







宝子们👋,还在眼巴巴看着别人用超厉害的 Qwen 大模型吗?今天就手把手教你在 Windows 系统上,把这个超牛的模型部署到自己电脑里,就算是电脑小白也能轻松拿捏,赶紧码住,开启你的 AI 大神之路💻
为啥一定要本地化部署 Qwen?1️⃣
- 隐私安全大保障:所有数据都在咱自己电脑里处理,再也不怕隐私被泄露,安全感直接拉满💯
- 闪电速度不等待:没有网络延迟的烦恼,模型响应那叫一个快,体验感直接起飞,效率翻倍🚀
- 个性定制超自由:可以根据自己的需求,随意调教模型,打造专属的 AI 小助手,不管是工作、学习还是娱乐,都超适配🎯
部署前的准备清单2️⃣
-
版本 内存要求 显卡要求 特点优势 Qwen2.5 - 0.5B 至少 4GB 内存 可使用 CPU 部署,有 NVIDIA GeForce GT 1030 更好 对内存要求低,普通家用电脑可处理简单文本任务,如简单文本分类、基础问答回复等 Qwen2.5 - 1.5B 8GB 内存起步 NVIDIA GeForce GTX 1650 及以上加速,无则 CPU 部署 能处理稍复杂文本任务,如中等长度文本生成、简单语言推理,加速可提升效率 Qwen2.5 - 3B 12GB 及以上内存 NVIDIA GeForce RTX 2060 及以上 可处理更复杂语义理解、多轮对话等任务,充足内存避免卡顿,显卡提升效率 Qwen2.5 - 7B 至少 16GB 内存 NVIDIA GeForce RTX 3060 及以上,无则 CPU 慢部署 处理复杂自然语言任务出色,如专业领域文本分析、深度问答交互,大内存保稳定 Qwen2.5 - 14B 32GB 内存起步 NVIDIA GeForce RTX 3060 及以上 应对复杂长文本处理、高精度语言生成等任务游刃有余,大内存防错误 Qwen2.5 - 32B 64GB 及以上内存 NVIDIA GeForce RTX 40 系列及以上 语言理解和生成能力质的飞跃,处理大规模文本数据和复杂任务需强大内存和高端显卡 Qwen2.5 - 72B 128GB 及以上内存 NVIDIA GeForce RTX 40 系列及以上,多卡并行更佳 能处理最复杂专业语言任务,如大型科研报告生成、复杂语义推理,大内存和多卡是关键
安装 Ollama 的详细步骤3️⃣
- 下载 Ollama:从官网下载 Windows 版本安装包,网络不好可使用代理或私信获取。
- 安装 Ollama:双击.exe 文件,按安装向导提示操作,可保持默认设置并选择安装路径。
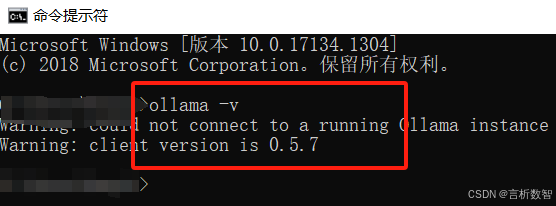
- 验证安装:在命令提示符输入ollama -v,若显示版本号则安装成功,否则失败。

下载并部署 Qwen 模型全流程4️⃣
- 打开模型库:浏览器输入
https://ollama.com/library,这里面模型超多,找到咱们的 Qwen 家族,有Qwen-0.5B 、Qwen-7B、Qwen-14B等不同版本,每个版本都有自己独特的优势。 - 选择合适版本:根据自己电脑配置来选。
