







前言
在这一年多开发AIGC项目的过程中,对于Stable Diffusion相关的AIGC技术进行了系统性地学习,踩了不少的坑,为了给自己的学习成长经历进行沉淀总结,阶段性回顾,也给想要基于Stable Diffusion做AIGC应用的同学一些参考和建议,编写了此文档,分享一些自己的踩坑路线。我们的AIGC产品目前有日均几万的生图量,背后依靠的是我们从0到1构建的一个强大稳定的AIGC服务中台,在开发这个项目的过程中我总结了自己的一套方法论,我的方法当然不是最好的,如果有其他更好的路线大家也可以在评论区提出来一起交流学习。
一、Stable Diffusion基础
1.1 Stable Diffusion介绍
1.1.1 什么是Stable Diffusion
Stable Diffusion是一种深度学习模型,主要用于根据文本描述生成详细的图像,是生成式AI在图像领域的一开源巨作,由Stability AI公司于2022年发布。与同时期的其他AI绘画产品相比,例如Midjourney、Dalle-3相比,Stable Diffusion具有开源、免费、扩展性强、高定制化、社区活跃等显著优势。通过开源框架WebUI(https://github.sheincorp.cn/AUTOMATIC1111/stable-diffusion-webui)能快速在本地构建sd应用,实现文生图、图生图、局部重绘、高清修复等功能。
1.1.2 常见名词解释
正向提示词(prompt):
画面需要描述的提示词,SD的提示词只接受英文。
负向提示词(negative prompt):
不想让SD生成的内容。
采样迭代步数(step):
输出画面需要的步数,每一次采样步数都是在上一次的迭代步骤基础上绘制生成一个新的图片,一般来说采样迭代步数保持在 18-30 左右即可,低的采样步数会导致画面计算不完整,高的采样步数仅在细节处进行优化,对比输出速度得不偿失。
采样方法(sampler):
Stable Diffusion 在生成图像前,会先生成一张完全随机的图像,然后噪声预测器会在图像中减去预测的噪声,随着这个步骤的不断重复最终会生成一张清晰的图像。整个去噪过程叫做采样,使用到的方法叫做采样方法或采样器。常用的有Euler a,DPM++ SDE Karras等。
随机种子(step):
随机种子是一个可以锁定生成图像的初始状态的值。当使用相同的随机种子时我们可以生成画面大致相同的图像。设置随机种子可以增加模型的可比性和可重复性,同时也可以用于调试和优化模型,以观察不同参数对图像的影响。
在 WebUI 中,常用的随机种子有-1 和其他数值。当输入-1 或点击旁边的骰子按钮时,生成的图像是完全随机的,没有任何规律可言。而当输入其他随机数值时,就相当于锁定了随机种子对画面的影响,这样每次生成的图像只会有微小的变化。因此,使用随机种子可以控制生成图像的变化程度,从而更好地探索模型的性能和参数的影响。
提示词引导系数(CFG Scale):
CFG Scale是一个控制提示词与出图相关性的数值。 CFG Scale可以从0-15进行调整。一般对于Turbo类型的模型设置1.5-2.5,对于SD1.5和其他SDXL模型设置6.0-9.0。CFG Scale能够增加提示词中每个关键词对画面整体的影响。
平铺(tile):
