







今天Qwen团队发布"Qwen2.5 Technical Report" 的技术报告,下面对该报告做了简单的概括,希望让大家有个快速了解。
LLM所有细分方向群+ACL25/ICML25/NAACL25投稿群->LLM所有细分领域群、投稿群从这里进入!
链接:https://arxiv.org/pdf/2412.15115
摘要
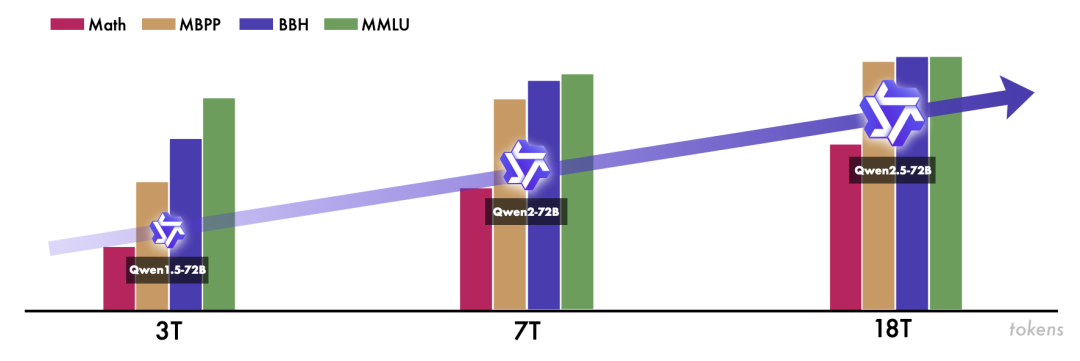 Qwen2.5 是一系列大型语言模型(LLMs),旨在满足多样化的需求。与之前的版本相比,Qwen 2.5 在预训练和后训练阶段都得到了显著改进。预训练数据集从之前的7万亿个token扩展到18万亿个token,这为模型提供了坚实的常识、专家知识和推理能力基础。后训练阶段包括超过100万个样本的复杂监督微调和多阶段强化学习,显著提升了模型的人类偏好对齐、长文本生成、结构数据分析和指令遵循能力。
Qwen2.5 是一系列大型语言模型(LLMs),旨在满足多样化的需求。与之前的版本相比,Qwen 2.5 在预训练和后训练阶段都得到了显著改进。预训练数据集从之前的7万亿个token扩展到18万亿个token,这为模型提供了坚实的常识、专家知识和推理能力基础。后训练阶段包括超过100万个样本的复杂监督微调和多阶段强化学习,显著提升了模型的人类偏好对齐、长文本生成、结构数据分析和指令遵循能力。
Qwen2.5 系列特点
丰富的配置:提供从0.5B到72B参数的不同大小的基础模型和指令调整模型,以及量化版本。
性能表现:在多个基准测试中表现出色,特别是在语言理解、推理、数学、编码和人类偏好对齐等方面。
