






1. 基本卷积操作
2. 11抽头滤波器HLS代码
#define N 11
#include "ap_int.h"
typedef int coef_t;
typedef int data_t;
typedef int acc_t;
void fir(data_t *y, data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0, 53};
static data_t shift_reg[N];
acc_t acc;
int i;
acc = 0;
Shift_Accum_Loop:
for (i = N - 1; i >= 0; i--) {
if (i == 0) {
acc += x * c[0];
shift_reg[0] = x;
} else {
shift_reg[i] = shift_reg[i - 1];
acc += shift_reg[i] * c[i];
}
}
*y = acc;
}该功能不能提供FIR滤波器的有效实现。 它基本上是顺序的,并且采用了大量不必要的控制逻辑。 以下部分描述了许多可以改善其性能的不同优化。
3. 计算性能
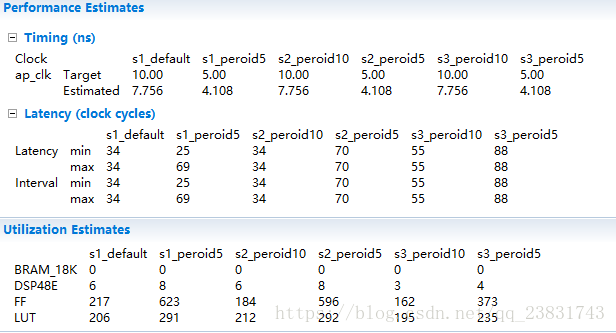
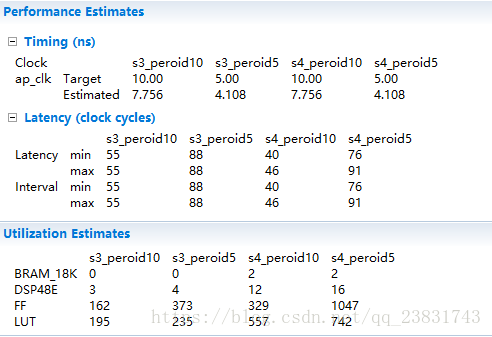
虽然实现更高的频率通常对于实现更高的性能是至关重要的,但是就整个系统而言,增加目标时钟频率不一定是最佳的。 较低的频率为工具提供了更多的余地,以便在单个周期中组合多个相关操作,这一过程称为操作链(operation chaining)。这有时可以通过改进逻辑综合优化和增加适合设备的代码量来实现更高的性能。改进的操作链也可以改善(即,降低)具有重现的流水线的启动间隔(initiation interval)。 通常,提供受约束但不过度约束的目标时钟延迟是一个不错的选择。周期在5到10 ns范围内通常是一个很好的启动选项。 优化设计后,您可以改变时钟周期并观察结果。 我们将在下一节中更详细地描述操作链。
- 创建时钟tcl命令:create clock −period 5ns
- 时钟不确定性tcl命令:set clock uncertainty
当我们执行流水线操作和其他优化时,计算性能变得更加复杂。 在这种情况下,了解任务间隔和任务延迟之间的差异非常重要。
4. 操作链
操作链是Vivado HLS执行的一项重要优化,以优化最终设计。 这不是设计师可以控制的东西,但设计师必须了解其工作原理,尤其是在性能方面。
