







 本文详细介绍了AlexNet网络结构,包括5层卷积和3层全连接,以及在LeNet基础上的改进,如ReLU激活函数、数据归一化和Dropout技术。此外,还提供了AlexNet的TensorFlow2.x实现,并展示了用于猫狗图片分类的训练过程。
本文详细介绍了AlexNet网络结构,包括5层卷积和3层全连接,以及在LeNet基础上的改进,如ReLU激活函数、数据归一化和Dropout技术。此外,还提供了AlexNet的TensorFlow2.x实现,并展示了用于猫狗图片分类的训练过程。
最近在积攒粉丝500,大家帮帮忙,动动小手指关注、点赞、收藏…🙏🙏🙏🙏🙏🙏
第一个典型的CNN是LeNet5网络结构,但是第一个引起大家注意的网络却是AlexNet,也就是文章《ImageNet Classification with Deep Convolutional Neural Networks》介绍的网络结构,它是2012年ImageNet挑战赛的冠军。
一、AlexNet网络结构
网络总共的层数为8层,5层卷积,3层全连接层,输出1000个类别;使用2个GPU训练,结构如下:

1.1 卷积网络提取特征
卷积神经网络的第一部分就是使用卷积层去提取特征,网络结构由卷积层、池化层堆叠而成。
1.1.1 卷积层C1

该层的处理流程是:卷积–>ReLU–>归一化。
(1)Conv:卷积层输入3x224x224的图像,卷积核3x96x11x11,步长stride=4,填充pad=0; 输出特征图96x55x55;
(2)Relu:经过激活函数ReLu;
(3)BN:局部归一化LRN (Local Response Normalized),LRN后来被证实用处不大;这里复现时使用BN层代替;
1.1.2 卷积层C2
该层的处理流程是:卷积–>ReLU–>归一化–>池化。
(1)Conv:卷积层输入96x55x55,卷积核96x256x5x5,步长stride=1,填充pad=2; 输出256x55x55;
(2)Relu:经过激活函数ReLu;
(3)BN:批量归一化BN(Batch Normalization);
(4)Pooling:池化pool_size=(3, 3), stride=2, pad=0,输出256x27x27;
1.1.3 卷积层C3
该层的处理流程是:卷积–>ReLU–>归一化–>池化。
(1)Conv:卷积层输入256x27x27,卷积核256x384x3x3,步长stride=1,填充pad=2; 输出192x27x27;
(2)Relu:经过激活函数ReLu;
(3)BN:批量归一化BN(Batch Normalization);
(4)Pooling:池化pool_size=(3, 3), stride=2, pad=0,输出256x13x13;
1.1.4 卷积层C4,C5
该层的处理流程是:卷积–>ReLU–>卷积–>ReLU。
(1)Conv:卷积层输入384x13x13,卷积核384x384x3x3,步长stride=1,填充pad=1; 输出384x13x13;
(2)Relu:经过激活函数ReLu;
(3)Conv:卷积层输入384x13x13,卷积核384x256x3x3,步长stride=1,填充pad=1; 输出256x13x13;
(4)Relu:经过激活函数ReLu;
1.2 全连接层对特征分类
以上是C1-C5是输入图像,通过卷积神经网络提取特征,得到大小为13x13的256特征图;
根据卷积神经网络图像分类思想(卷积神经网络 = 卷积提取特征 + 全连接分类),接下来把256个特征图送入全连接分类器,得到最终的分类结果。
1.2.1 全连接层FC6
该层的处理流程是:池化–>卷积–>ReLU–>归一化。
PS:这里比较特殊,使用卷积层替换了全连接层,节省了计算量。
(1)Pooling:池化pool_size=(3, 3), stride=2, pad=0,输出256x6x6;
(2)Conv:卷积层输入256x6x6,卷积核256x2048x3x3,步长stride=1,填充pad=1; 输出2048x1x1;
(3)Relu:经过激活函数ReLu;
(4)BN:批量归一化BN(Batch Normalization);
(5)展平:把(2048, 1, 1)展平成(2048,)
1.2.3 全连接层FC7,FC8
该层的处理流程是:Dropout-> FC7->Dropout->FC8->softmax。
(1)Dropout:抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元;
(2)全连接:输入2048,激活函数sigmoid,输出2048.
(3)全连接:输入2048,激活函数sigmoid,输出1000(类别数,ImageNet挑战赛的输出书1000类);
(4)softmax:最后经过softmax把输出转成概率。
1.3 网络结构代码实现
使用的是tensorflow2.x的类继承编码格式,AlexNet网络结构的代码如下:
import tensorflow as tf
from tensorflow.keras import layers
class ConvBA(layers.Layer):
""" Conv->relu->bn """
def __init__(self, filters, kernel_size, strides=1, padding='valid'):
super(ConvBA, self).__init__()