tile是控制生成的图片是否是四方循环的图片,也就是类似于某些地板砖花纹一样,左边跟右边的边缘能够衔接,上边跟下边的边缘能够衔接。
重绘幅度(denoising strength):
重绘幅度决定了SD在图生图生成新图像时对原始图像的保留程度和改变程度,根据不同的重绘幅度,AI会在保留原始图像细节和生成新图像之间找到平衡。当重绘幅度较小(如0.1-0.3)时,AI对原始图像的改变非常微小。随着重绘幅度的增加(如0.4-0.8),AI开始在原始图像的基础上添加更多的变化,如服饰上的花纹、环境的改变等。重绘幅度0.7左右是一个建议的起点,以使AI能够将新的标签(tags)带入到图像中去,但不宜设置过高(大于0.8),以免破坏原始图片。重绘幅度达到1.0时,AI会进行100%的重绘,生成的图像与原图毫无关联,实现了一张全新的图像。
局部重绘:
局部重绘是SD图生图中的一项功能,其目的是指定一块区域,让SD仅重绘该区域或者重绘除该区域以外的部分。图像的重绘噪声来源可以通过蒙版区域内容处理(inpainting_fill)进行调整,不同的噪声来源会影响重绘结果中原图的保留程度。图像的重绘区域(inpaint_full_res)是决定SD在重绘图像时是否只在mask区域重绘还是重绘整个图像,当选择重绘仅蒙版区域时,重绘的部分常常与原图无法衔接。局部重绘的应用范围十分广泛,常常应用在AI换脸、AI消除等地方。
柔和重绘(soft inpainting):
柔和重绘是webui 1.8.0的新功能,目的是解决局部重绘时边缘衔接不自然的缺点,开启柔和重绘后sd会自动调整重绘区域的边缘模糊强度以保证重绘内容可以很好的融合到原图中。
1.1.3 工作原理简介
Stable Diffusion 技术,作为 Diffusion 改进版本,通过了引入隐向量空间来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。这里着重解析最常用的“文生图(text to image)”为主线,介绍 stable diffusion 计算思路以及分析各个重要的组成模块。
下图是一个基本的文生图流程,把中间的 Stable Diffusion 结构看成一个黑盒,输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,利用Stable Diffusion,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。
Stable Diffusion 的核心思想是,由于每张图片满足一定规律分布,利用文本中包含的这些分布信息作为指导,把一张纯噪声的图片逐步去噪,生成一张跟文本信息匹配的图片。它其实是一个比较组合的系统,里面包含了多个模型子模块,接下来把黑盒进行一步步拆解。stable diffusion 最直接的问题是,如何把人类输入的文字串转换成机器能理解的数字信息。这里就用到了文本编码器 text encoder(蓝色模块),可以把文字转换成计算机能理解的某种数学表示,它的输入是文字串,输出是一系列具有输入文字信息的语义向量。有了这个语义向量,就可以作为后续图片生成器 image generator(粉黄组合框)的一个控制输入,这也是 stable diffusion 技术的核心模块。图片生成器,可以分成两个子模块(粉色模块 黄色模块)来介绍。下面介绍下 stable diffusion 运行时用的主要模块:
(1) 文本编码器(蓝色模块),功能是把文字转换成计算机能理解的某种数学表示,在第三部分会介绍文本编码器是怎么训练和如何理解文字,暂时只需要了解文本编码器用的是 CLIP 模型,它的输入是文字串,输出是一系列包含文字信息的语义向量。
(2) 图片信息生成器(粉色模块),是 stable diffusion 和 diffusion 模型的区别所在,也是性能提升的关键,有两点区别:
① 图片信息生成器的输入输出均为低维图片向量(不是原始图片),对应上图里的粉色 44 方格。同时文本编码器的语义向量作为图片信息生成器的控制条件,把图片信息生成器输出的低维图片向量进一步输入到后续的图片解码器(黄色)生成图片。(注:原始图片的分辨率为 512512,有RGB 三通道,可以理解有 RGB 三个元素组成,分别对应红绿蓝;低维图片向量会降低到 64*64 维度)
② Diffusion 模型一般都是直接生成图片,不会有中间生成低维向量的过程,需要更大计算量,在计算速度和资源利用上都比不过 stable diffusion;
那低维空间向量是如何生成的?是在图片信息生成器里由一个 Unet 网络和一个采样器算法共同完成,在 Unet 网络中一步步执行生成过程,采样器算法控制图片生成速度,下面会在第三部分详细介绍这两个模块。Stable Diffusion 采样推理时,生成迭代大约要重复 30~50 次,低维空间变量在迭代过程中从纯噪声不断变成包含丰富语义信息的向量,图片信息生成器里的循环标志也代表着多次迭代过程。
(3) 图片解码器(黄色模块),输入为图片信息生成器的低维空间向量(粉色 4*4 方格),通过升维放大可得到一张完整图片。由于输入到图片信息生成器时做了降维,因此需要增加升维模块。这个模块只在最后阶段进行一次推理,也是获得一张生成图片的最终步骤。
扩散过程发生在图片信息生成器中,把初始纯噪声隐变量输入到 Unet 网络后结合语义控制向量,重复 30~50 次来不断去除纯噪声隐变量中的噪声,并持续向隐向量中注入语义信息,就可以得到一个具有丰富语义信息的隐空间向量(右下图深粉方格)。采样器负责统筹整个去噪过程,按照设计模式在去噪不同阶段中动态调整 Unet 去噪强度。
如下图 所示,通过把初始纯噪声向量和最终去噪后的隐向量都输到后面的图片解码器,观察输出图片区别。从下图可以看出,纯噪声向量由于本身没有任何有效信息,解码出来的图片也是纯噪声;而迭代 50 次去噪后的隐向量已经耦合了语义信息,解码出来也是一张包含语义信息的有效图片。
1.1.4 SD基础模型分类
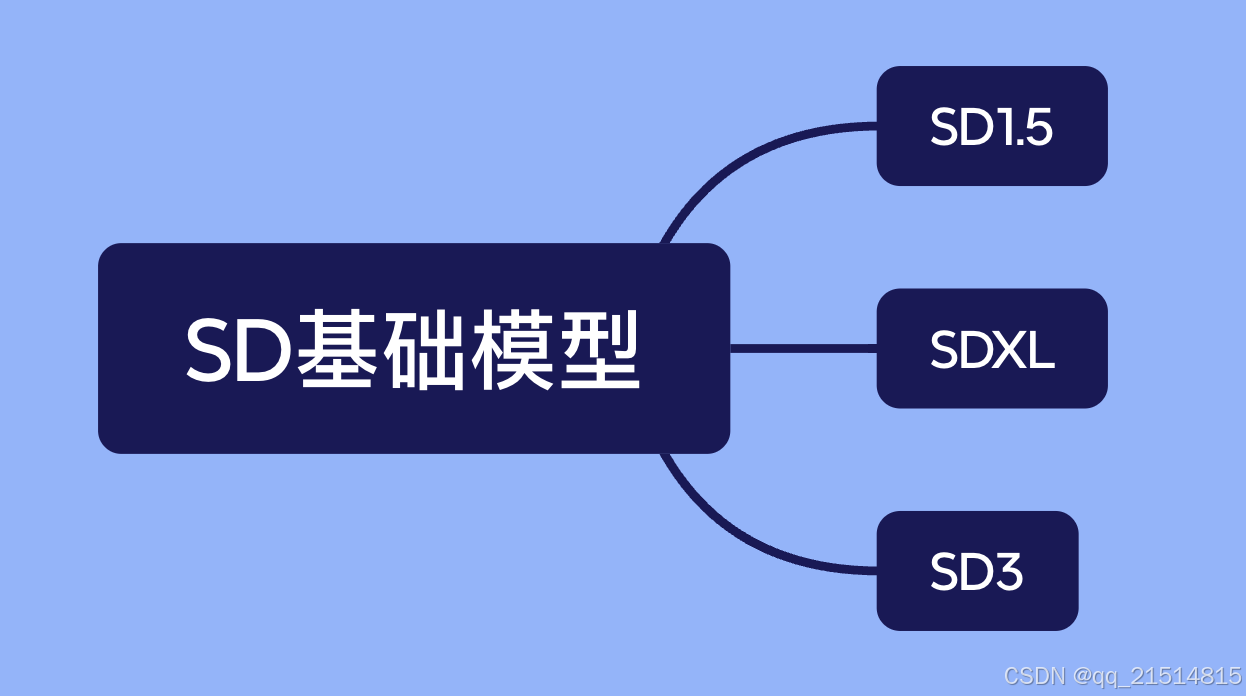
SD的底座模型主要是指Stability AI公司发布的SD大模型,以及SD社区基于SD大模型重新训练的各类风格大模型。目前本AIGC项目用到的大模型主要有SD1.5和SDXL。SD1.5与SDXL是Stability AI公司先后在2022年10月、2023年6月发布,SDXL可以看作是SD1.5的升级版,用来生成更高质量的图片,相应的其对于GPU算力和显存的要求也更高。SD1.5与SDXL模型对于代码的版本、参数协议的要求都是一致的,不过需要注意的是对于lora、controlnet等扩展模型这两种大模型是不通用的,下载lora、controlnet模型的时候应当注意到对应的大模型版本,另外对于TurboVision XL模型,该模型与其他模型不一样的地方在于它是一个基于XL蒸馏的模型,特点是4-6步迭代就能出图,该模型在传参时需要保证迭代步数在4-6之间,CFG Scale在1.5-2.5之间。
