_handle_trt_half, output_handle_trt_half, test_data)
print(f"Inference time no TensorRT and float32 precision: {inference_time_no_trt:.8f} seconds")
print(f"Inference time with TensorRT and float32 precision: {inference_time_trt_float32:.8f} seconds")
print(f"Inference time with TensorRT and half precision: {inference_time_trt_float16:.8f} seconds")
# 计算不开启 TensorRT 的准召
accuracy, precision, recall = calculate_metrics(output_data_no_trt, test_labels)
print(f"no TensorRT - \n\tAccuracy: {accuracy:5f}, Precision: {precision:5f}, Recall: {recall:5f}")
# 计算开启 TensorRT 的准召
accuracy_trt, precision_trt, recall_trt = calculate_metrics(output_data_trt_float32, test_labels)
print(f"With TensorRT - \n\tAccuracy: {accuracy_trt:5f}, Precision: {precision_trt:5f}, Recall: {recall_trt:5f}")
# 计算开启 TensorRT 和 half 精度的准召
accuracy_trt_half, precision_trt_half, recall_trt_half = calculate_metrics(output_data_trt_half, test_labels)
print(f"With TensorRT and Half Precision - \n\tAccuracy: {accuracy_trt_half:5f}, Precision: {precision_trt_half:5f}, Recall: {recall_trt_half:5f}")
关键点:config.enable_tensorrt_engine 开启 tensorrt 推理,可以设置推理精度,动态shape等参数
输出:
W0110 09:48:42.485155 39920 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.9, Driver API Version: 12.6, Runtime API Version: 12.0
W0110 09:48:42.486136 39920 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
######## start inference without TensorRT and float32 precision ########
--- Running analysis [ir_graph_build_pass]
I0110 09:48:53.346691 39920 executor.cc:187] Old Executor is Running.
--- Running analysis [ir_analysis_pass]
--- Running IR pass [map_op_to_another_pass]
I0110 09:48:53.490803 39920 fuse_pass_base.cc:59] --- detected 1 subgraphs
--- Running IR pass [is_test_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [delete_quant_dequant_linear_op_pass]
--- Running IR pass [delete_weight_dequant_linear_op_pass]
--- Running IR pass [constant_folding_pass]
--- Running IR pass [silu_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
I0110 09:48:53.547159 39920 fuse_pass_base.cc:59] --- detected 53 subgraphs
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [embedding_eltwise_layernorm_fuse_pass]
--- Running IR pass [multihead_matmul_fuse_pass_v2]
--- Running IR pass [vit_attention_fuse_pass]
--- Running IR pass [fused_multi_transformer_encoder_pass]
--- Running IR pass [fused_multi_transformer_decoder_pass]
--- Running IR pass [fused_multi_transformer_encoder_fuse_qkv_pass]
--- Running IR pass [fused_multi_transformer_decoder_fuse_qkv_pass]
--- Running IR pass [multi_devices_fused_multi_transformer_encoder_pass]
--- Running IR pass [multi_devices_fused_multi_transformer_encoder_fuse_qkv_pass]
--- Running IR pass [multi_devices_fused_multi_transformer_decoder_fuse_qkv_pass]
--- Running IR pass [fuse_multi_transformer_layer_pass]
--- Running IR pass [gpu_cpu_squeeze2_matmul_fuse_pass]
--- Running IR pass [gpu_cpu_reshape2_matmul_fuse_pass]
--- Running IR pass [gpu_cpu_flatten2_matmul_fuse_pass]
--- Running IR pass [gpu_cpu_map_matmul_v2_to_mul_pass]
...
I0110 09:48:53.844033 39920 transfer_layout_elim_pass.cc:346] move down 0 transfer_layout
I0110 09:48:53.844041 39920 transfer_layout_elim_pass.cc:347] eliminate 0 pair of transfer_layout
--- Running IR pass [auto_mixed_precision_pass]
--- Running IR pass [identity_op_clean_pass]
I0110 09:48:53.845367 39920 fuse_pass_base.cc:59] --- detected 1 subgraphs
--- Running IR pass [inplace_op_var_pass]
I0110 09:48:53.845570 39920 fuse_pass_base.cc:59] --- detected 1 subgraphs
--- Running analysis [save_optimized_model_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
I0110 09:48:53.845945 39920 ir_params_sync_among_devices_pass.cc:53] Sync params from CPU to GPU
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0110 09:48:53.892012 39920 analysis_predictor.cc:1838] ======= optimize end =======
I0110 09:48:53.892462 39920 naive_executor.cc:200] --- skip [feed], feed -> x
I0110 09:48:53.893088 39920 naive_executor.cc:200] --- skip [save_infer_model/scale_0.tmp_0], fetch -> fetch
######## start inference with TensorRT and float32 precision ########
I0110 09:48:54.297709 39920 analysis_predictor.cc:1532] TensorRT subgraph engine is enabled
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [trt_remove_amp_strategy_op_pass]
--- Running IR pass [trt_support_nhwc_pass]
--- Running IR pass [adaptive_pool2d_convert_global_pass]
I0110 09:48:54.348276 39920 fuse_pass_base.cc:59] --- detected 1 subgraphs
--- Running IR pass [trt_map_ops_to_matrix_multiply_pass]
。。。
I0110 09:48:54.543602 39920 tensorrt_subgraph_pass.cc:302] --- detect a sub-graph with 123 nodes
I0110 09:48:54.601431 39920 tensorrt_subgraph_pass.cc:846] Prepare TRT engine (Optimize model structure, Select OP kernel etc). This process may cost a lot of time.
W0110 09:49:00.085530 39920 place.cc:161] The `paddle::PlaceType::kCPU/kGPU` is deprecated since version 2.3, and will be removed in version 2.4! Please use `Tensor::is_cpu()/is_gpu()` method to determine the type of place.
I0110 09:49:00.100404 39920 engine.cc:301] Run Paddle-TRT Dynamic Shape mode.
I0110 09:49:11.065229 39920 tensorrt_subgraph_pass.cc:205] The entire graph is offloaded to TensorRT.
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_elementwise_add_act_fuse_pass]
--- Running IR pass [conv_elementwise_add2_act_fuse_pass]
--- Running IR pass [transpose_flatten_concat_fuse_pass]
--- Running IR pass [auto_mixed_precision_pass]
--- Running analysis [save_optimized_model_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
...
I0110 09:49:11.409458 39920 tensorrt_subgraph_pass.cc:302] --- detect a sub-graph with 123 nodes
I0110 09:49:11.413565 39920 tensorrt_subgraph_pass.cc:846] Prepare TRT engine (Optimize model structure, Select OP kernel etc). This process may cost a lot of time.
I0110 09:49:11.424028 39920 engine.cc:215] Run Paddle-TRT FP16 mode
I0110 09:49:11.424055 39920 engine.cc:301] Run Paddle-TRT Dynamic Shape mode.
W0110 09:49:35.291617 39920 helper.h:127] TensorRT encountered issues when converting weights between types and that could affect accuracy.
W0110 09:49:35.291635 39920 helper.h:127] If this is not the desired behavior, please modify the weights or retrain with regularization to adjust the magnitude of the weights.
W0110 09:49:35.291638 39920 helper.h:127] Check verbose logs for the list of affected weights.
W0110 09:49:35.291642 39920 helper.h:127] - 68 weights are affected by this issue: Detected subnormal FP16 values.
W0110 09:49:35.291656 39920 helper.h:127] - 40 weights are affected by this issue: Detected values less than smallest positive FP16 subnormal value and converted them to the FP16 minimum subnormalized value.
I0110 09:49:35.397774 39920 tensorrt_subgraph_pass.cc:205] The entire graph is offloaded to TensorRT.