self.conv1 = layers.Conv2D(filters, kernel_size, strides=strides, padding=padding, activation="relu")
self.bn1 = layers.BatchNormalization()
def call(self, x):
x = self.conv1(x)
x = self.bn1(x)
return x
class AlexNet(tf.keras.Model):
def __init__(self, num_classes=10):
super(AlexNet, self).__init__()
# 1. 卷积提取特征
# self.conv1 = ConvBA(48, (11, 11), strides=4, padding="same") # 原本是步长4
self.conv1 = ConvBA(48, (11, 11), strides=2, padding="same") # 我为了适应输入112,改为2
self.conv2 = ConvBA(128, (5, 5), strides=1, padding="same")
self.pool1 = layers.MaxPool2D(pool_size=(3, 3), strides=2, padding='valid')
self.conv3 = ConvBA(192, (3, 3), strides=1, padding='same')
self.pool2 = layers.MaxPool2D(pool_size=(3, 3), strides=2, padding='valid')
self.conv4 = ConvBA(192, (3, 3), strides=1, padding='same')
self.conv5 = ConvBA(128, (3, 3), strides=1, padding='same')
self.pool3 = layers.MaxPool2D(pool_size=(3, 3), strides=2, padding='valid')
# 2. 分类(dense->Dropout->dense->Dropout->dense->softmax)
self.flatten = layers.Flatten()
self.fc0 = layers.Dense(2048, activation="sigmoid", use_bias=False)
self.drop1 = layers.Dropout(0.5)
self.fc1 = layers.Dense(1024, activation="sigmoid", use_bias=False)
self.drop2 = layers.Dropout(0.5)
self.fc2 = layers.Dense(num_classes, activation="sigmoid", use_bias=False)
self.softmax = layers.Softmax()
def call(self, x, training=False):
"""" 输入X -> 原来(batch,224,224,3)
实验我输入图像112*112
"""
# 提取特征,这里只是模拟AlexNet原来的一半
x = self.conv1(x) # 96*55*55
x = self.conv2(x)
x = self.pool1(x) # 256*27*27
x = self.conv3(x)
x = self.pool2(x) # 384*13*13
x = self.conv4(x) # 384*13*13
x = self.conv5(x) # 256*13*13
x = self.pool3(x) # 256*6*6
# 分类
x = self.flatten(x) # 展平
x = self.fc0(x) # 2048
if training:
x = self.drop1(x)
x = self.fc1(x) # 1024(这一层原文是2048,我改为了1024)
if training:
x = self.drop1(x)
x = self.fc2(x) # 输出类别数个数据
x = self.softmax(x) # 转为概率
return x
二、AlexNet的创新点
这个网络也是基于LeNet基础上进行改进优化的,首次运用在大规模图像分类上,取得惊人的效果。其在LeNet基础上改进有如下几点。
2.1 激活函数ReLu
AlexNet在卷积层上,改进的激活函数,由sigmoid/tanh改为ReLU。
2011年Yoshua Bengio等人提出ReLU激活函数,ReLU函数是目前比较火的一个激活函数。
函数公式:f(x) = max(0, x), 函数图像如下:
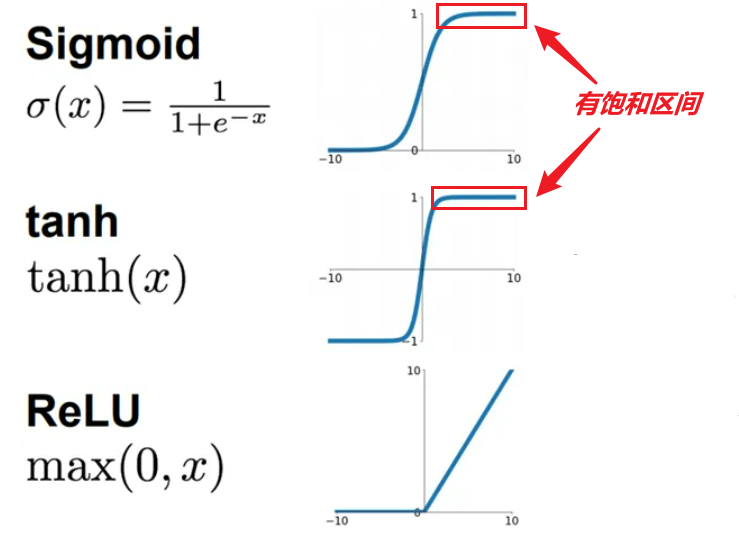
ReLU有效性体现:
(1)Relu函数缓解解了梯度消失问题;
(2)相比sigmoid、tanh函数计算量更少;
(3)训练时网络收敛更快;
2.2 数据归一化
在神经网络中,我们用激活函数将神经元的输出做一个非线性映射,但是tanh和sigmoid这些传统的激活函数的值域都是有范围的,但是ReLU激活函数得到的值域没有一个区间,所以要对ReLU得到的结果进行归一化。
再AlexNet中首次使用了归一化层(Local Response Normalization,局部归一化),但是局部归一化后来被证实用处不大,取而代之的时BN层(Batch normalization批量归一化)。2015年提出的Batch normalization,是一个用于优化训练神经网络的技巧。