配置一般,选 Qwen-0.5B,运行起来更稳定;要是电脑配置很顶,Qwen-7B 及以上版本随便挑,体验更强大的模型性能。比如 16GB 内存的电脑,Qwen-0.5B 是个不错的选择;32GB 及以上内存,就可以尝试 Qwen-7B。 - 复制运行命令:确定好要下载的模型版本后,复制对应的ollama run命令。比如运行 Qwen-7B,就复制
ollama run qwen-7b。 - 下载并运行模型:回到命令提示符窗口,粘贴刚才复制的命令
ollama run qwen-7b,然后回车。这时候就耐心等它下载吧,可能需要一些时间,毕竟是个大模型呢~下载完成后,就能在命令窗口和 Qwen 模型聊天啦,不过命令行界面不太美观,也不方便复制内容,别着急,下面教你配置一个超好用的可视化界面👇
配置可视化界面(强烈推荐!)5️⃣
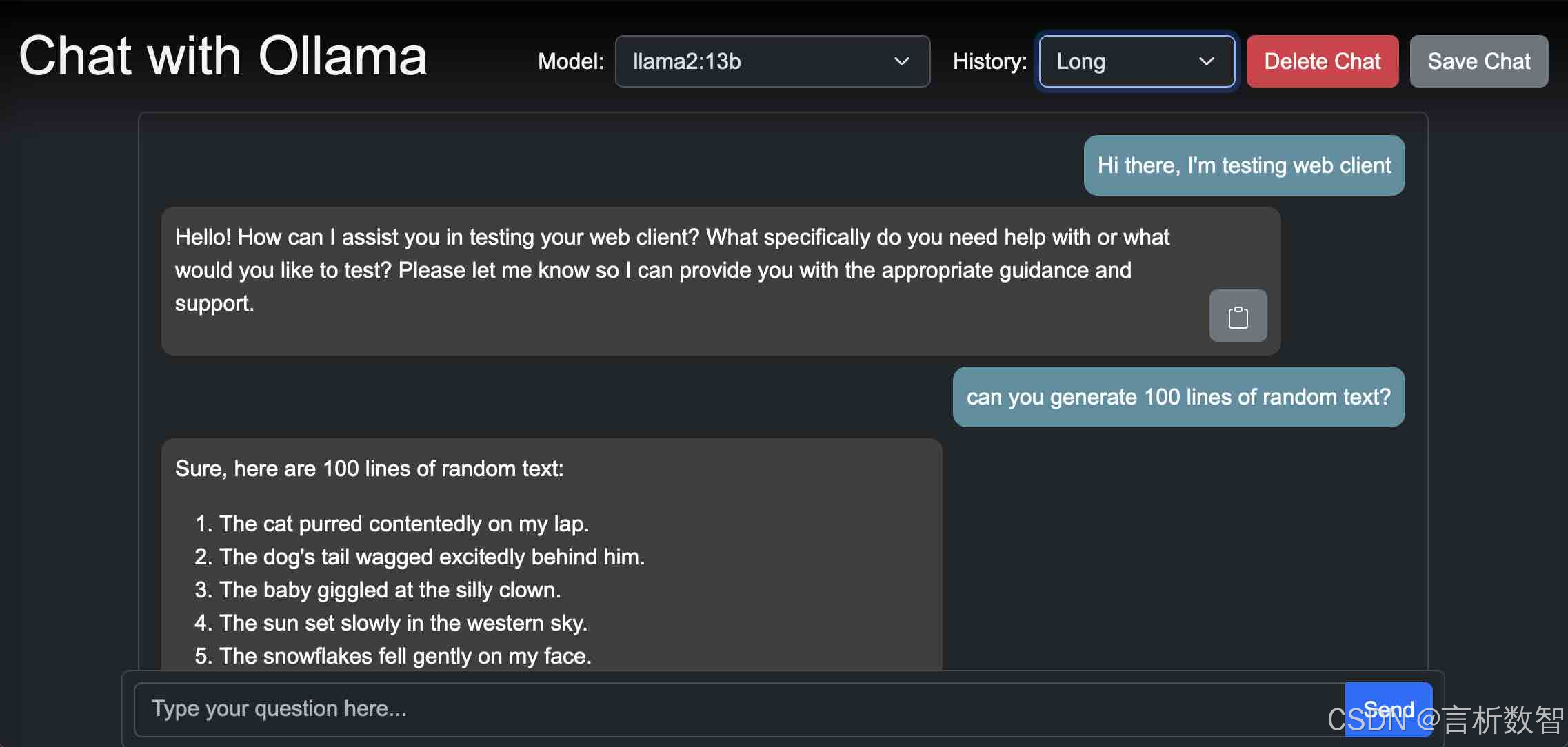
- 选择可视化工具:Ollama - UI,界面简洁美观,操作超方便,能大大提升和模型交互的体验。另外, ChatGPT-Next-Web也可以作为可视化工具的选择,它有丰富的自定义设置,能满足不同宝子的需求。
- 安装可视化工具:以 Ollama - UI 为例,下载好安装包后,双击它,按照安装向导的步骤完成安装,安装过程中可能会有一些提示,按照提示操作就行啦。
-
-
如果是安装
ChatGPT-Next-Web,需要先安装 Node.js ,然后在命令提示符中输入以下命令:git clone https://github.com/Yidadaa/ChatGPT-Next-Web.git cd ChatGPT-Next-Web npm install -
配置连接:打开安装好的
Ollama - UI,在设置里找到连接Ollama的地方,输入http://localhost:11434( Ollama 的默认端口),然后保存设置。如果是 ChatGPT-Next-Web,需要在.env.local文件中配置以下内容:OPENAI_API_KEY=sk-xxxxxx // 填写你的Ollama API密钥,在Ollama安装目录下的config.yaml文件中可以找到 BASE_URL=http://localhost:11434
-
案例效果示例6️⃣
-
应用领域 案例背景 效果呈现 智能客服领域 某大型电商平台每天收到海量客户咨询,涉及商品信息、订单状态、售后政策等多方面。以往依靠人工客服处理,效率低、成本高,还易出现回复不及时的情况。引入Qwen模型构建智能客服系统 1. 响应速度提升:平均响应时间从数分钟缩短至1 - 2秒。
2. 问题解决率提高:能准确回答约80%以上常见问题,整体问题解决率提升约15%。
3. 降低人力成本:减少约30%的客服人力投入。内容创作领域 一家新媒体公司需要每天生产大量文章、文案等内容,如新闻资讯、产品推广文案、社交媒体帖子等。以往依赖编辑团队创作,耗时费力,内容创新性和多样性有限。使用Qwen辅助内容创作 1. 创作效率提升:以1000字左右新闻资讯为例,创作时间从1 - 2小时缩短至30 - 40分钟,效率提升近60%。
2. 内容质量提高:产品推广文案点击率平均提高20%,转化率也有提升。