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_elementwise_add_act_fuse_pass]
--- Running IR pass [conv_elementwise_add2_act_fuse_pass]
--- Running IR pass [transpose_flatten_concat_fuse_pass]
--- Running IR pass [auto_mixed_precision_pass]
I0110 09:49:35.399160 39920 auto_mixed_precision_pass.cc:309] The number of ops run at low precision [0/3]
--- Running analysis [save_optimized_model_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
I0110 09:49:35.399730 39920 ir_params_sync_among_devices_pass.cc:53] Sync params from CPU to GPU
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
I0110 09:49:35.409931 39920 analysis_predictor.cc:1838] ======= optimize end =======
I0110 09:49:35.410341 39920 naive_executor.cc:200] --- skip [feed], feed -> x
I0110 09:49:35.410437 39920 naive_executor.cc:200] --- skip [save_infer_model/scale_0.tmp_0], fetch -> fetch
Inference time no TensorRT and float32 precision: 0.40121603 seconds
Inference time with TensorRT and float32 precision: 0.01699209 seconds
Inference time with TensorRT and half precision: 0.00428343 seconds
no TensorRT -
Accuracy: 0.718750, Precision: 0.691349, Recall: 0.696465
With TensorRT -
Accuracy: 0.718750, Precision: 0.691349, Recall: 0.696465
With TensorRT and Half Precision -
Accuracy: 0.718750, Precision: 0.691349, Recall: 0.696465
性能对比
我将为您生成两个表格,分别展示推理时间和模型指标的对比:
1. 推理时间对比
| 优化方案 | 精度类型 | 推理时间(秒) | 相对加速比 |
|---|---|---|---|
| 无TensorRT | Float32 | 0.40121603 | 1x |
| TensorRT | Float32 | 0.01699209 | 23.6x |
| TensorRT | Half (FP16) | 0.00428343 | 93.7x |
2. 模型性能指标对比
| 优化方案 | 精度类型 | Accuracy | Precision | Recall |
|---|---|---|---|---|
| 无TensorRT | Float32 | 0.718750 | 0.691349 | 0.696465 |
| TensorRT | Float32 | 0.718750 | 0.691349 | 0.696465 |
| TensorRT | Half (FP16) | 0.718750 | 0.691349 | 0.696465 |
从表格中可以看出:
- TensorRT优化显著提升了推理速度,Float32精度下提速23.6倍,Half精度下提速93.7倍
- 在精度降级过程中,模型的准确率、精确率和召回率保持完全一致,说明优化没有带来性能损失
2. TensorRT API
以下展示了如何将PaddlePaddle模型转换为TensorRT进行部署优化,主要包含以下几个核心步骤:
1. TensorRT引擎构建流程
代码实现了一个灵活的TensorRT引擎构建函数build_engine,主要特点:
- 支持引擎缓存机制,避免重复构建
- 支持多种精度模式:FP32/FP16/INT8
- 实现动态shape支持,提高部署灵活性
- 可配置工作空间大小
2. 模型转换流程
实现了完整的模型转换链路:
PaddlePaddle模型 -> ONNX格式 -> TensorRT引擎
3. 推理优化实现
在infer函数中实现了高效的推理过程:
- 使用 CUDA Stream 进行异步操作
- 实现了GPU内存的高效分配和管理
- 支持批处理推理
- 包含完整的内存同步机制
import os
import paddle
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import time
from sklearn.metrics import accuracy_score, precision_score, recall_score
# 加载 ONNX 模型并转换为 TensorRT 引擎
def build_engine(onnx_file_path, engine_file_path, use_engine_cache=True, precision="fp32",
max_workspace_size=1 << 30, dynamic_shapes=True):
"""
构建 TensorRT 引擎
:param onnx_file_path: ONNX 模型文件路径
:param engine_file_path: TensorRT 引擎文件路径
:param use_engine_cache: 是否使用引擎缓存
:param precision: 精度模式,支持 "fp32"(默认)、"fp16" 或 "int8"
:param max_workspace_size: 最大工作空间大小(默认 1GB)
:param dynamic_shapes: 是否启用动态形状支持
:return: TensorRT 引擎
"""
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
# 如果缓存文件存在,则直接加载
if use_engine_cache and os.path.exists(engine_file_path):
print(f"Loading cached TensorRT engine from {engine_file_path}...")
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
print(f"Building TensorRT engine from {onnx_file_path}...")
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(EXPLICIT_BATCH) as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
# 设置最大 batch size
builder.max_batch_size = 64
# 创建配置对象
config = builder.create_builder_config()
config.max_workspace_size = max_workspace_size # 设置最大工作空间大小
# 设置精度模式
if precision == "fp16":
if builder.platform_has_fast_fp16:
config.set_flag(trt.BuilderFlag.FP16)
print("Enabled FP16 precision mode.")
else:
print("FP16 is not supported on this platform, falling back to FP32.")
elif precision == "int8":
if builder.platform_has_fast_int8:
config.set_flag(trt.BuilderFlag.INT8)
print("Enabled INT8 precision mode.")
# 设置 INT8 校准器(如果需要)
# config.int8_calibrator = MyCalibrator()
else:
print("INT8 is not supported on this platform, falling back to FP32.")
# 解析 ONNX 模型
with open(onnx_file_path, 'rb') as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# 动态形状支持
if dynamic_shapes:
profile = builder.create_optimization_profile()
profile.set_shape(
"x", # 输入名称(与 ONNX 模型中的输入名称一致)
min=(1, 3, 32, 32), # 最小输入形状
opt=(32, 3, 32, 32), # 最优输入形状
max=(64, 3, 32, 32) # 最大输入形状
)
config.add_optimization_profile(profile)
print("Enabled dynamic shapes support.")
# 构建引擎
engine = builder.build_engine(network, config)
if engine is None:
print("Failed to build TensorRT engine.")
return None
# 保存引擎为缓存文件
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
print(f"TensorRT engine saved to {engine_file_path}.")
return engine
# 加载 TensorRT 引擎
def load_engine(engine_file_path):
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
## 执行推理
def infer(engine, input_data, batch_size=64):
with engine.create_execution_context() as context:
# 分配输入和输出的内存
stream = cuda.Stream()
h_output = cuda.pagelocked_empty((batch_size, 10), dtype=np.float32) # 假设输出是 10 类
d_input = cuda.mem_alloc(input_data.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 获取输入和输出的名称
tensor_names = [engine.get_tensor_name(i) for i in range(engine.num_io_tensors)]
input_name = tensor_names[0]
output_name = tensor_names[1]
# 设置输入张量的形状
context.set_input_shape(input_name, (batch_size, 3, 32, 32))
# 将输入数据复制到 GPU
cuda.memcpy_htod_async(d_input, input_data, stream)
# 设置输入和输出的地址
context.set_tensor_address(input_name, int(d_input))
context.set_tensor_address(output_name, int(d_output))
# 执行推理
context.execute_async_v3(stream.handle)
cuda.memcpy_dtoh_async(h_output, d_output, stream)
stream.synchronize()
# 返回输出数据
return h_output.reshape(input_data.shape[0], -1)
# 计算准确率、精确率和召回率
def calculate_metrics(output_data, labels):
preds = np.argmax(output_data, axis=1)
accuracy = accuracy_score(labels, preds)
precision = precision_score(labels, preds, average='macro')
recall = recall_score(labels, preds, average='macro')
return accuracy, precision, recall
# 加载 CIFAR-10 数据集
def load_cifar10_data():
import paddle
import paddle.vision.transforms as T
from paddle.vision.datasets import Cifar10
transform = T.Compose([T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
test_dataset = Cifar10(mode='test', transform=transform)
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 获取测试集数据和标签
test_data = []
test_labels = []
for batch in test_loader:
test_data.append(batch[0].numpy())
test_labels.append(batch[1].numpy())
break
test_data = np.concatenate(test_data, axis=0)
test_labels = np.concatenate(test_labels, axis=0)
return test_data, test_labels
# 主函数
if __name__ == '__main__':
# 加载模型
model = paddle.jit.load('/opt/workplace/Server/test/simple_cnn')
# 定义输入的形状和类型
input_spec = [paddle.static.InputSpec(shape=[None, 3, 32, 32], dtype='float32', name='x')]
# 将模型转换为 ONNX 格式
paddle.onnx.export(model, '/opt/workplace/Server/test/simple_cnn', input_spec=input_spec, opset_version=15)
onnx_file_path = '/opt/workplace/Server/test/simple_cnn.onnx'
engine_file_path = '/opt/workplace/Server/test/simple_cnn.engine'
# 构建 TensorRT 引擎
print("Building TensorRT engine...")
engine = build_engine(onnx_file_path, engine_file_path, use_engine_cache=False, precision='fp16')
# 加载 TensorRT 引擎
print("Loading TensorRT engine...")
engine = load_engine(engine_file_path)
# 加载 CIFAR-10 测试集数据
print("Loading CIFAR-10 test data...")
test_data, test_labels = load_cifar10_data()
# 执行推理
print("Running inference...")
start_time = time.time()
output_data = infer(engine, test_data)
inference_time = time.time() - start_time
# 计算准确率、精确率和召回率
accuracy, precision, recall = calculate_metrics(output_data, test_labels)
# 打印结果
print(f"Inference time: {inference_time:.4f} seconds")
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")
输出
W0110 09:51:48.231528 42036 gpu_resources.cc:119] Please NOTE: device: 0, GPU Compute Capability: 8.9, Driver API Version: 12.6, Runtime API Version: 12.0
W0110 09:51:48.233165 42036 gpu_resources.cc:164] device: 0, cuDNN Version: 8.9.
