







作者栏fanqi
随着 Meta 在今天放出了 LLaMA3.2 系列模型,LLaMA 系列也是正式迎来了官方版本的多模态大模型 LLaMA3.2-Vision [1]。那我们就在本期内容中聊一聊 LLaMA3.2-Vision 模型的结构,希望对大家有所帮助。
相关代码位于 [2]
结论
先说结论,LLaMA3.2 的整体结构与 Flamingo 相似,均是采用交叉注意力的方式进行模态融合。而 projector 也仅仅由一个线性层组成。
LLaMA3.2-Vision-11B 的 ViT 参数量仅有 800M,projector 的参数量为 31M,而 LLM 部分的参数量来到了 9775 M。
具体结构
Vision Encoder
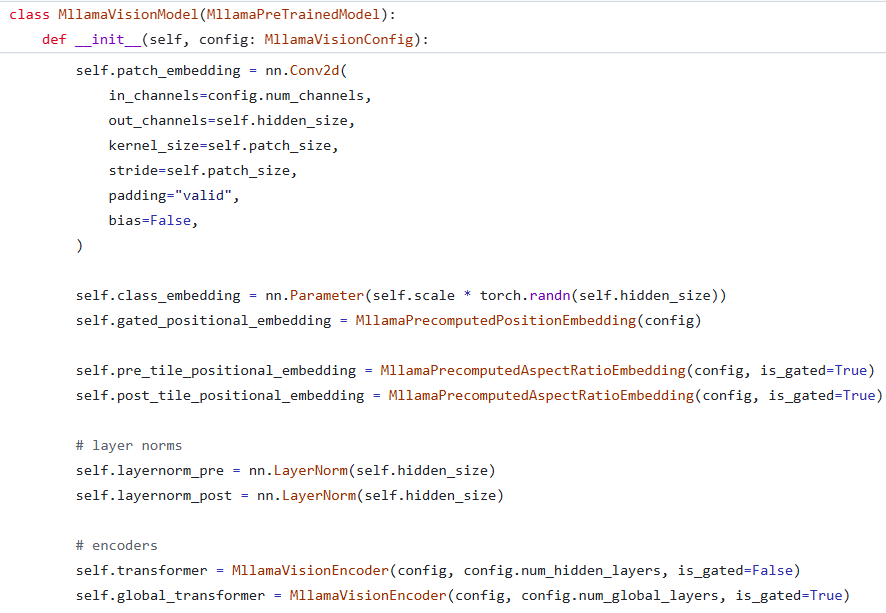
先来看 Vision Encoder 部分。尽管 Vision Encoder 整体上还是 ViT 架构,但却比一般的 ViT 多出了很多东西,比如 gated_positional_embedding、pre_tile_positional_embedding 和 post_tile_positional_embedding。此外,最与众不同的一点便是,Vision Encoder 中包含两部分编码器,分别为 transformer 和 global_transformer。
在推理时,图片会首先经过 processor 进行处理。在对其进行 reshape 后,便会对其进行 PatchEmbedding 操作。但此时并不会直接叠加位置编码,而是再次 reshape,之后再叠加 pre_tile_positional_embedding。随后 reshape 回到叠加 pre_tile_positional_embedding 前的形状,并叠加 class_token。在这之后,再次 reshape 并叠加 gated_positional_embedding。完成这一切过后便是对于输入的 pad 过程。在准备好对于输入图片比例的 attention_mask 后,输入会通过 transformer 得到第一份输出。然后将这份输出 reshape 并叠加 post_tile_positional_embedding,随后经过 global_transformer 得到其最终输出与中间状态。在将最终输出与中间状态叠加后,Vision Encoder 完成了其输出。
接下来,我们来看三个 positional_embedding 之间的区别。代码是这样定义的:
self.gated_positional_embedding = MllamaPrecomputedPositionEmbedding(config)
self.pre_tile_positional_embedding = MllamaPrecomputedAspectRatioEmbedding(config, is_gated=True)
self.post_tile_positional_embedding = MllamaPrecomputedAspectRatioEmbedding(config, is_gated=True)可以看到,三个 positional_embedding 之间存在明显差别。其中 pre_tile_positional_embedding 和 post_tile_positional_embedding 主要是对于图像的宽高比进行编码,而 gated_positional_embedding 更像是传统意义上的位置编码。
最后是 transformer 与 global_transformer 的不同。global_transformer 启用了 gated 参数,这会使得 MllamaVisionEncoderLayer 的行为不同。具体来讲,在启用 gated 时,MllamaVisionEncoderLayer 会有两个可学习的参数,分别用于控制 attention 层的输出 scale 和 ffn 层的输出 scale。
LLM
然后是 LLM 部分。LLM 部分与 Flamingo 中所使用的 LLM 相似,即部分层使用 CrossAttention 而非 SelfAttention。此处不过多赘述 CrossAttention 的原理了。此处附上一张 Flamingo 的示意图。但与 Flamingo 不同的点在于,LLaMA3.2-Vision 并非把所有层都用 CrossAttention 替代了 SelfAttention。
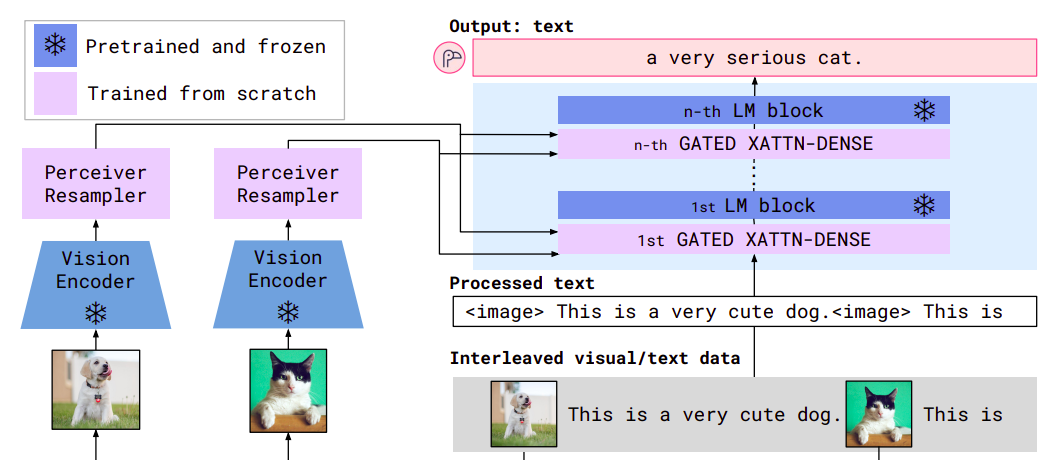
在推理时,CrossAttention 层会接受来自 projector 的输出,并依此得到 K 和 V,接受原本输入得到 Q 进行注意力的计算。
完整推理过程
在看完了 Vision Encoder 和 LLM 的细节后,我们来整体看一下 LLaMA3.2-Vision 的推理过程吧。
首先,图片会通过 Vision Encoder 得到输出。这些输出会经过投影层转换维度后,作为 LLM 中的 CrossAttention 层的 cross_attention_states。随后,文本部分会经过 tokenizer 直接输入给 LLM,并在 cross_attention_states 的作用下完成推理,实现文本模态的输出。值得注意的一点是,这一过程中并没有发生把图片 embedding 转换为文本 embedding 并拼接,作为 LLM 输出的过程。(即 LLaVA 类似推理过程)
[1]: https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct
[2]:https://github.com/huggingface/transformers/blob/main/src/transformers/models/mllama/modeling_mllama.py

















 2061
2061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









