






 本文探讨了如何利用大语言模型提升推荐系统的性能,涉及特征工程、内容理解、用户理解和样本生成等方面,并分析了工业场景下的挑战,如训练效率、推理时延和文本长度限制,同时列举了几个实际应用场景,展示了大模型在电商、用户冷启动和广告生成等领域的潜力。
本文探讨了如何利用大语言模型提升推荐系统的性能,涉及特征工程、内容理解、用户理解和样本生成等方面,并分析了工业场景下的挑战,如训练效率、推理时延和文本长度限制,同时列举了几个实际应用场景,展示了大模型在电商、用户冷启动和广告生成等领域的潜力。
How Can Recommender Systems Benefit from Large Language Models: A Survey
传统推荐模型以embedding+深度网络为backbone,通过拟合用户反馈信号提升推荐效果,主要特点是:1模型较小时空开销低,2可以充分利用用户反馈信号,3只能利用数据集内知识,4缺乏语义信息和深度意图推理。
大语言模型LLM以transformer为backbone,通过大规模预训练语料和自监督训练提升通用语义理解和生成能力,特点是:1引入外部开放世界知识、语义信号丰富,2具备跨域推荐能力、适合冷起场景,3用户反馈信号缺失,4复杂度高难处理海量样本
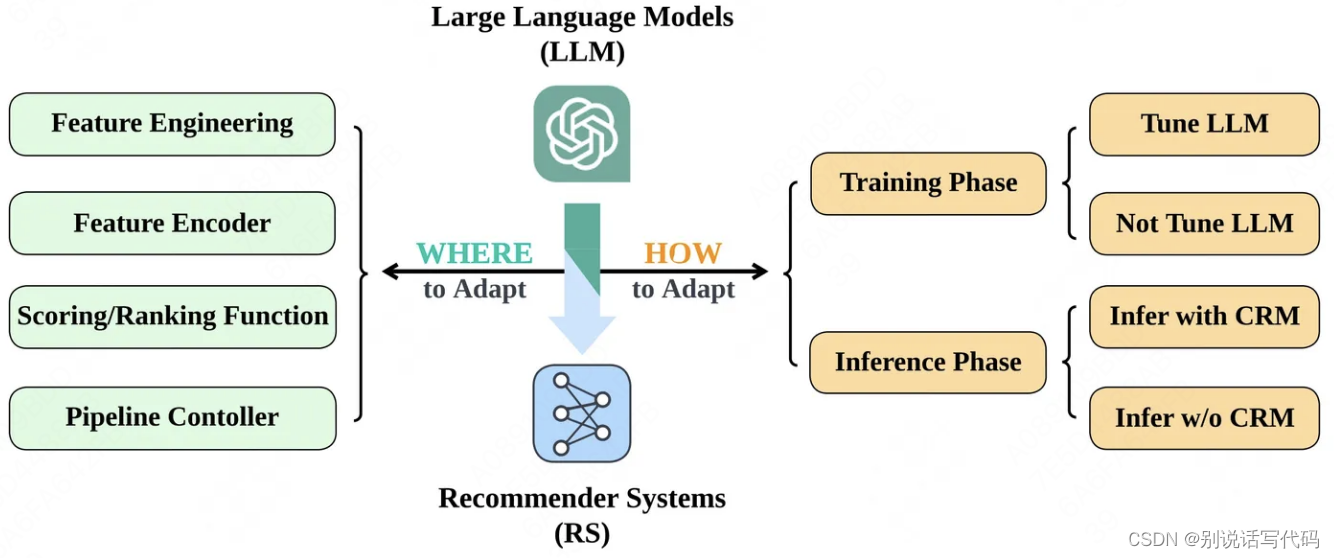
推荐模型如何从大语言模型取长补短,提升推荐性能,优化用户体验,将问题分为2个:何处使用LLM,如何使用LLM
何处使用大模型
-
特征工程阶段:对原始数据进行筛选、加工、增强,得到可供下游深度模型使用的结构化数据
-
内容理解:输入新闻标题、摘要、类目信息,生成简短内容描述;
-
用户理解:输入用户历史行为数据,生成用户感兴趣的话题和区域;
-
样本生成:对于历史行为数据稀疏的用户,基于少量行为样本生成相似的伪样本,用于扩充用户表征输入。
-
-
特征编码阶段:对结构化数据进行编码,得到对应的稠密向量表示
-
代表性工作:U-BERT: Pre-training user representations for improved recommendation 出自Tencent, AAAI'21,基于大模型进行用户表征学习。
-
背景:电商推荐系统中如何使用用户和item侧丰富的文本特征
-
技术方案:
-
输入:用户历史交互行为以及购买后的评价信息;
-
预训练阶段
-
Review Encoder:基于BERT对用户所写的评价进行语义编码;
-
User Encoder:基于attention网络对review token表征进行聚合;
-
两个子任务,rating & MLM。
-
-
- 微调阶段(训练):增加item侧编码网络,拟合用户反馈数据。
-
-
-
打分排序阶段:对候选物品进行打分排序,得到要呈现给用户的排序列表
-