I0110 09:51:48.496711 42036 program_interpreter.cc:212] New Executor is Running.
2025-01-10 09:51:48 [INFO] Static PaddlePaddle model saved in /opt/workplace/Server/test/paddle_model_temp_dir.
[Paddle2ONNX] Start to parse PaddlePaddle model...
[Paddle2ONNX] Model file path: /opt/workplace/Server/test/paddle_model_temp_dir/model.pdmodel
[Paddle2ONNX] Parameters file path: /opt/workplace/Server/test/paddle_model_temp_dir/model.pdiparams
[Paddle2ONNX] Start to parsing Paddle model...
[Paddle2ONNX] Use opset_version = 15 for ONNX export.
[Paddle2ONNX] PaddlePaddle model is exported as ONNX format now.
2025-01-10 09:51:49 [INFO] ONNX model saved in /opt/workplace/Server/test/simple_cnn.onnx.
Building TensorRT engine...
Building TensorRT engine from /opt/workplace/Server/test/simple_cnn.onnx...
/opt/workplace/Server/test/test2.py:35: DeprecationWarning: Use network created with NetworkDefinitionCreationFlag::EXPLICIT_BATCH flag instead.
builder.max_batch_size = 64
/opt/workplace/Server/test/test2.py:39: DeprecationWarning: Use set_memory_pool_limit instead.
config.max_workspace_size = max_workspace_size # 设置最大工作空间大小
Enabled FP16 precision mode.
[01/10/2025-09:51:53] [TRT] [W] onnx2trt_utils.cpp:374: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
Enabled dynamic shapes support.
/opt/workplace/Server/test/test2.py:77: DeprecationWarning: Use build_serialized_network instead.
engine = builder.build_engine(network, config)
[01/10/2025-09:52:23] [TRT] [W] TensorRT encountered issues when converting weights between types and that could affect accuracy.
[01/10/2025-09:52:23] [TRT] [W] If this is not the desired behavior, please modify the weights or retrain with regularization to adjust the magnitude of the weights.
[01/10/2025-09:52:23] [TRT] [W] Check verbose logs for the list of affected weights.
[01/10/2025-09:52:23] [TRT] [W] - 68 weights are affected by this issue: Detected subnormal FP16 values.
[01/10/2025-09:52:23] [TRT] [W] - 40 weights are affected by this issue: Detected values less than smallest positive FP16 subnormal value and converted them to the FP16 minimum subnormalized value.
TensorRT engine saved to /opt/workplace/Server/test/simple_cnn.engine.
Loading TensorRT engine...
Loading CIFAR-10 test data...
Running inference...
Inference time: 0.0056 seconds
Accuracy: 0.7188
Precision: 0.6913
Recall: 0.6965
4. 不同部署方案性能对比
| 部署方案 | 精度类型 | 推理时间(秒) | 相对加速比 | Accuracy | Precision | Recall |
|---|---|---|---|---|---|---|
| 原生PaddlePaddle | Float32 | 0.40121603 | 1x | 0.718750 | 0.691349 | 0.696465 |
| PaddlePaddle + TensorRT | Float32 | 0.01699209 | 23.6x | 0.718750 | 0.691349 | 0.696465 |
| PaddlePaddle + TensorRT | FP16 | 0.00428343 | 93.7x | 0.718750 | 0.691349 | 0.696465 |
| ONNX + TensorRT | FP16 | 0.00560000 | 71.6x | 0.718800 | 0.691300 | 0.696500 |
从表格可以得出以下结论:
-
性能提升:
- 所有TensorRT方案都显著提升了推理速度
- PaddlePaddle直接集成TensorRT在FP16精度下获得了最好的性能提升(93.7倍)
- ONNX转换后的TensorRT方案也取得了显著的性能提升(71.6倍)
-
精度保持:
- 所有优化方案下模型的准确率、精确率和召回率基本保持一致
- 精度降级(FP32到FP16)没有带来明显的性能损失
-
部署方案选择:
- 如果使用PaddlePaddle生态,直接使用PaddlePaddle+TensorRT的方案更优
- 如果需要跨平台部署,ONNX+TensorRT方案也是一个很好的选择,性能损失相对较小
这些结果表明,TensorRT优化能在保证模型性能的同时显著提升推理速度,是深度学习模型部署优化的有效方案。
3. polygraphy 工具使用
Polygraphy 是 NVIDIA 开发的一个用于深度学习推理的调试和分析工具包。
主要功能
- 模型转换与比较
- 运行精度对比
- 调试功能
可视化网络结构
检查中间层输出
比较不同运行时的输出差异 - 性能分析
层级时间分析
内存使用分析
吞吐量测试
使用此工具背景是,工作中遇到了跟上面实验不太一样的结果:使用FP16精度时,预测输出的结果 array 全是 0
- 验证 FP32 精度推理,看输出是否存在异常
polygraphy run /opt/inference_new.onnx \ # 运行指定的 ONNX 模型
--trt \ # 使用 TensorRT 后端进行推理
--validate \ # 启用验证模式
--trt-outputs mark all \ # 标记所有张量作为输出用于调试
--trt-min-shapes x:[1,3,32,32] \ # 设置动态尺寸的最小输入形状
--trt-opt-shapes x:[1,3,192,192] \ # 设置优化的输入形状
--trt-max-shapes x:[1,3,1472,1224] \ # 设置动态尺寸的最大输入形状
--save-results=/opt/workplace/Server/trt_out32.pkl \ # 保存推理结果到文件
--load-inputs /opt/workplace/Server/input_det.json # 从 JSON 文件加载输入数据
输出:没有异常
[I] trt-runner-N0-01/10/25-08:59:36 | Validating output: conv2d_213.tmp_0 (check_inf=True, check_nan=True)
[I] mean=-82.857, std-dev=28.73, var=825.41, median=-78.777, min=-186.95 at (0, 0, 0, 19), max=-21.878 at (0, 0, 25, 21), avg-magnitude=82.857, p90=-49.847, p95=-49.847, p99=-30.603
[I] PASSED | Output: conv2d_213.tmp_0 is valid
[I] trt-runner-N0-01/10/25-08:59:36 | Validating output: save_infer_model/scale_0.tmp_0 (check_inf=True, check_nan=True)
[I] mean=4.6964e-13, std-dev=1.0686e-11, var=1.1418e-22, median=6.1353e-35, min=0 at (0, 0, 0, 0), max=3.1524e-10 at (0, 0, 25, 21), avg-magnitude=4.6964e-13, p90=2.2495e-22, p95=2.2495e-22, p99=5.154e-14
[I] PASSED | Output: save_infer_model/scale_0.tmp_0 is valid
[I] PASSED | Output Validation
[I] PASSED | Runtime: 63.431s | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --validate --trt-outputs mark all --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --save-results=/opt/workplace/Server/trt_out32.pkl --load-inputs /opt/workplace/Server/input_det.json
- 验证 FP16 精度推理(加了 --fp16 选项),看输出是否存在异常
polygraphy run /opt/inference_new.onnx \
--trt \
--validate \
--trt-outputs mark all \
--trt-min-shapes x:[1,3,32,32] \
--trt-opt-shapes x:[1,3,192,192] \
--trt-max-shapes x:[1,3,1472,1224] \
--fp16 \ # 启用 FP16(半精度浮点数)模式
--save-results=/opt/workplace/Server/trt_out.pkl \
--load-inputs /opt/workplace/Server/input_det.json
输出:存在异常的 NaN、Inf
[I] trt-runner-N0-01/10/25-08:52:19 | Validating output: conv2d_213.tmp_0 (check_inf=True, check_nan=True)
[I] mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 3, 1), max=nan at (0, 0, 3, 1), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[E] NaN Detected | One or more NaNs were encountered in this output
[E] Inf Detected | One or more non-finite values were encountered in this output
[E] FAILED | Errors detected in output: conv2d_213.tmp_0
[I] trt-runner-N0-01/10/25-08:52:19 | Validating output: save_infer_model/scale_0.tmp_0 (check_inf=True, check_nan=True)
[I] mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 3, 1), max=nan at (0, 0, 3, 1), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[E] NaN Detected | One or more NaNs were encountered in this output
[E] Inf Detected | One or more non-finite values were encountered in this output
[E] FAILED | Errors detected in output: save_infer_model/scale_0.tmp_0
[E] FAILED | Output Validation
