







在动态SLAM中,只需要调用yolo训练好的模型就可以实现动态目标检测。本文用于总结使用yolo模型的基本逻辑。
(1)加载yolo模型
(2)获取模型输出
(3)后处理
(4)提取检测框
一类方法使用TorchScript, TorchScript允许在不依赖 Python 解释器的情况下运行模型,从而实现模型的跨平台部署和优化。这类方法使用的是.pt文件。
还有一类方法,使用opencv DNN模块调用YOLO模型。这类方法使用的是Darknet架构的YOLO,使用的是.cfg和.weights文件。对于slam调用yolo,我只在一些比较早的项目(与yolov3,yolov5结合)里看到有用这种方法的。
(1)加载yolo模型
在YoloDetect.h里,使用torch::jit::script::Module创建module对象用以加载模型。
torch::jit::script::Module mModule;YoloDetect.cpp
构造函数:
YoloDetection::YoloDetection()
{
mModule = torch::jit::load("/home/slam/YOLO_ORB_SLAM3/yolov5s.torchscript.pt");
std::ifstream f("/home/slam/YOLO_ORB_SLAM3/coco.names");
std::string name = "";
while (std::getline(f, name))
{
mClassnames.push_back(name);
}
mvDynamicNames = {"person", "car", "motorbike", "bus", "train", "truck", "boat", "bird", "cat",
"dog", "horse", "sheep", "crow", "bear"};
}构造函数主要实现两个功能:
①加载yolo模型.pt文件
②读取包含分类名称的文件coco.names
上述代码是用PyTorch C++ API(LibTorch)加载 .pt 文件,也有一些项目使用的是darknet架构的yolo,可以用opencv的dnn模块加载.weights和.cfg文件。
String modelConfiguration = "src/yolo/yolov3.cfg";
String modelWeights = "src/yolo/yolov3.weights";
// Load the network
net = readNetFromDarknet(modelConfiguration, modelWeights);(2)获取模型输出
在 YoloDetect.cpp中
①将图片转换成张量
②调用forward函数,进行目标检测。

③将模型的输出转换为张量
②③用以下函数实现
torch::Tensor preds = mModule.forward({imgTensor}).toTuple()->elements()[0].toTensor();(3)后处理
后处理多采用非极大值抑制的方法删除置信度低或者重叠的检测框。
std::vector<torch::Tensor> dets = YoloDetection::non_max_suppression(preds, 0.4, 0.5);这时候操作的仍然是张量。
(4)提取检测框
在 YoloDetect.h中,定义一个存储cv::Rect2i对象的数组,用于存储动态物体检测框的坐标。
Opencv数据类型(二):Rect类和RotatedRect类_cv::rotatedrect-CSDN博客
vector<cv::Rect2i> mvDynamicArea;上面(2)(3)中,操作的都是张量。
在torch中,用封装好的Tensor类型表示:
torch::Tensor preds;在opencv中,用多层的矩阵模拟:
vector<Mat> outs;其实,从OpenCV模拟张量的方式,我们就可以看出,张量,简单说,就是一个多维的信息(这里是三维)、多层的矩阵,如图所示。我们不需要深究,只需要知道每一维度在这里代表什么。
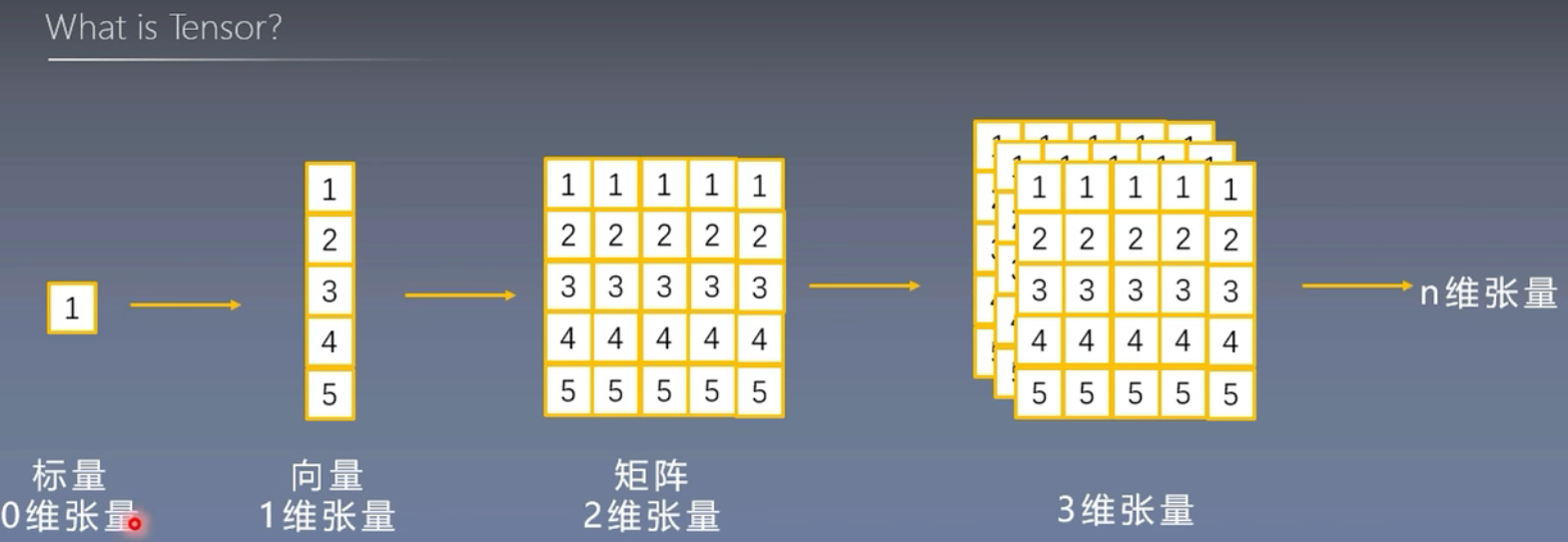
对于一个Tensor张量dets[x][y][z];
- 第一维:批次维度,表示图像数量(通常为 1)。
- 第二维:预测框维度,表示模型生成的所有边界框(例如 15120 个预测框)。
- 第三维:每个预测框包含的值(例如坐标、置信度、类别)。
第一维无需在意,因为在这里只处理一张图片。我们需要的信息是:
①检测框的编号,也就是我们需要遍历图片中的每一个检测框。dets[x][y][z];
②检测框的坐标和类别信息,这个都存储在第三维里。dets[x][y][z];
知道了这些,如何提取检测框坐标和物体类别就变得很清晰了。
float left = dets[0][i][0].item().toFloat() * mRGB.cols / 640;
float top = dets[0][i][1].item().toFloat() * mRGB.rows / 384;
float right = dets[0][i][2].item().toFloat() * mRGB.cols / 640;
float bottom = dets[0][i][3].item().toFloat() * mRGB.rows / 384;
int classID = dets[0][i][5].item().toInt();知道了检测框的坐标,存储在对象DetectArea里。
cv::Rect2i DetectArea(left, top, (right - left), (bottom - top));经过上述步骤,获取了yolo检测到的目标检测框,可以用于SLAM的目标检测。


















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