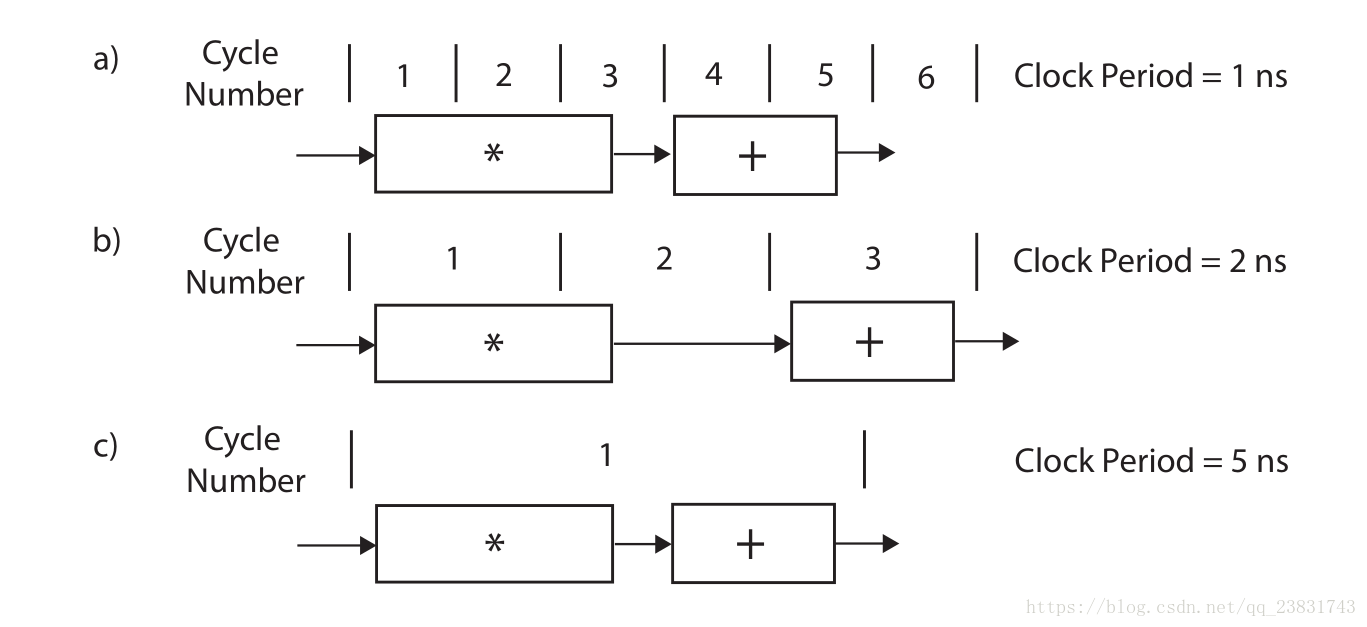
在大多数情况下,我们主张在部分时钟周期内坚持下去。 例如,在项目中,我们建议您将时钟周期设置为10 ns,并专注于了解如何使用其他优化(例如流水线操作)来创建不同的体系结构。这种100 MHz时钟频率相对容易实现,但它提供了良好的一阶结果。 当然可以创建以更快的时钟速率运行的设计。 200 MHz和更快的设计是可能的,但通常需要在时钟频率目标和其他优化目标之间进行更仔细的平衡。 您可以更改目标时钟周期并观察性能差异。 不幸的是,选择最佳频率没有好的规则。
5. 代码提升
for循环中的if/else语句效率低下。 对于代码中的每个控制结构,Vivado HLS工具创建逻辑硬件,检查是否满足条件,该条件在循环的每次迭代中执行。 此外,这种条件结构限制了if或else分支中语句的执行; 这些语句只能在if条件语句解析后执行。
if语句检查x == 0,这仅在最后一次迭代时发生。 因此,if分支中的语句可以“优化”出循环。 也就是说,我们可以在循环结束后执行这些语句,然后删除循环中的if/else控制流。 最后,我们必须改变执行第0次迭代的循环边界。最终结果是一个更紧凑的实现,对于进一步的循环优化(例如展开和流水线操作)已经成熟。
Shift Accum Loop:
for (i = N − 1; i > 0; i−−) {
shift reg[i] = shift reg[i − 1];
acc += shift reg[i] ∗ c[i];
}
acc += x ∗ c[0];
shift reg[0] = x;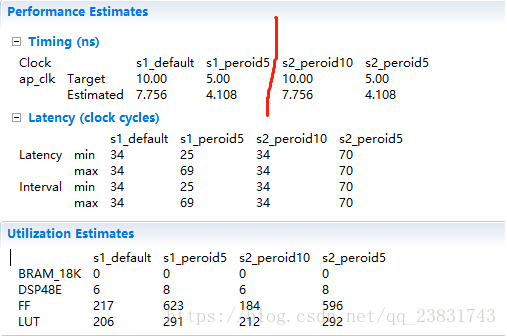
6. 循环分裂(Loop Fission)
我们在for循环中做了两个基本操作。 第一部分通过移位寄存器阵列移位数据。 第二部分执行乘法和累加运算,以计算输出样本。 循环分裂采用这两个操作并在它们自己的循环中实现它们中的每一个。 虽然它可能在直觉上看起来不是一个好主意,但它允许我们在每个循环上单独执行优化。 这在分裂循环的结果优化不同的情况下尤其有利。
TDL: //Tapped delay line (TDL)
for (i = N - 1; i > 0; i--) {
shift_reg[i] = shift_reg[i - 1];
}
shift_reg[0] = x;
acc = 0;
MAC:
for (i = N - 1; i >= 0; i--) {
