







Spatial pyramid pooling in deep convolutional networks for visual recognition
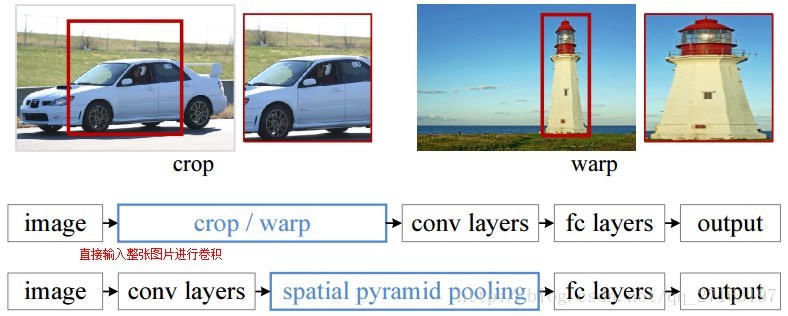
说明:compute the feature maps from the entire image only once, and then pool features in arbitrary regions (sub-images) to generate fixed-length representations for training the detectors.
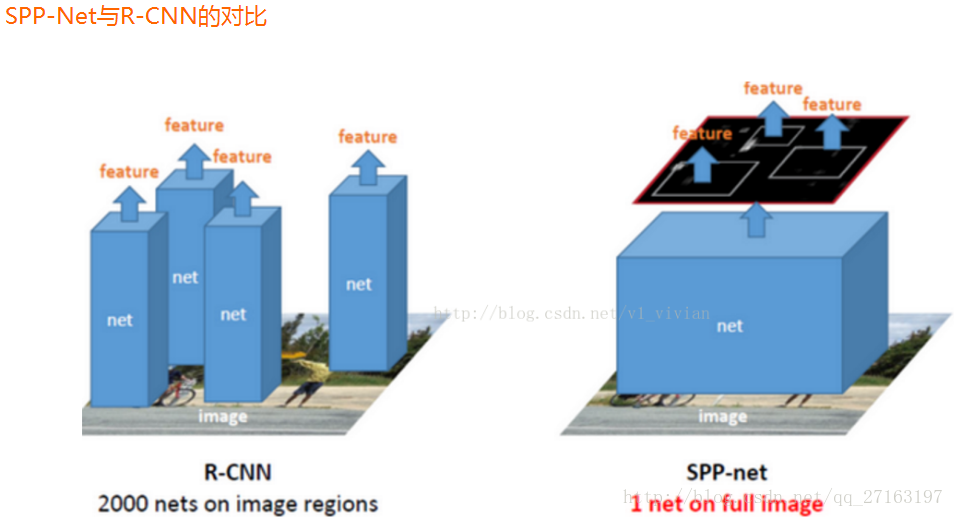
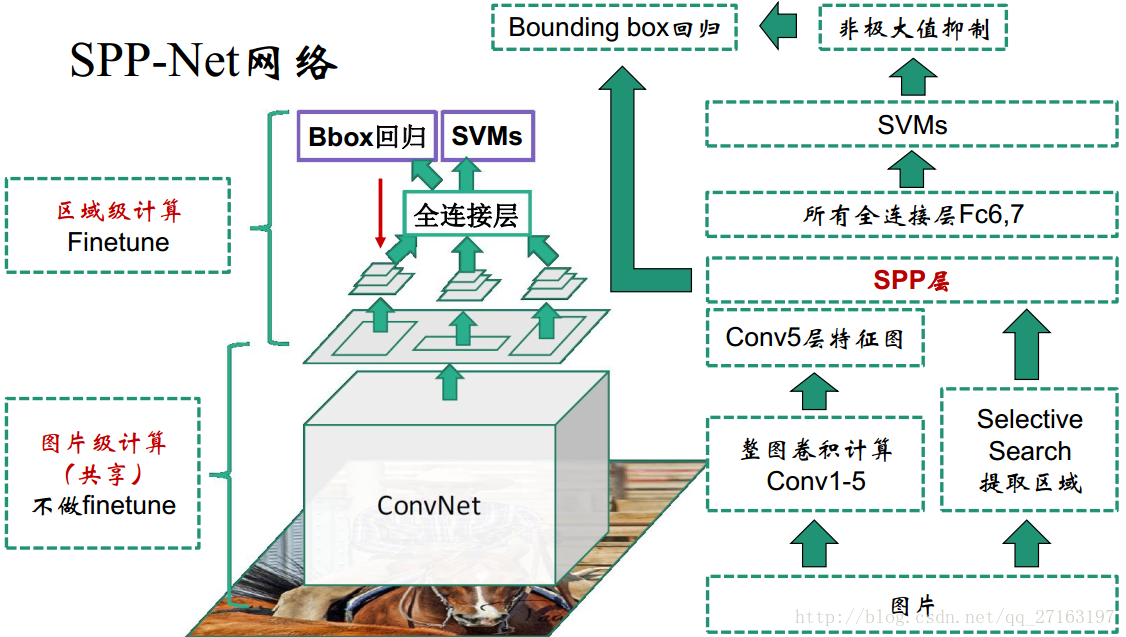
Introduction
直接输入整图,所有区域共享卷积计算;在Conv5层输出上提取所有区域的特征
spatial pyramid pooling (SPP)【空间金字塔池化】
1,The SPP layer pools the features and generates fixed length outputs, which are then fed into the fully connected layers (or other classifiers)。[替换Conv5的Pooling层]
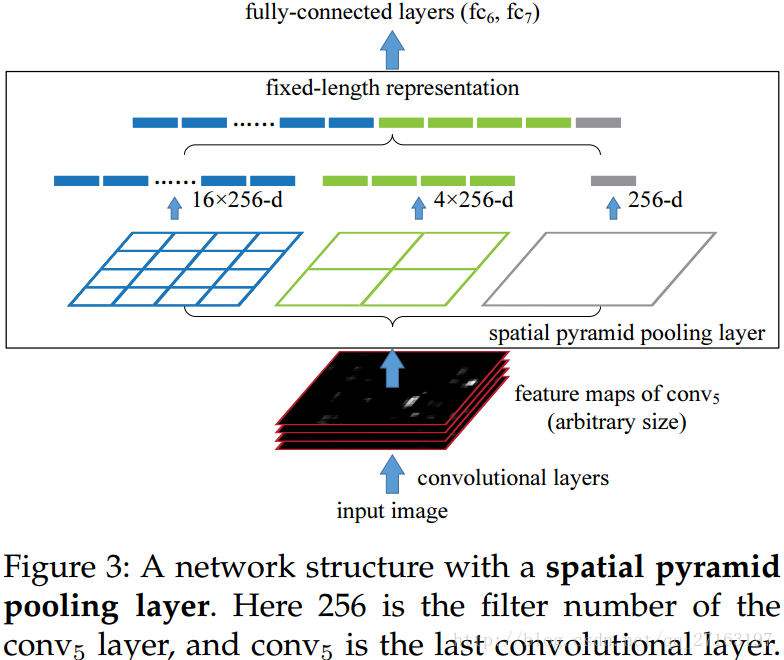
Training the Network
1,Single-size training:
a fixed-size input (224×224) cropped。