[E] FAILED | Runtime: 136.982s | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --validate --trt-outputs mark all --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --fp16 --save-results=/opt/workplace/Server/trt_out.pkl --load-inputs /opt/workplace/Server/input_det.json
- 对比 onnx、trt 的结果是否接近
该命令使用 Polygraphy 工具对同一模型进行 TensorRT 和 ONNX Runtime 推理对比,输入为动态形状并从指定的 JSON 文件加载。
最后,基于设定的相对误差(1e-4)和绝对误差(1e-3)对两者输出结果进行精度验证,帮助评估模型在不同引擎间的表现一致性
FP32 精度
polygraphy run /opt/inference_new.onnx \
--trt \
--onnxrt \
--trt-min-shapes x:[1,3,32,32] \
--trt-opt-shapes x:[1,3,192,192] \
--trt-max-shapes x:[1,3,1472,1224] \
--load-inputs /opt/workplace/Server/input_det.json \
--rtol 1e-4 \
--atol 1e-3
输出: Accuracy Summary | trt-runner-N0-01/10/25-09:15:34 vs. onnxrt-runner-N0-01/10/25-09:15:34 | Passed: 1/1 iterations | Pass Rate: 100.0% 在给定误差范围内,100%通过
[I] RUNNING | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --onnxrt --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --load-inputs /opt/workplace/Server/input_det.json --rtol 1e-4 --atol 1e-3
[I] Loading input data from /opt/workplace/Server/input_det.json
[I] trt-runner-N0-01/10/25-09:15:34 | Activating and starting inference
[I] Configuring with profiles:[
Profile 0:
{x [min=[1, 3, 32, 32], opt=[1, 3, 192, 192], max=[1, 3, 1472, 1224]]}
]
[I] Building engine with configuration:
Flags | []
Engine Capability | EngineCapability.DEFAULT
Memory Pools | [WORKSPACE: 7836.25 MiB, TACTIC_DRAM: 7836.25 MiB]
Tactic Sources | [CUBLAS, CUBLAS_LT, CUDNN, EDGE_MASK_CONVOLUTIONS, JIT_CONVOLUTIONS]
Profiling Verbosity | ProfilingVerbosity.DETAILED
Preview Features | [FASTER_DYNAMIC_SHAPES_0805, DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
[W] Profile kMAX values are not self-consistent. Add.12: dimensions not compatible for elementwise. Condition '==' violated: 78 != 77. Instruction: CHECK_EQUAL 78 77.
[I] Finished engine building in 111.443 seconds
[I] trt-runner-N0-01/10/25-09:15:34
---- Inference Input(s) ----
{x [dtype=float32, shape=(1, 3, 32, 32)]}
[I] trt-runner-N0-01/10/25-09:15:34
---- Inference Output(s) ----
{save_infer_model/scale_0.tmp_0 [dtype=float32, shape=(1, 1, 32, 32)]}
[I] trt-runner-N0-01/10/25-09:15:34 | Completed 1 iteration(s) in 7.983 ms | Average inference time: 7.983 ms.
[I] onnxrt-runner-N0-01/10/25-09:15:34 | Activating and starting inference
[I] Creating ONNX-Runtime Inference Session with providers: ['CPUExecutionProvider']
[I] onnxrt-runner-N0-01/10/25-09:15:34
---- Inference Input(s) ----
{x [dtype=float32, shape=(1, 3, 32, 32)]}
[I] onnxrt-runner-N0-01/10/25-09:15:34
---- Inference Output(s) ----
{save_infer_model/scale_0.tmp_0 [dtype=float32, shape=(1, 1, 32, 32)]}
[I] onnxrt-runner-N0-01/10/25-09:15:34 | Completed 1 iteration(s) in 43.47 ms | Average inference time: 43.47 ms.
[I] Accuracy Comparison | trt-runner-N0-01/10/25-09:15:34 vs. onnxrt-runner-N0-01/10/25-09:15:34
[I] Comparing Output: 'save_infer_model/scale_0.tmp_0' (dtype=float32, shape=(1, 1, 32, 32)) with 'save_infer_model/scale_0.tmp_0' (dtype=float32, shape=(1, 1, 32, 32))
[I] Tolerance: [abs=0.001, rel=0.0001] | Checking elemwise error
[W] onnxrt-runner-N0-01/10/25-09:15:34 | Output: save_infer_model/scale_0.tmp_0: Some values are 0. Will add a small epsilon quantity to these when computing relative difference. Note that this may cause some relative differences to be extremely high.
[I] trt-runner-N0-01/10/25-09:15:34: save_infer_model/scale_0.tmp_0 | Stats: mean=4.6963e-13, std-dev=1.0685e-11, var=1.1417e-22, median=6.135e-35, min=0 at (0, 0, 0, 0), max=3.1523e-10 at (0, 0, 25, 21), avg-magnitude=4.6963e-13, p90=2.2494e-22, p95=2.2494e-22, p99=5.1537e-14
[I] onnxrt-runner-N0-01/10/25-09:15:34: save_infer_model/scale_0.tmp_0 | Stats: mean=0, std-dev=0, var=0, median=0, min=0 at (0, 0, 0, 0), max=0 at (0, 0, 0, 0), avg-magnitude=0, p90=0, p95=0, p99=0
[I] Error Metrics: save_infer_model/scale_0.tmp_0
[I] Minimum Required Tolerance: elemwise error | [abs=3.1523e-10] OR [rel=1.4197e+06] (requirements may be lower if both abs/rel tolerances are set)
[I] Absolute Difference | Stats: mean=4.6963e-13, std-dev=1.0685e-11, var=1.1417e-22, median=6.135e-35, min=0 at (0, 0, 0, 0), max=3.1523e-10 at (0, 0, 25, 21), avg-magnitude=4.6963e-13, p90=2.2494e-22, p95=2.2494e-22, p99=5.1537e-14
[I] Relative Difference | Stats: mean=2115, std-dev=48122, var=2.3157e+09, median=2.7629e-19, min=0 at (0, 0, 0, 0), max=1.4197e+06 at (0, 0, 25, 21), avg-magnitude=2115, p90=1.013e-06, p95=1.013e-06, p99=232.1
[I] PASSED | Output: 'save_infer_model/scale_0.tmp_0' | Difference is within tolerance (rel=0.0001, abs=0.001)
[I] PASSED | All outputs matched | Outputs: ['save_infer_model/scale_0.tmp_0']
[I] Accuracy Summary | trt-runner-N0-01/10/25-09:15:34 vs. onnxrt-runner-N0-01/10/25-09:15:34 | Passed: 1/1 iterations | Pass Rate: 100.0%
[I] PASSED | Runtime: 117.081s | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --onnxrt --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --load-inputs /opt/workplace/Server/input_det.json --rtol 1e-4 --atol 1e-3
FP16 精度
polygraphy run /opt/inference_new.onnx \
--trt \
--onnxrt \
--trt-min-shapes x:[1,3,32,32] \
--trt-opt-shapes x:[1,3,192,192] \
--trt-max-shapes x:[1,3,1472,1224] \
--load-inputs /opt/workplace/Server/input_det.json \
--rtol 1e-4 \
--atol 1e-3 \
--fp16 --validate
输出:FAILED | Output Validation
[I] RUNNING | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --onnxrt --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --load-inputs /opt/workplace/Server/input_det.json --rtol 1e-4 --atol 1e-3 --fp16 --validate
[I] Loading input data from /opt/workplace/Server/input_det.json
[I] trt-runner-N0-01/10/25-09:19:49 | Activating and starting inference
[I] Configuring with profiles:[
Profile 0:
{x [min=[1, 3, 32, 32], opt=[1, 3, 192, 192], max=[1, 3, 1472, 1224]]}
]
[I] Building engine with configuration:
Flags | [FP16]
Engine Capability | EngineCapability.DEFAULT
Memory Pools | [WORKSPACE: 7836.25 MiB, TACTIC_DRAM: 7836.25 MiB]
Tactic Sources | [CUBLAS, CUBLAS_LT, CUDNN, EDGE_MASK_CONVOLUTIONS, JIT_CONVOLUTIONS]
Profiling Verbosity | ProfilingVerbosity.DETAILED
Preview Features | [FASTER_DYNAMIC_SHAPES_0805, DISABLE_EXTERNAL_TACTIC_SOURCES_FOR_CORE_0805]
[W] Profile kMAX values are not self-consistent. Add.12: dimensions not compatible for elementwise. Condition '==' violated: 78 != 77. Instruction: CHECK_EQUAL 78 77.