acc += shift_reg[i] * c[i];
}
单独的环路分裂通常不能提供更有效的硬件实现。 但是,它允许每个循环独立优化,这可以比优化单个原始for循环产生更好的结果。反过来也是如此, 将两个(或更多)for循环合并为一个for循环可以产生最佳结果。 这在很大程度上取决于应用程序,对大多数优化都是如此。一般来说,如何优化代码没有一个“经验法则”。 因此,掌握许多技巧非常重要,深入了解优化的工作原理甚至更重要。只有这样,您才能创建最佳的硬件实现。
7. 循环展开
默认情况下,Vivado HLS工具以顺序方式合成for循环。 该工具创建一个数据路径,实现循环体中语句的一次执行。 数据路径对循环的每次迭代顺序执行。 这创造了一个区域高效的架构; 但是,它限制了利用循环迭代中可能存在的并行性的能力。
循环展开会将循环体复制多个(称为因子)。 并且它通过相同的因子减少了循环的迭代次数。 在最好的情况下,当循环中的任何语句都不依赖于先前迭代中生成的任何数据时,这可以显着增加可用的并行性,从而使运行速度更快的体系结构成为可能。
- 将shift_reg数组中的所有值放入寄存器:
#pragma HLS array partition variable=shift_reg complete - 循环展开两次:
#pragma HLS unroll factor=2
TDL: HLS UNROLL factor=2
MAC: HLS UNROLL factor=4
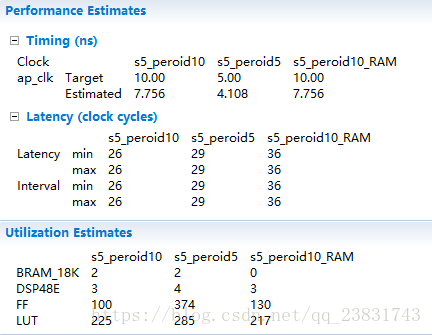
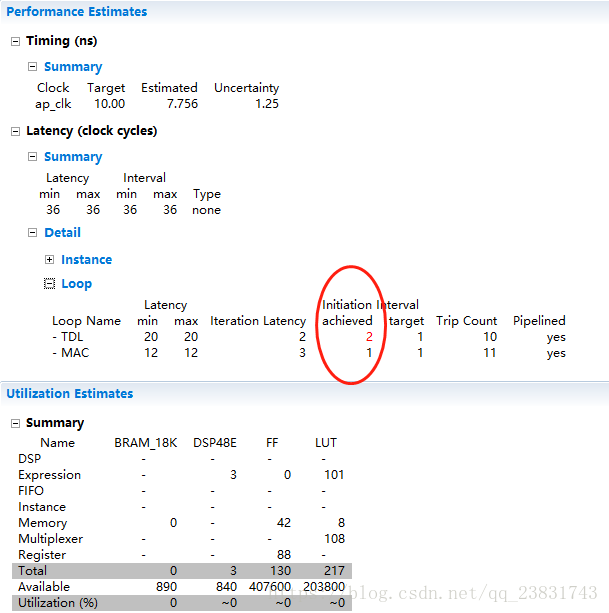
8. 循环流水线
TDL: HLS PIPELINE
MAC: HLS PIPELINE
shift_reg: HLS RESOURCE variable=shift_reg core=RAM_1P
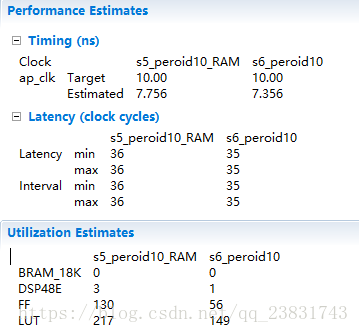
9. 位宽优化
#include ”ap int.h”
- Unsigned: ap_uint< width >
- Signed: ap int< width >
typedef ap_int<10> coef_t;
typedef ap_int<12> data_t;
typedef ap_int<12> acc_t;














 1292
1292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