BN层的优点很多,如下:
- 训练的更快;
- 容忍更高的学习率(learning rate);
- 让权重更容易初始化;
- 更好的支持创建深层的神经网络;
- 防止梯度消失或梯度爆炸等问题;
2.3 全连接层前使用Dropout
AlexNet网络在全连接层之前使用了Dropout(一种有效解决过拟合的方法),来解决训练是出现过拟合Overfitting问题。
Overfitting 也被称为过度学习,过度拟合,它是机器学习中常见的问题。
如下:数据有两个类别(蓝类、红类)。左图是训练,训练得到两个分割曲线;右图是预测;

现在预测3堆数据,分别是黄色(蓝类)、紫色(蓝类)、橙色(红类);图上看得出,预测黑色分割曲线准确率更高更好;得到绿色的分割曲线是因为训练过拟合了,过拟合表现在训练集上精度很高,但是在测试集(应用预测)上精度差。
Dropout的原理:过拟合意味着网络记住了训练样本,而打破网络固定的工作方式,就有可能打破这种不好的记忆;所以我们可以再网络训练时,在全连接层随机的断开某些神经元的连接或者不激活某些神经元,来达到抑制过拟合作用。
三、Alexnet代码实现猫狗图片分类
3.1 数据集介绍
数据集目录如下:

训练集每个类别有3000张、验证集每类有600张;图片大致如下:


3.2 数据集读取
定义基本函数:
# myreaddata.py
import random
import pathlib
"""
将所有数据存放在同一目录下,
# 然后将不同类别的图片分别地存放在各自的类别子目录下
"""
def get_all_image_paths(image_dir):
'''
获取所有图片路径,例如 ['flower_photos\\sunflowers\\4895721242_89014e723c_n.jpg', ...] '''
data_path = pathlib.Path(image_dir)
paths = list(data_path.glob('*/*')) # 图片全路径
paths = [str(p) for p in paths]
# random.shuffle(paths)
return paths
def get_label_and_index(image_dir):
'''获取类别名称及其数字表示,例如
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
{'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}
'''
data_path = pathlib.Path(image_dir)
label_names = sorted(item.name for item in data_path.glob('*/') if item.is_dir())
label_index = dict((name,index) for index,name in enumerate(label_names))
return label_names, label_index
tensorflow2.x的格式读取数据集:
# data_manager.py
import tensorflow as tf
from data_process.myreaddata import *
def process_image(fpath, label):
""" 图片预处理 """
image = tf.io.read_file(fpath) # 读取图像
image = tf.image.decode_jpeg(image,channels=3) # jpg图像解码
image = tf.image.resize(image, [112, 112]) # 原始图片大重设为(x, x), AlexNet的输入是224X224
label = tf.one_hot(label, depth=2) # 标签转成onehot格式,这里实验是标签2个类别数据
return image, label
def get_dataset(image_dir, is_shuffle=False, batch_size=64):
# 获取所有图片路径
image_paths = get_all_image_paths(image_dir)
_, label_index = get_label_and_index(image_dir)
# 每个图片路径名->数字标签
image_labels = [label_index[pathlib.Path(path).parent.name] for path in image_paths]
# tensorflow接口创建数据集读取
ds = tf.data.Dataset.from_tensor_slices((image_paths, image_labels))
ds = ds.map(process_image)
if is_shuffle:
ds = ds.shuffle(buffer_size=len(image_paths))
ds = ds.batch(batch_size)
return ds
3.2 训练模型代码
import os
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras import layers,losses, metrics
from data_process.data_manager import get_dataset
from network.alexnet import AlexNet
class TrainModel():
def __init__(self, lr=0.01):
self.model = AlexNet(num_classes=2) # 定义网络,2分类
self.model.build(input_shape=(None, 112, 112, 3)) # BHWC
self.model.summary()
self.loss_fun = losses.CategoricalCrossentropy() # 定义损失函数, 这里交叉熵
self.opt = tf.optimizers.SGD(learning_rate=lr) # 随机梯度下降优化器
self.train_acc_metric = metrics.CategoricalAccuracy() # 设定统计参数
self.val_acc_metric = metrics.CategoricalAccuracy()
def train(self, fpath="./data/mycatdog2", epochs=300, m=5):
""" 训练网络 """
batch_size = 64
test_acc_list = []
# 读取数据集
train_dataset = get_dataset(os.path.join(fpath, "train"), is_shuffle=True, batch_size=batch_size)
val_dataset = get_dataset(os.path.join(fpath, "valid"), is_shuffle=False, batch_size=batch_size)
# 训练
loss_val = 0
for epoch in range(epochs):
print(" ** Start of epoch {} **".format(epoch))
# 每次获取一个batch的数据来训练
for nbatch, (inputs, labels) in enumerate(train_dataset):
with tf.GradientTape() as tape: # 开启自动求导
y_pred = self.model(inputs, training=True) # 前向计算
loss_val = self.loss_fun(labels, y_pred) # 误差计算
grads = tape.gradient(loss_val, self.model.trainable_variables) # 梯度计算
self.opt.apply_gradients(zip(grads, self.model.trainable_variables)) # 权重更新
self.train_acc_metric(labels, y_pred) # 更新统计传输
if nbatch % m == 0: # 打印
correct = tf.equal(tf.argmax(labels, 1), tf.argmax(y_pred, 1))
acc = tf.reduce_mean(tf.cast(correct, tf.float32))
print('{}-{} train_loss:{:.5f}, train_acc:{:.5f}'.format(epoch, nbatch, float(loss_val), acc))
# 输出统计参数的值
train_acc = self.train_acc_metric.result()
self.train_acc_metric.reset_states()
print('Training acc over epoch: {}, acc:{:.5f}'.format(epoch, float(train_acc)))
# 每次迭代在验证集上测试一次
for nbatch, (inputs, labels) in enumerate(val_dataset):
y_pred = self.model(inputs)
self.val_acc_metric(labels, y_pred)
val_acc = self.val_acc_metric.result()
self.val_acc_metric.reset_states()
print('Valid acc over epoch: {}, acc:{:.5f}'.format(epoch, float(val_acc)))
test_acc_list.append(val_acc)
# 训练完成保存模型
tf.saved_model.save(self.model, "./output/mnist_model")
# 画泛化能力曲线(横坐标是epoch, 测试集上的精度),并保存
x = np.arange(1, len(test_acc_list)+1, 1)
y = np.array(test_acc_list)
plt.plot(x, y)
plt.xlabel("epoch")
plt.ylabel("val_acc")
plt.title('model acc in valid dataset')
plt.savefig("./output/val_acc.png", format='png')
if __name__ == "__main__":
path = "./output"
if not os.path.exists(path):
os.makedirs(path)
model = TrainModel()
model.train(fpath="F:\数据集\mycatdog2")
3.3 训练结果
训练了300个epoch, 在训练接上acc达到1.00。在验证集上acc=85%。

若是对大家有帮助,不要忘了关注、点赞、收藏哦…🙏🙏🙏🙏🙏🙏🙏


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