SD的基础模型和其扩展模型都可以在一些模型网站上下载,这里列举了一些常用的模型网站:
https://civitai.com (最经典的C站,专门针对于SD的模型网站,模型数量多,效果直观)
https://huggingface.co (开源AI模型库网站,一般大公司的开源模型都会优先在此发布)
https://www.liblib.art (国内的SD模型网站,不需要科学上网)
下载了大模型之后需要将模型文件放到/stable-diffusion-webui-master/models/Stable-diffusion目录下就会被加载。
1.2 主流框架介绍
Stability AI公司发布的主要是Stable Diffusion模型本身,如果想要使用模型进行推理,完成生图的过程则需要编写推理代码,HuggingFace提供了Diffusers库,它提供了简单方便的diffusion模型推理训练pipeline,同时拥有一个模型和数据社区,代码可以像torchhub一样直接从指定的仓库去调用别人上传的数据集和pretrain checkpoint。除此之外,安装方便,代码结构清晰,注释齐全,二次开发会十分有效率,如下代码即可使用sd模型进行推理:
from diffusers import StableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id)
prompt = "A boy wearing white suspenders and playing basketball"
image = stable_diffusion_txt2img (prompt).images[0]
image.save('generated_image.png') |
sd生态十分庞大,拥有诸如lora、controlnet等扩展,如果从头开始写推理代码成本将十分高昂,因此也可以采用一些开源的框架来使用sd,目前最常见的框架是WebUI和ComfyUI,WebUI使用Gradio作为UI开发工具,呈现了一个简单明了的交互界面,而Comfy拥有节点式和工作流式的AI绘画界面,并支持工作流模板的使用。本AIGC项目采用的是WebUI作为基础框架,其直观的交互方式和强大的扩展能力得到了实战的校验。
1.2.1 WebUI
WebUI的下载地址是https://github.sheincorp.cn/AUTOMATIC1111/stable-diffusion-webui,可以通过克隆git项目到本地部署运行,也可以直接下载社区大佬封装的一键安装包,这里先介绍手动部署的流程:
手动部署WebUI:
环境准备
创建虚拟环境:
conda create -n sd python=3.10.6 |
进入虚拟环境
conda activate sd |
下载代码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git |