[W] TensorRT encountered issues when converting weights between types and that could affect accuracy.
[W] If this is not the desired behavior, please modify the weights or retrain with regularization to adjust the magnitude of the weights.
[W] Check verbose logs for the list of affected weights.
[W] - 75 weights are affected by this issue: Detected subnormal FP16 values.
[W] - 147 weights are affected by this issue: Detected values less than smallest positive FP16 subnormal value and converted them to the FP16 minimum subnormalized value.
[I] Finished engine building in 200.280 seconds
[I] trt-runner-N0-01/10/25-09:19:49
---- Inference Input(s) ----
{x [dtype=float32, shape=(1, 3, 32, 32)]}
[I] trt-runner-N0-01/10/25-09:19:49
---- Inference Output(s) ----
{save_infer_model/scale_0.tmp_0 [dtype=float32, shape=(1, 1, 32, 32)]}
[I] trt-runner-N0-01/10/25-09:19:49 | Completed 1 iteration(s) in 5.321 ms | Average inference time: 5.321 ms.
[I] onnxrt-runner-N0-01/10/25-09:19:49 | Activating and starting inference
[I] Creating ONNX-Runtime Inference Session with providers: ['CPUExecutionProvider']
[I] onnxrt-runner-N0-01/10/25-09:19:49
---- Inference Input(s) ----
{x [dtype=float32, shape=(1, 3, 32, 32)]}
[I] onnxrt-runner-N0-01/10/25-09:19:49
---- Inference Output(s) ----
{save_infer_model/scale_0.tmp_0 [dtype=float32, shape=(1, 1, 32, 32)]}
[I] onnxrt-runner-N0-01/10/25-09:19:49 | Completed 1 iteration(s) in 40.31 ms | Average inference time: 40.31 ms.
[I] Accuracy Comparison | trt-runner-N0-01/10/25-09:19:49 vs. onnxrt-runner-N0-01/10/25-09:19:49
[I] Comparing Output: 'save_infer_model/scale_0.tmp_0' (dtype=float32, shape=(1, 1, 32, 32)) with 'save_infer_model/scale_0.tmp_0' (dtype=float32, shape=(1, 1, 32, 32))
[I] Tolerance: [abs=0.001, rel=0.0001] | Checking elemwise error
[W] onnxrt-runner-N0-01/10/25-09:19:49 | Output: save_infer_model/scale_0.tmp_0: Some values are 0. Will add a small epsilon quantity to these when computing relative difference. Note that this may cause some relative differences to be extremely high.
[I] trt-runner-N0-01/10/25-09:19:49: save_infer_model/scale_0.tmp_0 | Stats: mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 0, 0), max=nan at (0, 0, 0, 0), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[I]
[I] onnxrt-runner-N0-01/10/25-09:19:49: save_infer_model/scale_0.tmp_0 | Stats: mean=0, std-dev=0, var=0, median=0, min=0 at (0, 0, 0, 0), max=0 at (0, 0, 0, 0), avg-magnitude=0, p90=0, p95=0, p99=0
[I]
[I] Error Metrics: save_infer_model/scale_0.tmp_0
[I] Minimum Required Tolerance: elemwise error | [abs=nan] OR [rel=nan] (requirements may be lower if both abs/rel tolerances are set)
[I] Absolute Difference | Stats: mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 0, 0), max=nan at (0, 0, 0, 0), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[I]
[I] Relative Difference | Stats: mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 0, 0), max=nan at (0, 0, 0, 0), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[I]
