







环境准备
确保安装了Python以及requests和BeautifulSoup库。
pip install requests beautifulsoup4
确定爬取目标
选择一个含有SCI论文的网站,了解该网站的内容布局和数据结构。
(1)在浏览器中访问目标网站,右键点击页面并选择“检查”或使用快捷键(如Chrome浏览器的Ctrl+Shift+I)打开开发者工具。
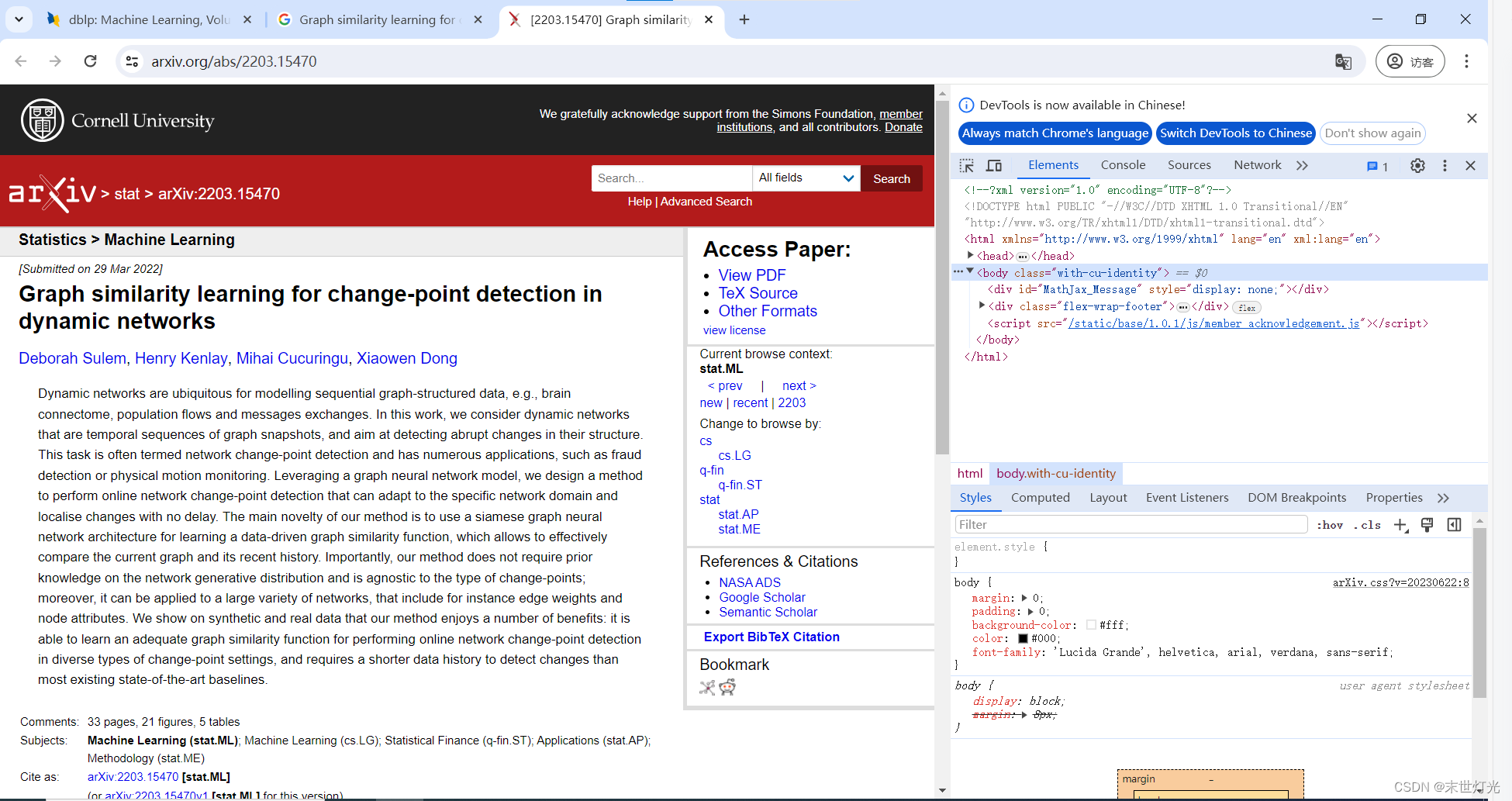
(2)在“元素”标签页中查看HTML源代码,寻找包含论文信息的部分。
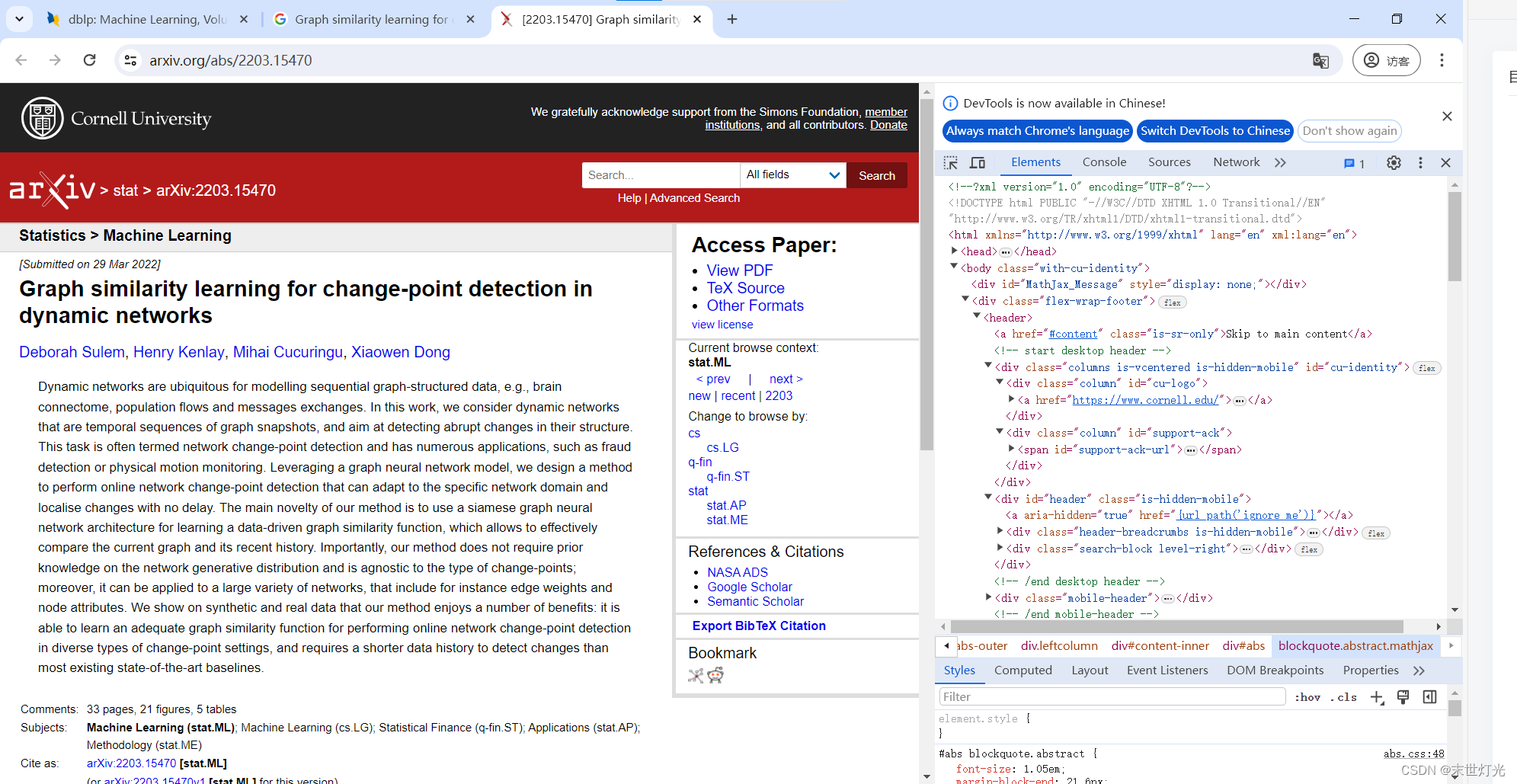
(3)使用开发者工具的选择功能,点击页面中的论文标题或其他元素,开发者工具会直接高亮显示该元素在HTML中的位置。
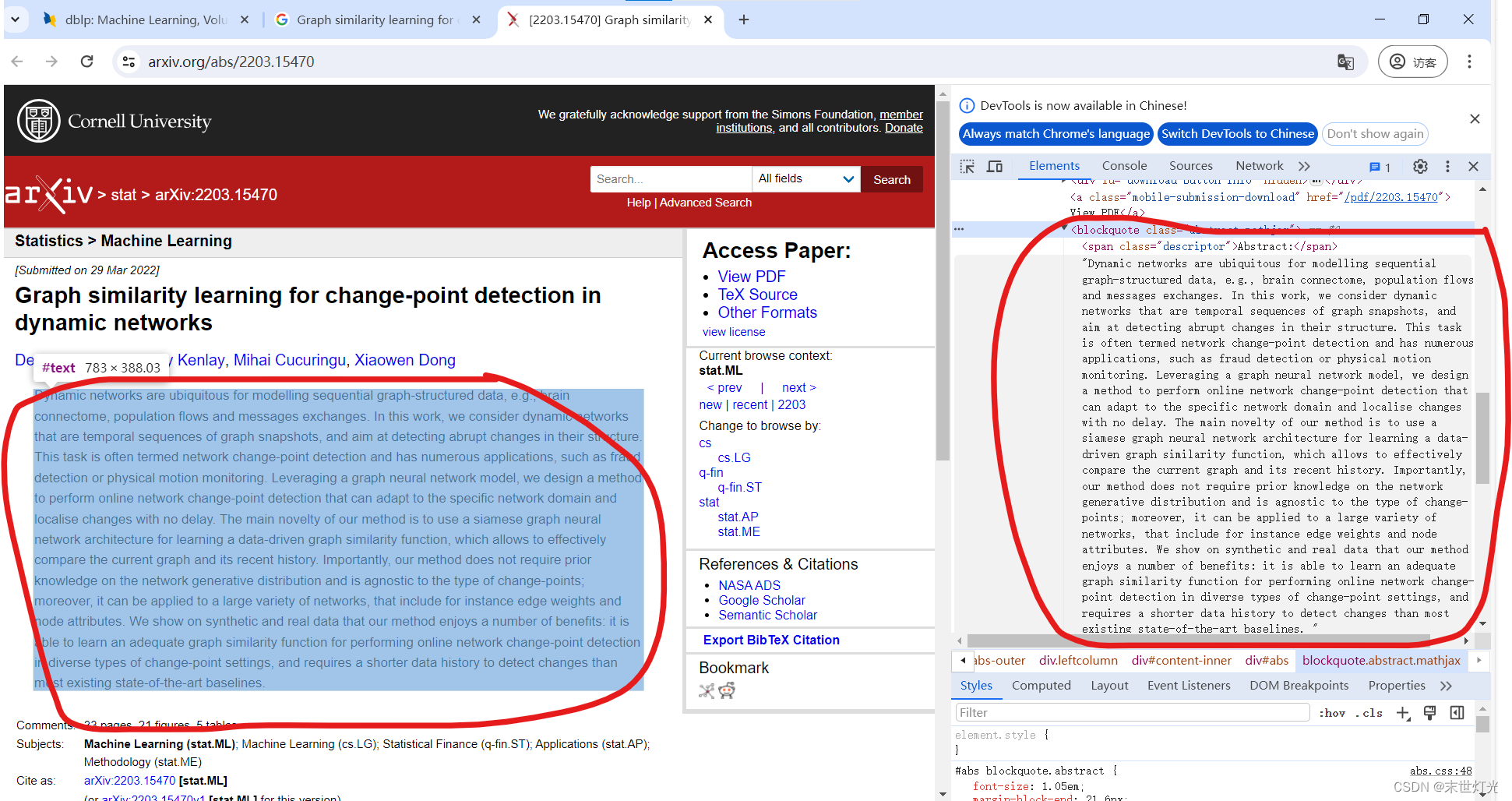
(4)别论文信息所在的HTML标签和类名(class),这些信息将在之后的爬虫脚本中用来定位和提取数据。
<blockquote class="abstract mathjax">
<span class="descriptor">Abstract:</span>Dynamic networks are ubiquitous for modelling sequential graph-structured data, e.g., brain connectome, population flows and messages exchanges. In this work, we consider dynamic networks that are temporal sequences of graph snapshots, and aim at detecting abrupt changes in their structure. This task is often termed network change-point detection and has numerous applications, such as fraud detection or physical motion