









Excel作为常见数据存储、报表生成和数据分析的主力军,随着数据体量的增长,和数据分析、挖掘,BI更进一步需要,如何快速地使用Pandas来ETL Excel或者分析Excel就变得很重要了。
常见特殊表单
今天讨论的就是几个比较特殊的表单形式,
处理方式
碰到面的这几种形式,你会怎么做?
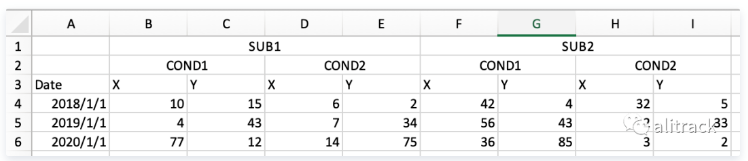
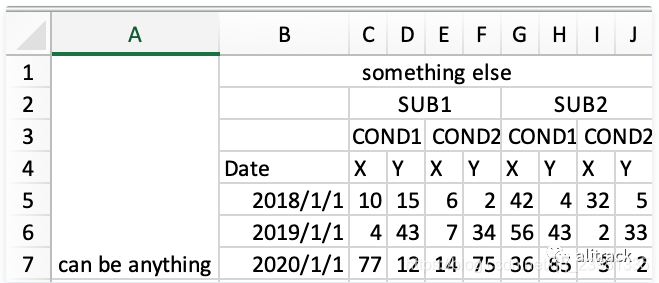
第一个和第二个图都是多行表头的形式,pandas的read_excel运行指定从指定行开始读取(就是忽略某些行)以及指定哪些为表头,
import pandas as pd(1)图1的处理代码实现:
df = pd.read_excel('3headers_demo.xlsx'
,sheet_name="Sheet1"
,header=[0,1,2])
df
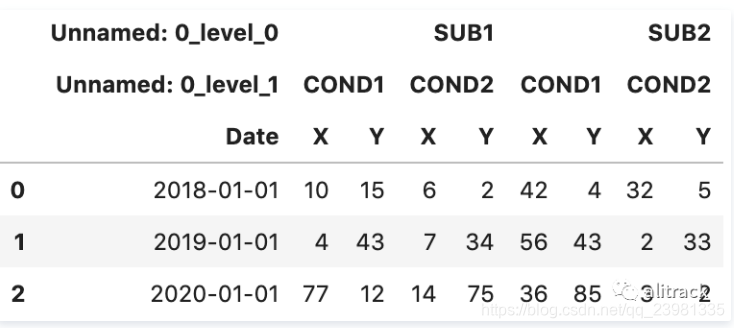
df=df.set_index(df.columns[0])
df=df.stack(level=0).stack(level=0).reset_index()
df.columns=list(df.columns[1:].insert(0,'Date'))
df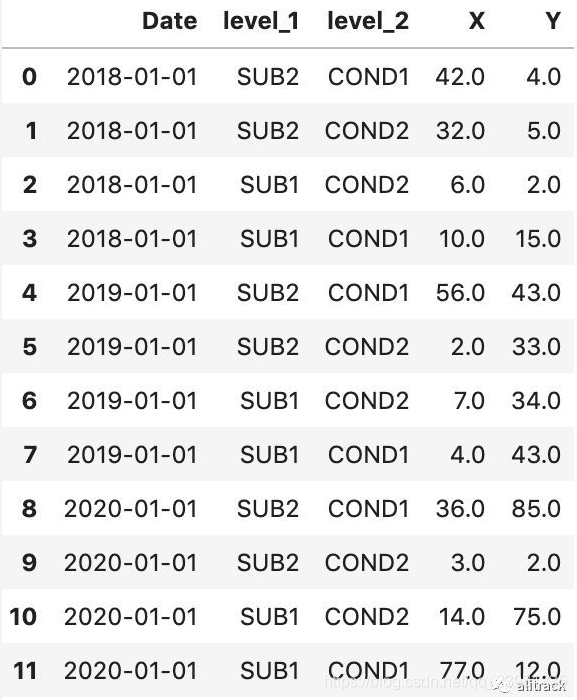
(2)图2的代码实现:
df = pd.read_excel('3headers_demo.xlsx'
,sheet_name="Sheet4"
,skiprows=1
,header=[0,1,2])
df=df.iloc[:,1:]
df=df.set_index(df.columns[0])
df得到和图1一样的结果,接下来的处理便一样了。
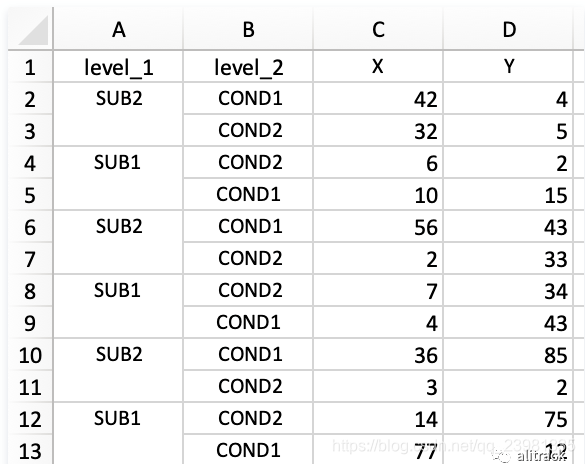
(3)图3的代码实现:
图3是一种常见的MultiIndex形式:
df = pd.read_excel('3headers_demo.xlsx'
,sheet_name="Sheet3"
,index_col=[0,1])
df.reset_index()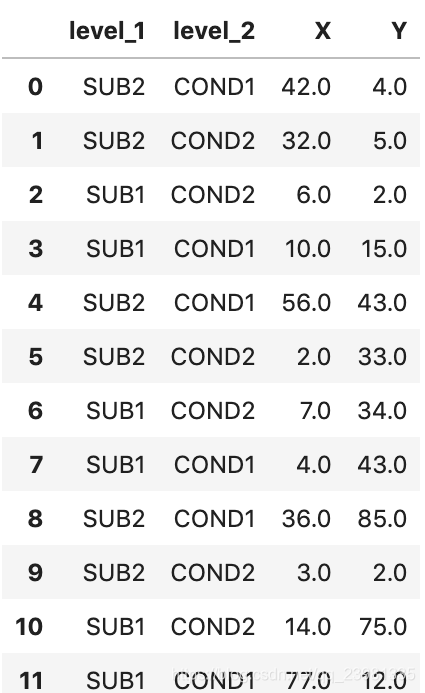
附录
Pandas不仅仅可以方便读取上面的复杂格式数据,也提供了非常丰富的数据转换函数,可以详细阅读这篇文章,代码为主,https://pandas.pydata.org/pandas-docs/stable/user_guide/reshaping.html


















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