[E] FAILED | Output: 'save_infer_model/scale_0.tmp_0' | Difference exceeds tolerance (rel=0.0001, abs=0.001)
[E] FAILED | Mismatched outputs: ['save_infer_model/scale_0.tmp_0']
[E] Accuracy Summary | trt-runner-N0-01/10/25-09:19:49 vs. onnxrt-runner-N0-01/10/25-09:19:49 | Passed: 0/1 iterations | Pass Rate: 0.0%
[I] Output Validation | Runners: ['trt-runner-N0-01/10/25-09:19:49', 'onnxrt-runner-N0-01/10/25-09:19:49']
[I] trt-runner-N0-01/10/25-09:19:49 | Validating output: save_infer_model/scale_0.tmp_0 (check_inf=True, check_nan=True)
[I] mean=nan, std-dev=nan, var=nan, median=nan, min=nan at (0, 0, 0, 0), max=nan at (0, 0, 0, 0), avg-magnitude=nan, p90=nan, p95=nan, p99=nan
[E] NaN Detected | One or more NaNs were encountered in this output
[I] Note: Use -vv or set logging verbosity to EXTRA_VERBOSE to display locations of NaNs
[E] Inf Detected | One or more non-finite values were encountered in this output
[I] Note: Use -vv or set logging verbosity to EXTRA_VERBOSE to display non-finite values
[E] FAILED | Errors detected in output: save_infer_model/scale_0.tmp_0
[I] onnxrt-runner-N0-01/10/25-09:19:49 | Validating output: save_infer_model/scale_0.tmp_0 (check_inf=True, check_nan=True)
[I] mean=0, std-dev=0, var=0, median=0, min=0 at (0, 0, 0, 0), max=0 at (0, 0, 0, 0), avg-magnitude=0, p90=0, p95=0, p99=0
[I] PASSED | Output: save_infer_model/scale_0.tmp_0 is valid
[E] FAILED | Output Validation
[E] FAILED | Runtime: 205.684s | Command: /root/miniconda3/envs/ocr/bin/polygraphy run /opt/inference_new.onnx --trt --onnxrt --trt-min-shapes x:[1,3,32,32] --trt-opt-shapes x:[1,3,192,192] --trt-max-shapes x:[1,3,1472,1224] --load-inputs /opt/workplace/Server/input_det.json --rtol 1e-4 --atol 1e-3 --fp16 --validate
推测:模型在 FP16 精度下存在数值溢出问题,导致输出异常
后续可能的方向:
- 混合精度训练 AMP
- 添加 Clip 操作:在激活层前后插入 Clip 操作,避免数值溢出
- 量化感知训练 (QAT, Quantization-Aware Training)
量化感知训练会在训练过程中模拟 FP16 的计算行为,同时加入量化误差的约束,使模型更适合低精度推理 - 正则化
模型中较大的权重或过小的权重可能在 FP16 下失效。正则化,可以使权重分布更适合 FP16 表达范围loss = original_loss + lambda_l2 * sum(p.pow(2).sum() for p in model.parameters()) - 权重剪枝
from torch.nn.utils import prune
4. 模型可视化
下载 resnet50 onnx模型 https://download.onnxruntime.ai/onnx/models/resnet50.tar.gz
1. Nsight Deep Learning Designer
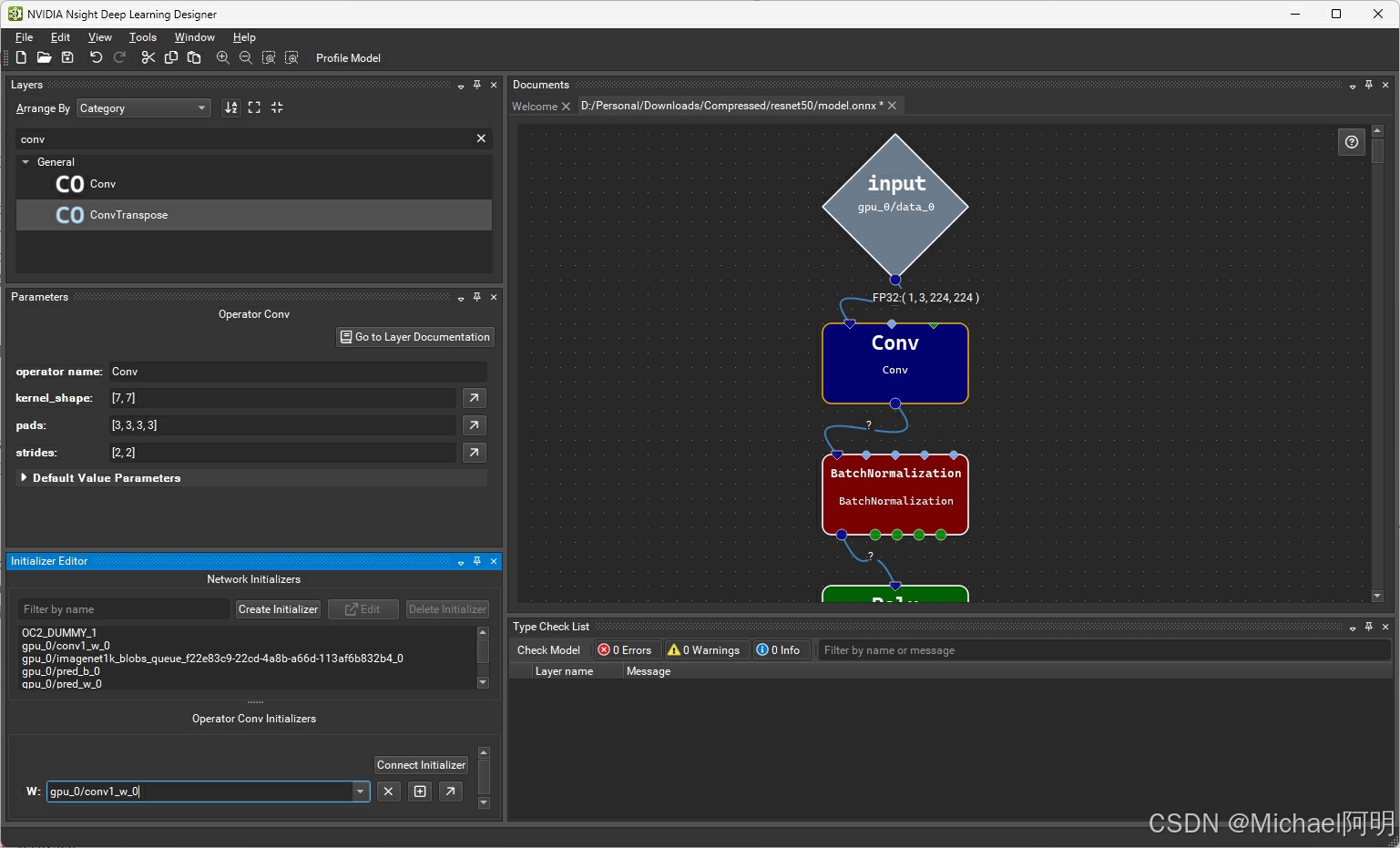
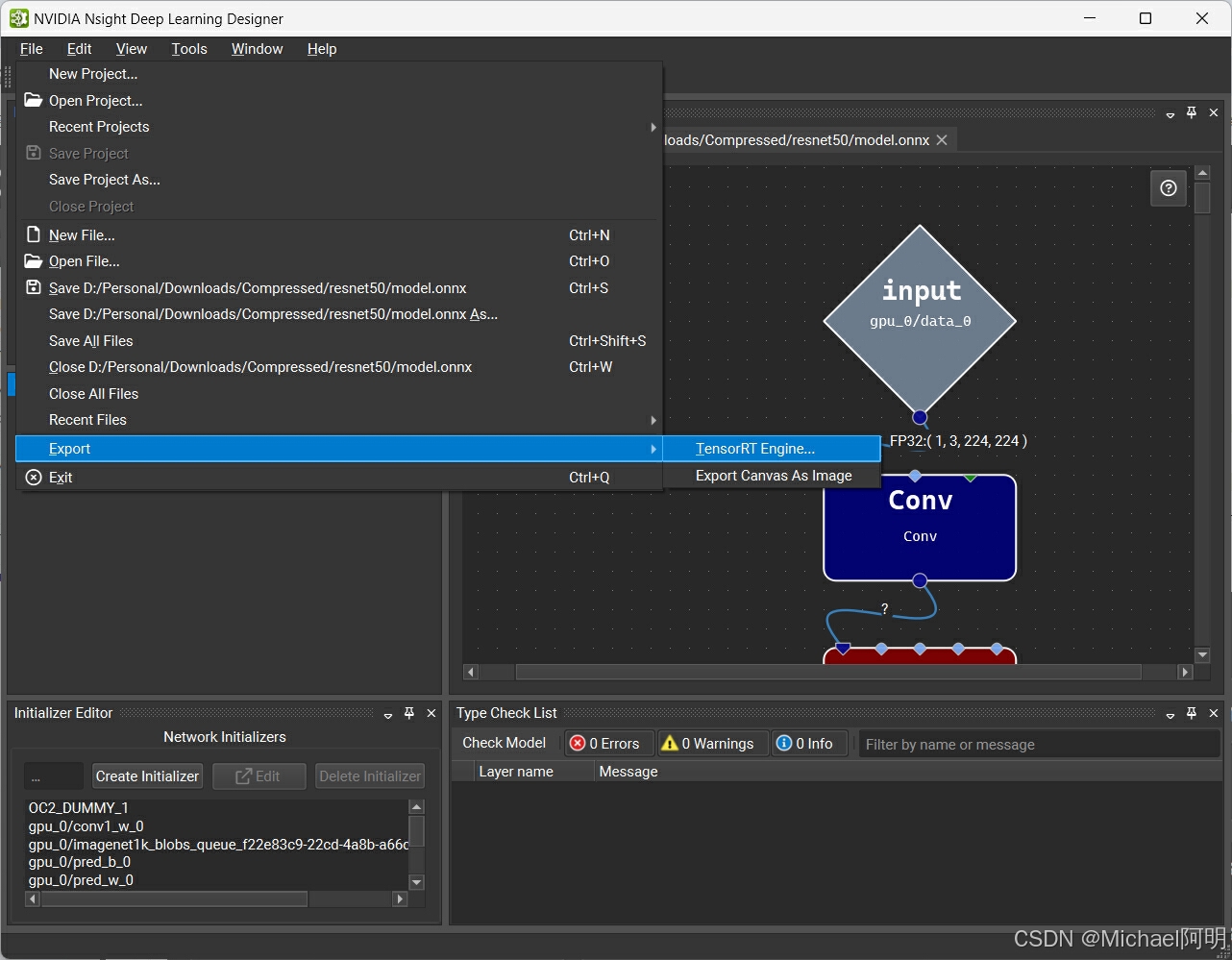
导出 trt engine
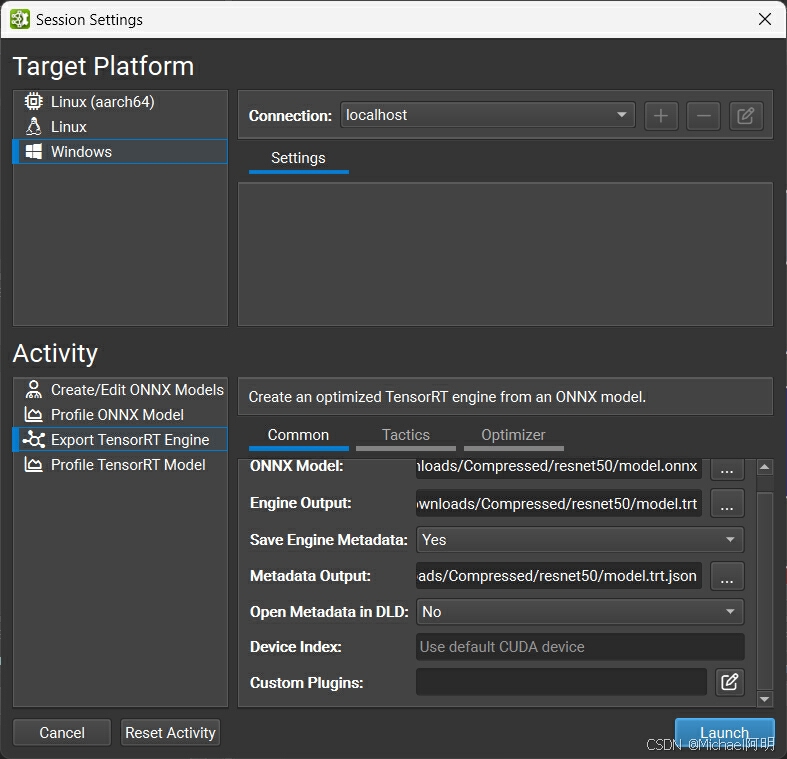
还可以做性能测试
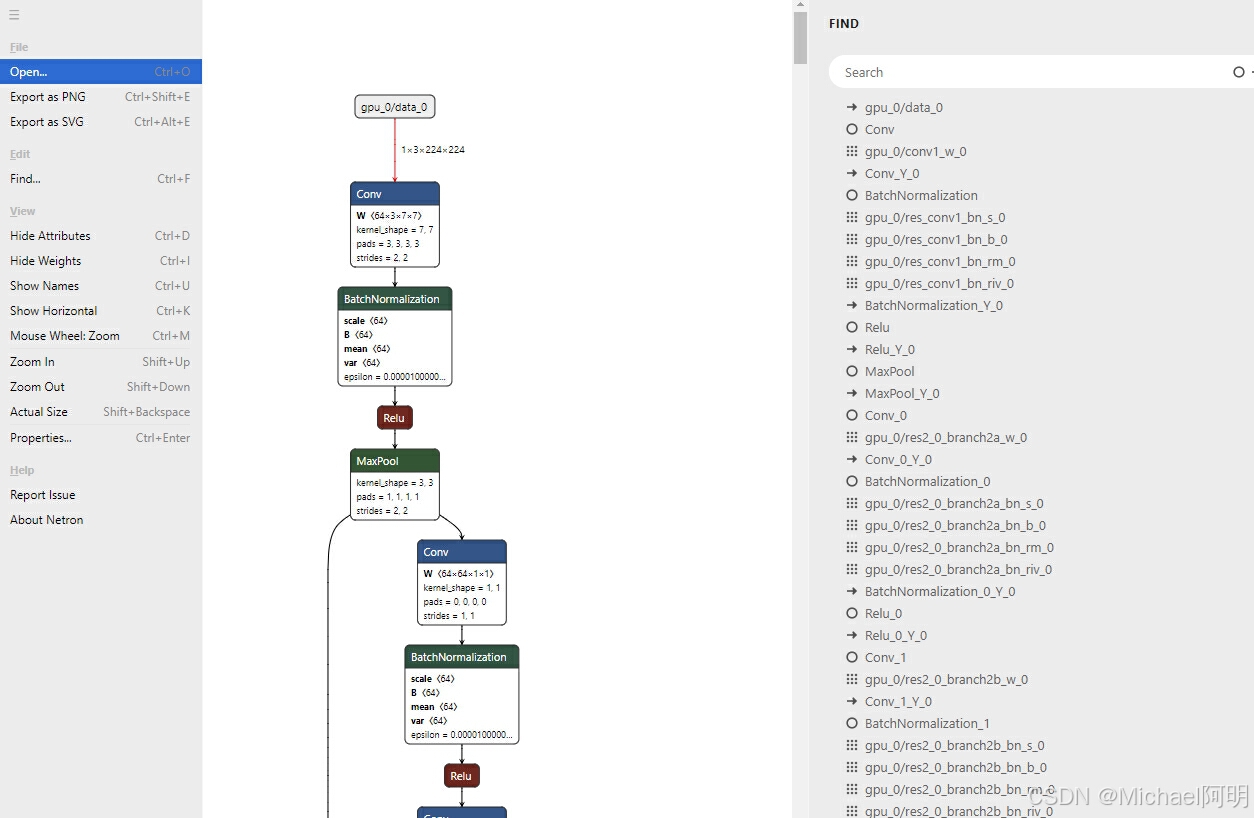
2. netron
模型可视化:https:/netron.app/
5. 参考
TRT cookbook https://github.com/NVIDIA/trt-samples-for-hackathon-cn/tree/master/cookbook
Paddle Inference 适配 TensorRT https:/www.paddlepaddle.org.cn/inference/v2.6/guides/nv_gpu_infer/gpu_trt_infer.html
Polygraphy 工具 https:/github.com/NVIDIA/TensorRT/tree/main/tools/Polygraphy/examples
polygraphy模型调试器的使用 https:/blog.csdn.net/yitiaoxiaolu/article/details/136413877
Polygraphy逐层对比onnx和tensorrt模型的输出 https:/zhuanlan.zhihu.com/p/436017991
6. 环境配置清单
环境 python 3.11.5,cuda 12.6
# pip list
Package Version