打分/排序是推荐系统的核心任务,目标是得到和用户偏好相符的物品(列表)。根据如何得到最终排序列表的形式,作者将大语言模型应用于打分/排序的工作分成以下三种:
-
物品评分任务(Item Scoring Task):大语言模型对候选物品逐一评分,最后根据分数排序得到最终的排序列表;
-
物品生成任务(Item Generation Task):通过生成式的方式生成下一个物品的ID,或者直接生成排序列表;
-
混合任务(Hybrid Task):大语言模型天然地适合多任务场景,因此很多工作会利用大语言模型来实现多个推荐任务,其中包括评分任务和生成任务。
-
-
代表工作:PALR: Personalization Aware LLMs for Recommendation
-
利用用户历史交互得到用户画像,然后基于用户画像、历史交互和提前过滤得到的候选集信息生成推荐列表;
-
经过指令微调,PALR在公开数据集上显著超过传统推荐模型baseline。
-
-
-
流程控制:作为中央控制器,把控推荐系统的整体流程。也可以细化到对排序阶段的召回、粗排、精排的控制。
工业场景下的挑战:
-
训练效率
-
问题:显存用量过大、训练时间过长
-
可能解决思路:1. 参数高效微调(PEFT)方案;2.调整模型更新频率(e.g.长短更新周期结合)
-
-
推理时延
-
问题:推理时延过高
-
可能解决思路:
-
预存部分输出或中间结果,以空间换时间;
-
通过蒸馏、剪枝、量化等方法,降低推理模型的真实规模;
-
仅用于特征工程和特征编码,避免直接在线上做模型推理
-
-
-
推荐领域的长文本建模
-
问题:长用户序列、大候选集、多元特征都会导致推荐文本过长,不仅难以被大模型有效捕捉,甚至可能会超过语言模型的上下文窗口限制(Context Window Limitation)
-
可能解决思路:通过过滤、选择、重构,提供真正简短有效的文本输入
-
-
ID特征的索引和建模
-
问题:纯ID类特征(e.g. 用户ID)天然不具备语义信息,无法被语言模型理解
-
可能解决思路:探索更适合语言模型的ID索引和建模策略
-
场景应用:
1.利用LLM等大模型,根据用户历史打分评价,以及店家相关内容知识,生成对店家的描述和评价,对商品也是类似道理,比如一个套餐,适合2个人吃,某菜很不错等等
2.用户冷启动:在用户冷起根据已有知识对用户进行冷起推荐,比如用户进来看跟团游,可能会推很多相关历史古迹等,想法好但是不太容易实践
3.店家生成广告海报,根据描述生成推广图文信息,省去了设计费等
4.召回阶段,根据item多模态信息训练大模型得到物品表征,最终通过i2i重定向召回。

















 1609
1609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