monitoring. Leveraging a graph neural network model, we design a method to perform online network change-point detection that can adapt to the specific network domain and localise changes with no delay. The main novelty of our method is to use a siamese graph neural network architecture for learning a data-driven graph similarity function, which allows to effectively compare the current graph and its recent history. Importantly, our method does not require prior knowledge on the network generative distribution and is agnostic to the type of change-points; moreover, it can be applied to a large variety of networks, that include for instance edge weights and node attributes. We show on synthetic and real data that our method enjoys a number of benefits: it is able to learn an adequate graph similarity function for performing online network change-point detection in diverse types of change-point settings, and requires a shorter data history to detect changes than most existing state-of-the-art baselines.
</blockquote>发送HTTP请求
import requests
url = "目标网站的URL"
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
print("请求成功")
else:
print("请求失败")
这里,requests.get(url)发送一个GET请求到指定的URL,response.status_code检查响应状态码。
解析网页内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')使用BeautifulSoup解析服务器响应的HTML内容。response.text包含了网页的文本数据。
数据提取
从网页中提取有用信息,如论文的标题、作者、摘要等。
papers = soup.find_all("div", class_="paper")
for paper in papers:
title = paper.find("h2").text
authors = paper.find("span", class_="authors").text
abstract = paper.find("div", class_="abstract").text
print(f"标题:{title}\n作者:{authors}\n摘要:{abstract}")find_all查找包含论文信息的所有div元素,text属性用来获取元素中的文本。
存储数据
将提取的数据保存到本地文件或数据库。
with open("papers.txt", "w") as file:
for paper in papers:
file.write(f"标题:{title}\n作者:{authors}\n摘要:{abstract}\n\n")使用with语句确保文件正确关闭,file.write将信息写入文件。
这个流程详尽地介绍了如何通过编程自动化地从网站上获取科研论文的信息,有助于读者学习和实践网络爬虫技术。


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