2,Multi-size training
We consider two sizes: 180×180 in addition to 224×224. Rather than crop a smaller 180×180
region, we resize the aforementioned 224×224 region to 180×180.
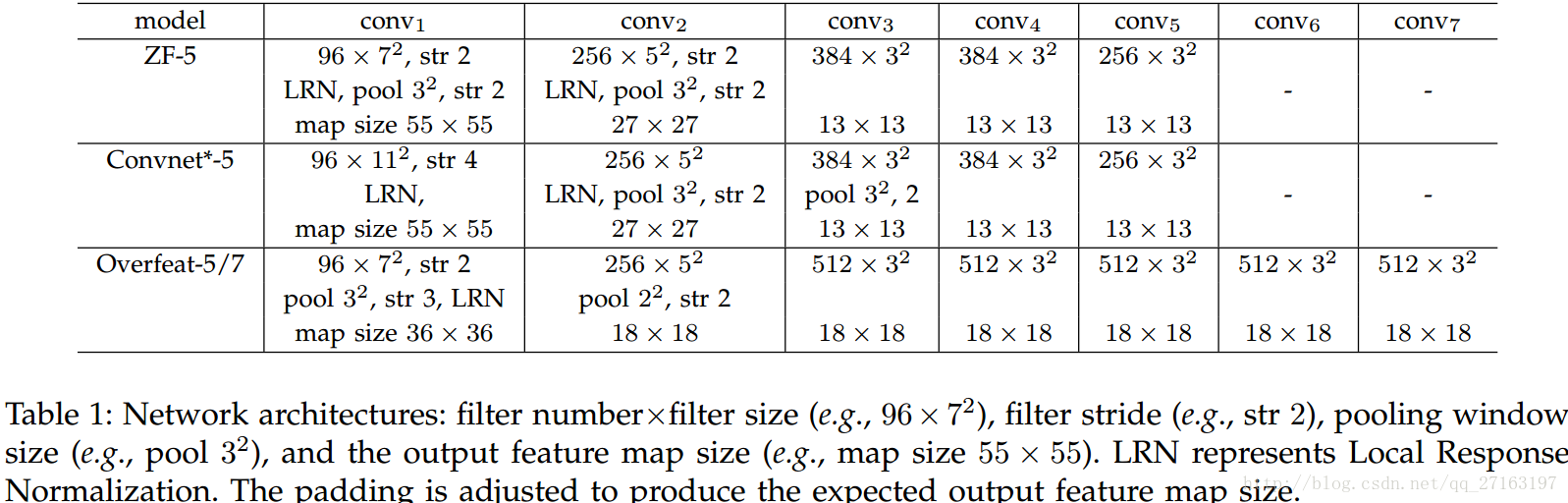

问题
继承了R-CNN的剩余问题:需要存储大量特征+复杂的多阶段训练+训练时间仍然长
新问题:SPP层之前的所有卷积层参数不能finetune















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