安装依赖
pip install torch torchvision torchaudio pip install requirements.txt pip install -r requirements_versions.txt |
启动webui.sh
切换到stable-diffusion-webui目录,执行命令:
python launch.py --skip-torch-cuda-test --xformers --precision full --no-half --always-batch-cond-uncond --opt-split-attention |
运行webui时提供了很多可选参数,这里做一个解释
api模式: --nowebui: 表明不启用Web界面。这可能用于仅命令行环境或者其他界面的集成。 --listen: 使程序监听HTTP请求,以便通过网络接口与程序交互。 --port 80: 设置应用程序监听的端口为80,这是HTTP默认的端口号。 模型优化: --precision full: 设置模型运行的精度为full precision(全精度)。这通常意味着使用32位浮点数进行计算,可以提供更准确的结果,但可能会消耗更多资源。 --no-half: 确保使用full precision(全精度),即使是在可能支持half precision(半精度)的部分也是如此。 --no-half-vae: 保证变分自编码器(VAE)以full precision(全精度)运作,而不是half precision(半精度)。 --opt-split-attention: 启用优化的分割注意力模型,此选项可以改进内存使用效率,在处理大型模型时特别有用。 --xformers: 启用xformers支持。xformers是一种用于Transformer模型的高效执行库,有助于提高性能。 逻辑优化: --disable-nan-check: 禁用对NaN(Not a Number,非数字)值的检查。这可以提高性能,但如果出现计算错误,可能不会即时发现。 --disable-safe-unpickle: 禁用在反序列化(unpickle)时的安全检查。这有助于提升加载模型的速度,但可能会增加安全风险。 --skip-version-check: 跳过版本检查。这意味着不会检查Stable Diffusion WebUI或依赖包的版本是否是最新。 --skip-install: 跳过安装过程。这可能意味着,如果依赖没有正确安装,将不会自动安装它们。 |
启动成功后,访问http://127.0.0.1:7860即可使用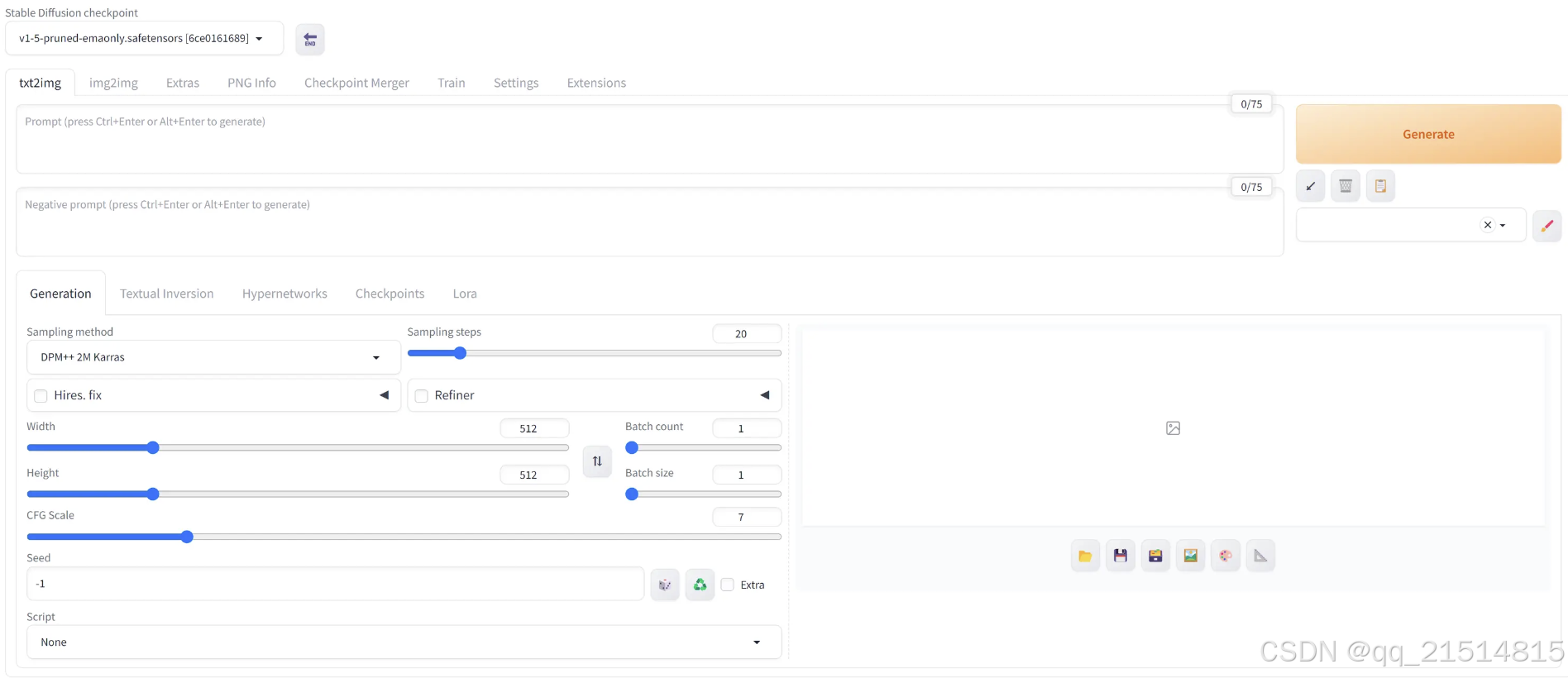
手动部署方式需要手动安装git、python、cuda等环境,如果觉得麻烦也可以直接下载社区的一键安装包:
参考文章:SD秋叶安装教程_秋叶sd-CSDN博客
1.2.2 ComfyUI
ComfyUI 是一个基于节点流程的 Stable Diffusion 操作界面,可以通过流程,实现了更加精准的工作流定制和完善的可复现性。每一个模块都有特定的的功能,我们可以通过调整模块连接达到不同的出图效果。但节点式的工作流也提高了一部分使用门槛。同时,因为内部生成流程做了优化,生成图片时的速度相较于 webui 有明显提升,对显存要求也更低。由于本项目服务化是基于WebUI的,因此不过多赘述ComfyUI,感兴趣可以自行了解。