3. 拓展创作类型:可尝试诗歌、小说等更多类型创作,拓展内容领域。教育领域 某在线教育平台提供多种课程学习服务,学生学习中会遇到各种问题需要及时解答,教师也需花费大量时间备课和批改作业。引入Qwen用于教学辅导和课程设计 1. 个性化学习辅导:帮助学生提高学习成绩,测试平均分提高8分。
2. 减轻教师负担:教师工作效率提高约40%。
3. 丰富教学资源:生成动画、视频脚本等,提高学生学习兴趣和参与度。金融领域 一家银行需要处理大量客户咨询,包括账户信息查询、贷款政策咨询、理财产品介绍等,还要对市场动态进行分析预测,为客户提供投资建议。引入Qwen 1. 客户服务优化:平均响应时间缩短至3秒以内,客户满意度提升12%。
2. 市场分析与预测:股票市场分析预测准确率达70%左右,助力投资获更高收益。
3. 风险评估:对客户信用和投资风险合理评估,有助于控制风险、降低不良贷款率。
常见问题及解决办法7️⃣
- 下载速度慢:可以换个网络试试,或使用代理工具。也可以去 Ollama 官方 GitHub 仓库(https://github.com/jmorganca/ollama )找找其他下载方式,说不定有惊喜哦。还可以在仓库的 issues 板块看看其他用户有没有分享加速下载的技巧。
- 模型运行出错:先检查命令有没有输错,模型版本和电脑配置匹不匹配。要是环境变量有问题,就重新检查设置;缺依赖项的话,按提示安装就行。比如缺少某个依赖库,在命令行中会有提示,按照提示在相应的包管理工具(如 pip)中安装就好啦。如果是环境变量问题,可以在 “此电脑” 上右键,选择 “属性”,然后点击 “高级系统设置”,在 “环境变量” 中进行检查和修改。
- 可视化界面连不上:先确认 Ollama 有没有成功运行,连接地址对不对。再看看防火墙,是不是拦住了相关端口。可以暂时关闭防火墙试试,如果能连接上,就需要在防火墙中设置允许 Ollama 和可视化工具通过,这样就能愉快玩耍啦😎
技源链路8️⃣
-
资源类型 资源链接 通义千问智慧体验殿堂 阿里云通义千问官网 通义千问开发者赋能天地 阿里云开发者社区 - 通义千问专区 Qwen 模型本地部署宝库 Ollama 库中 Qwen 模型页面 Qwen 开源代码探索秘境 GitHub - Qwen 相关仓库 Qwen 模型评测研讨高地 Hugging Face - Qwen 模型相关讨论和评测 DeepSeek 联网本地化部署攻略阁 【deepseek - 002】windows + ollama + deepseek - r1 + Page Assist本地化部署(含联网黑科技) DeepSeek 离线本地化部署领航舱 【deepseek - 001】windows + ollama + deepseek - r1 + chatbox本地化部署(离线,零基础保姆级教程)
宝子们,都看到这儿啦,赶紧动手试试吧!要是在部署过程中有啥问题,评论区留言,咱们一起解决💬,期待大家都能成功部署属于自己的 Qwen 大模型🎉



















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