--------------------------------- ------------------
absl-py 2.1.0
accelerate 0.30.1
aiofiles 23.2.1
aiohttp 3.9.5
aiosignal 1.3.1
altair 5.3.0
annotated-types 0.6.0
antlr4-python3-runtime 4.9.3
anyio 4.3.0
appdirs 1.4.4
apted 1.0.3
astor 0.8.1
asttokens 2.4.1
attrdict 2.0.1
attrs 23.2.0
Babel 2.14.0
backoff 2.2.1
bce-python-sdk 0.9.6
beautifulsoup4 4.12.3
bitarray 2.9.2
bitstring 4.2.3
black 21.4b2
blinker 1.7.0
boto3 1.34.102
botocore 1.34.105
Brotli 1.1.0
cachetools 5.3.3
catalogue 2.0.10
certifi 2024.2.2
cffi 1.16.0
chardet 5.2.0
charset-normalizer 3.3.2
click 8.1.7
cloudpickle 3.0.0
cnocr 2.3.0.2
cnstd 1.2.3.6
colored 2.2.4
coloredlogs 15.0.1
conda-pack 0.8.0
contourpy 1.2.1
cryptography 42.0.5
cssselect 1.2.0
cssselect2 0.2.1
cssutils 2.10.2
cuda-python 12.6.2.post1
cycler 0.12.1
Cython 3.0.10
dataclasses-json 0.6.4
dataclasses-json-speakeasy 0.5.11
datasets 2.19.1
datrie 0.8.2
decorator 5.1.1
deepdoctection 0.32
defusedxml 0.7.1
Deprecated 1.2.14
detectron2 0.5
dill 0.3.8
Distance 0.1.3
dnspython 2.6.1
docker-pycreds 0.4.0
easyocr 1.7.1
effdet 0.4.1
email_validator 2.2.0
emoji 2.11.0
et-xmlfile 1.1.0
evaluate 0.4.2
executing 2.0.1
fastapi 0.111.1
fastapi-cli 0.0.4
fasttext 0.9.2
filelock 3.13.4
filetype 1.2.0
fire 0.6.0
Flask 3.0.3
flask-babel 4.0.0
flatbuffers 24.3.25
fonttools 4.17.1
frontend 0.0.3
frozenlist 1.4.1
fsspec 2024.3.1
ftfy 6.2.0
future 1.0.0
fvcore 0.1.5.post20221221
gitdb 4.0.11
GitPython 3.1.43
greenlet 3.0.3
grpcio 1.63.0
h11 0.14.0
h5py 3.11.0
hanziconv 0.3.2
html5lib 1.1
httpcore 1.0.5
httptools 0.6.1
httpx 0.27.0
huggingface-hub 0.23.4
humanfriendly 10.0
hydra-core 1.3.2
idna 3.7
imageio 2.34.0
imgaug 0.4.0
importlib_metadata 7.1.0
iopath 0.1.9
ipdb 0.13.13
ipython 8.26.0
itsdangerous 2.2.0
jdeskew 0.2.2
jedi 0.19.1
jieba 0.42.1
Jinja2 3.1.3
jmespath 1.0.1
joblib 1.4.0
jsonlines 3.1.0
jsonpatch 1.33
jsonpath-python 1.0.6
jsonpointer 3.0.0
jsonschema 4.22.0
jsonschema-specifications 2023.12.1
kiwisolver 1.4.5
langchain 0.0.351
langchain-community 0.0.20
langchain-core 0.1.23
langdetect 1.0.9
langsmith 0.0.87
layoutparser 0.3.4
lazy-imports 0.3.1
lazy_loader 0.4
Levenshtein 0.25.1
lightning-utilities 0.11.2
lmdb 1.4.1
loguru 0.7.2
lxml 5.2.1
Mako 1.3.8
Markdown 3.6
markdown-it-py 3.0.0
marker-pdf 0.2.5
MarkupSafe 2.1.5
marshmallow 3.21.1
matplotlib 3.8.4
matplotlib-inline 0.1.7
mdurl 0.1.2
mock 4.0.3
mplcursors 0.5.3
mpmath 1.3.0
msg-parser 1.2.0
msgpack 1.0.8
multidict 6.0.5
multiprocess 0.70.16
munkres 1.1.4
mypy-extensions 1.0.0
networkx 3.3
ninja 1.11.1.1
nltk 3.8.1
numpy 1.26.4
nvidia-cublas-cu12 12.3.4.1
nvidia-cuda-cupti-cu12 12.3.101
nvidia-cuda-nvrtc-cu12 12.3.107
nvidia-cuda-runtime-cu12 12.3.101
nvidia-cufft-cu12 11.2.1.3
nvidia-curand-cu12 10.3.5.147
nvidia-cusolver-cu12 11.6.1.9
nvidia-cusparse-cu12 12.3.1.170
nvidia-nccl-cu12 2.19.3
nvidia-nvjitlink-cu12 12.4.127
nvidia-nvtx-cu12 12.4.127
olefile 0.47
omegaconf 2.3.0
onnx 1.16.0
onnxruntime-gpu 1.18.1
opencv-contrib-python 4.6.0.66
opencv-python 4.9.0.80
opencv-python-headless 4.9.0.80