1.3 扩展模型
1.3.1 Lora模型
Lora模型是一种微调模型,特点是轻量、训练方便,在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练基础大模型要小很多,模型文件一般也只有几十MB到几百MB。Lora模型必须结合基础大模型一起使用,使用方法也非常简单,只需要下载对应的Lora模型到Stable-diffusion-webui-master/models/lora目录,然后在生图的提示词中加上<lora:模型名:权重>即可开启。
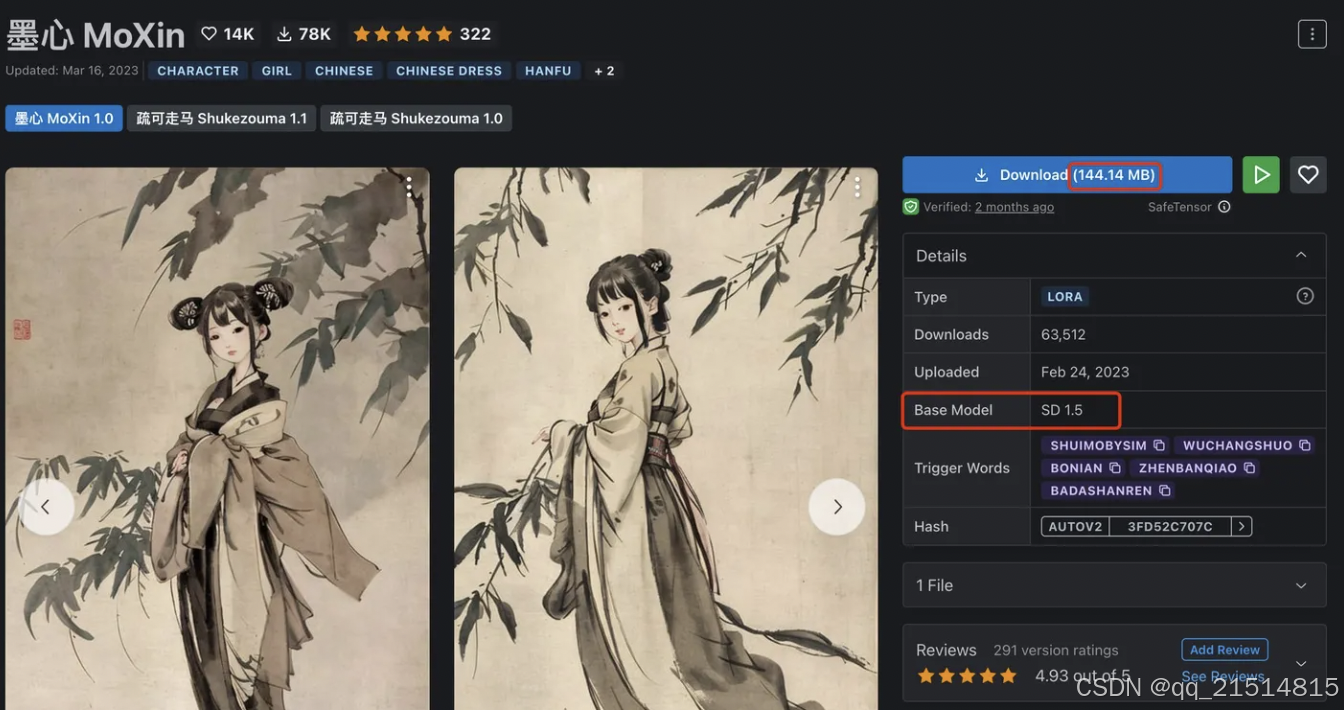
在下载Lora模型时需要主要到其适用的大模型版本,以C站为例,该Lora模型的右侧会标注该模型的类型是一个Lora模型,适用的基础模型是SD 1.5,因此只要是基于SD 1.5训练的基础大模型都可以使用该Lora模型。
1.3.2 Controlnet模型
ControlNet 是指一组使用稳定扩散精炼而成的神经网络,可在生成图像时实现精确的艺术和结构控制。它通过结合特定于任务的条件来改进默认的稳定扩散模型。传统的神经网络往往通过调整预设的权重和偏置来学习和适应,
但ControlNet可以保留了SD原有预训练模型的原创性和稳定性。简单地说,Controlnet模型提供了一种方法可以支持我们更精细维度地控制SD生成图像的方式,比如图像的线条、图像的深度信息、人物的姿势等等。Controlnet模型
是一个很广的范围,其中主要包括了轮廓类、景深类、对象类、重绘类模型。同Lora模型一样,Controlnet模型在使用时也需要对应其大模型版本,比如SD1.5的大模型应该使用的openpose模型是control_v11p_sd15_openpose [cab727d4],而SDXL类大模型使用的openpose模型应该是thibaud_xl_openpose [c7b9cadd],使用错误将导致出图失败或者模型不生效,一般可以通过controlnet模型名称中是否含有sd15/xl字样来初步判断它是哪一类模型。特别需要注意的是,在使用api创建任务时,controlnet模型id字段也就是"model"字段里的模型名称需要带上模型的哈希值,例如上文中的thibaud_xl_openpose [c7b9cadd]是由模型名称thibaud_xl_openpose+哈希值[[c7b9cadd]组成,中间由空格隔开,具体的哈希值获取方法参考本文2.2章节的API协议详解。
下载了Controlnet模型后将模型文件放到/stable-diffusion-webui-master/models/ControlNet目录下就会被加载。
Controlnet模型分类介绍
1. 轮廓类
顾名思义,轮廓类指的是通过元素轮廓来限制画面内容,轮廓类模型有 Canny 硬边缘、MLSD 直线、Lineart 真实线稿、Lineart_anime 动漫线稿、SoftEdge 软边缘、Segmentation 语义分割、Shuffle 随机洗牌这 7 种,且每种模型都配有相应的预处理器,由于算法和版本差异,同一模型可能提供多种预处理器供用户自行选择。