openpyxl 3.1.2
opt-einsum 3.3.0
optimum 1.19.2
packaging 23.2
paddle2onnx 1.3.1
paddleocr 2.7.3
paddlepaddle 2.6.1
paddlepaddle-gpu 2.6.1.post120
pandas 2.2.2
parsee-pdf-reader 0.1.5.8
parso 0.8.4
pathspec 0.12.1
pdf2docx 0.5.8
pdf2image 1.16.3
pdfminer.six 20231228
pdfplumber 0.11.0
pdftext 0.3.7
pexpect 4.9.0
pikepdf 8.15.1
pillow 10.3.0
pillow_heif 0.16.0
pip 23.2.1
pix2text 1.1.0.3
platformdirs 4.2.2
Polygon3 3.0.9.1
polygraphy 0.49.14
portalocker 2.8.2
premailer 3.10.0
prompt_toolkit 3.0.47
protobuf 4.25.3
psutil 5.9.8
ptyprocess 0.7.0
pudb 2024.1.2
pure_eval 0.2.3
pyarrow 16.1.0
pyarrow-hotfix 0.6
pybind11 2.12.0
pyclipper 1.3.0.post5
pycocotools 2.0.7
pycparser 2.22
pycryptodome 3.20.0
pycryptodome-test-vectors 1.0.14
pycryptodomex 3.20.0
pycuda 2024.1.2
pydantic 2.7.1
pydantic_core 2.18.2
pydantic-settings 2.2.1
pydeck 0.9.1
pydot 2.0.0
pydyf 0.10.0
Pygments 2.18.0
PyMuPDF 1.23.18
PyMuPDFb 1.23.9
pypandoc 1.13
pyparsing 3.1.2
pypdf 3.17.4
PyPDF2 3.0.1
pypdfium2 4.29.0
pyphen 0.15.0
pyspellchecker 0.8.1
pytesseract 0.3.10
python-bidi 0.4.2
python-dateutil 2.9.0.post0
python-doctr 0.8.1
python-docx 1.1.0
python-dotenv 1.0.1
python-iso639 2024.2.7
python-Levenshtein 0.25.1
python-magic 0.4.27
python-multipart 0.0.9
python-pptx 0.6.23
pytils 0.4.1
pytools 2024.1.21
pytorch-lightning 2.2.4
pytz 2024.1
PyYAML 6.0.1
pyzmq 26.0.3
rapidfuzz 3.8.1
rarfile 4.2
ray 2.22.0
referencing 0.35.1
regex 2024.5.15
requests 2.31.0
rich 13.7.1
rpds-py 0.18.1
ruamel.yaml 0.18.6
ruamel.yaml.clib 0.2.8
s3transfer 0.10.1
safetensors 0.4.3
scikit-image 0.23.1
scikit-learn 1.4.2
scipy 1.13.0
seaborn 0.13.2
sentencepiece 0.2.0
sentry-sdk 2.2.0
setproctitle 1.3.3
setuptools 68.0.0
shapely 2.0.5
shellingham 1.5.4
six 1.16.0
smmap 5.0.1
sniffio 1.3.1
soupsieve 2.5
SQLAlchemy 2.0.31
stack-data 0.6.3
starlette 0.37.2
streamlit 1.34.0
streamlit-drawable-canvas-jsretry 0.9.3
StrEnum 0.4.15
surya-ocr 0.4.14
sympy 1.12
tabulate 0.9.0
tenacity 8.3.0
tensorboard 2.16.2
tensorboard-data-server 0.7.2
tensorrt 8.6.1
tensorrt-bindings 8.6.1
tensorrt-libs 8.6.1
termcolor 2.4.0
texify 0.1.8
threadpoolctl 3.5.0
tifffile 2024.4.18
tiktoken 0.6.0
timm 0.9.16
tinycss2 1.3.0
tokenizers 0.19.1
toml 0.10.2
tools 0.1.9
toolz 0.12.1
torchmetrics 1.4.0.post0
tornado 6.4
tqdm 4.66.4
traitlets 5.14.3
transformers 4.42.3
triton 2.3.1
typer 0.12.3
typing_extensions 4.11.0
typing-inspect 0.9.0
tzdata 2024.1
unicodedata2 15.1.0
Unidecode 1.3.8
unstructured 0.13.2
unstructured-client 0.18.0
unstructured-inference 0.7.25
unstructured.pytesseract 0.3.12
urllib3 2.2.1
urwid 2.6.15
urwid_readline 0.14
uvicorn 0.29.0
uvloop 0.19.0
visualdl 2.5.3
wandb 0.17.0
watchdog 3.0.0
watchfiles 0.22.0
wcwidth 0.2.13
weasyprint 62.1
webencodings 0.5.1
websockets 12.0
Werkzeug 3.0.2
wheel 0.41.2
wrapt 1.16.0
xgboost 2.0.3
xlrd 2.0.1
XlsxWriter 3.2.0
xxhash 3.4.1
yacs 0.1.8
yarl 1.9.4
zipp 3.18.1
zopfli 0.2.3


















 1655
1655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