轮廓类的Controlnet模型非常丰富,但最常用的是canny硬边缘模型,它的使用范围很广,被作者誉为最重要的ControlNet 之一,该模型源自图像处理领域的边缘检测算法,可以识别并提取图像中的边缘特征并输送到新的图像中。
下图中我们可以看到,canny 可以准确提取出画面中元素边缘的线稿,即使配合不同的主模型进行绘图都可以精准还原画面中的内容布局。
有些预处理器在选择后,下方会多出用于调节特征提取效果的特定参数,比如当我们选择 canny(硬边缘检测)时,下方会增加 Canny low threshold 低阈值和 Canny high threshold 高阈值 2 项参数,对应api协议中的threshold_a和threshold_b,这是用来调节canny结果中边缘的细节程度,两者的数值范围都限制在 1~255 之间,通过对比图可以看到只要区间一致最终的线稿图就会完全一样,区间越低,线条细节就越丰富,对结果图的影响就越大,需要注意密度过高会导致绘图结果中出现分割零碎的斑块,但如果密度太低又会造成控图效果不够准确,因此我们需要调节阈值参数来达到比较合适的线稿控制范围。
2. 景深类
景深一词是指图像中物体和镜头之间的距离,简单来说这类模型可以体现元素间的前后关系,包括 Depth 深度和 NormalMap 法线贴图这 2 种模型。
还是以最常用的Depth深度模型为例,Depth 模型可以提取图像中元素的前后景关系生成深度图,再将其复用到绘制图像中,因此当画面中物体前后关系不够清晰时,可以通过 Depth 模型来辅助控制。下图中可以看到通过深度图很好的还原了建筑中的空间景深关系。
3. 对象类
对象类最为著名的代表就是OpenPose模型,作为唯一一款专门用来控制人物肢体和表情特征的关键模型,它被广泛用于人物图像的绘制,在本项目中有广泛的应用,对于模特姿势的控制起到了至关重要的作用。
OpenPose 特点是可以检测到人体结构的关键点,比如头部、肩膀、手肘、膝盖等位置,而将人物的服饰、发型、背景等细节元素忽略掉。它通过捕捉人物结构在画面中的位置来还原人物姿势和表情。
4、重绘类
重绘模型是对原生图生图功能的延伸和拓展,例如inpaint局部重绘是对原生局部重绘功能的增强,instructP2P是通过一种指令的方式对原图进行指导重绘。
1.3.3 VAE模型
VAE模型一般主要起到滤镜的作用,同样是需要搭配基础大模型使用,并且需要对应相应的大模型版本。
下载了VAE模型后将模型文件放到/stable-diffusion-webui-master/models/VAE目录下就会被加载。
1.3.4 Embedding模型
Embedding模型也叫嵌入式模型,主要应用在提示词打包成合集中,例如本项目中常常使用的反向提示词EasyNegative其实就是一个Embedding模型,其中包含了暴力、色情、人物残缺、图像错误等不希望出现的内容,这样能减少负向提示词的输入词数,提高使用效率。
下载了Embedding模型后将模型文件放到/stable-diffusion-webui-master/models/Embedding目录下就会被加载。

















 2010
2010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