模型规模:Qwen2.5-72B-Instruct 在性能上与比它大5倍的 Llama-3-405B-Instruct 竞争。
架构与分词器
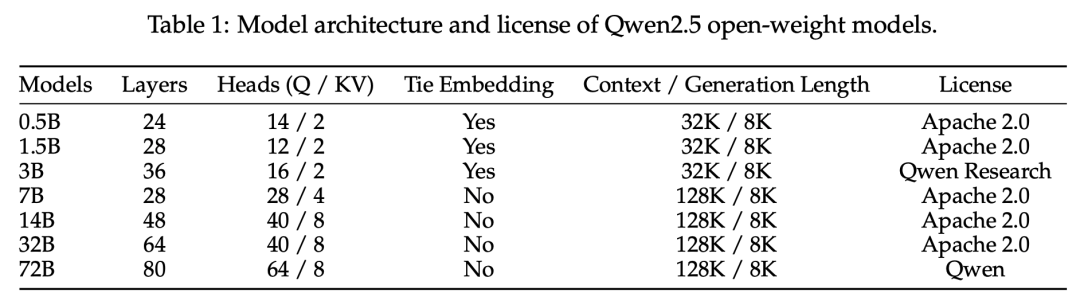 Qwen2.5 系列包括基于 Transformer 的密集模型和用于 API 服务的 MoE(专家混合)模型。模型架构包括分组查询注意力、SwiGLU 激活函数、旋转位置嵌入等。分词器使用字节级别的字节对编码(BBPE),词汇量为151,643个常规token。
Qwen2.5 系列包括基于 Transformer 的密集模型和用于 API 服务的 MoE(专家混合)模型。模型架构包括分组查询注意力、SwiGLU 激活函数、旋转位置嵌入等。分词器使用字节级别的字节对编码(BBPE),词汇量为151,643个常规token。
预训练
预训练数据质量得到显著提升,包括更好的数据过滤、数学和代码数据的整合、合成数据的生成和数据混合。预训练数据从7万亿token增加到18万亿token。
后训练
Qwen 2.5 在后训练设计上引入了两个重要进展:扩展的监督微调数据覆盖和两阶段强化学习(离线和在线)。
评估
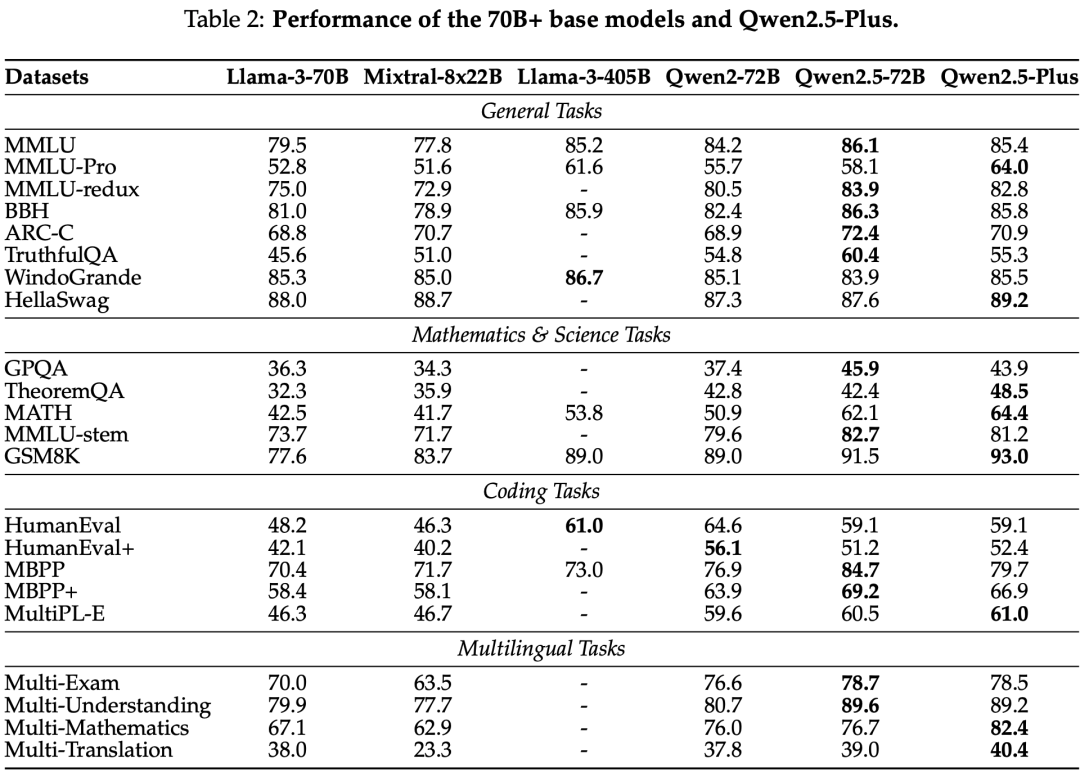
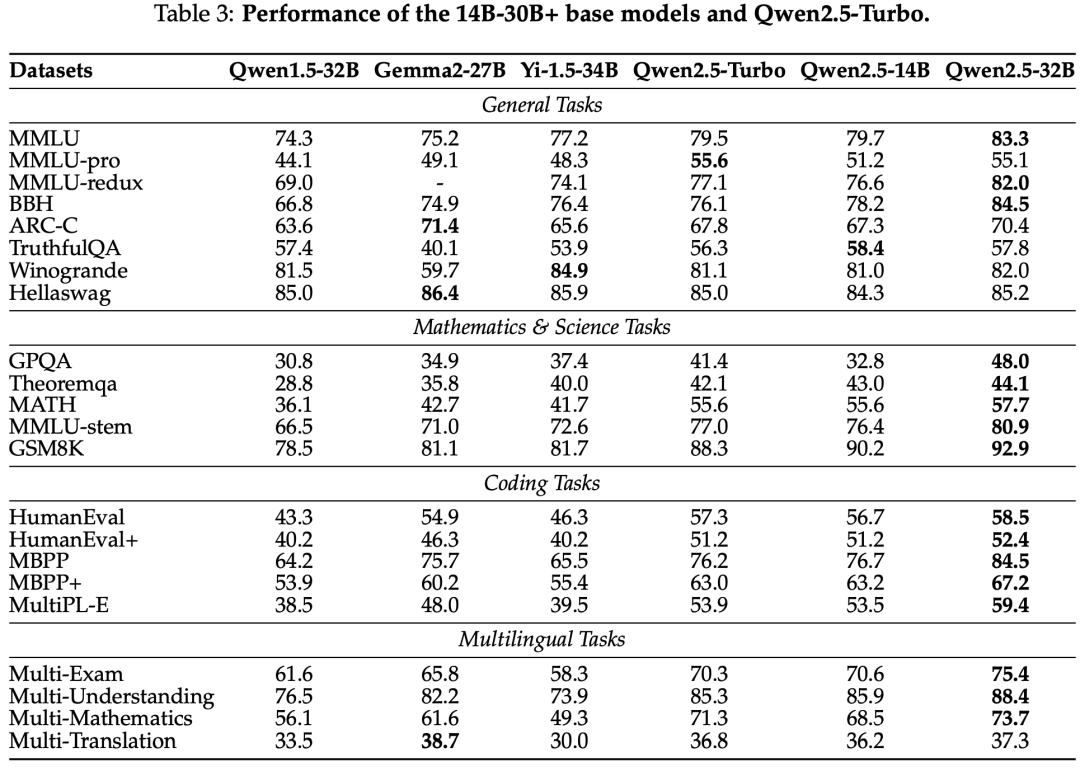
Qwen2.5 系列模型在多个基准测试中进行了评估,包括自然语言理解、编程、数学和多语言能力。Qwen2.5-72B 和 Qwen2.5-Plus 在多个任务中表现出色,与领先的开放权重模型竞争。
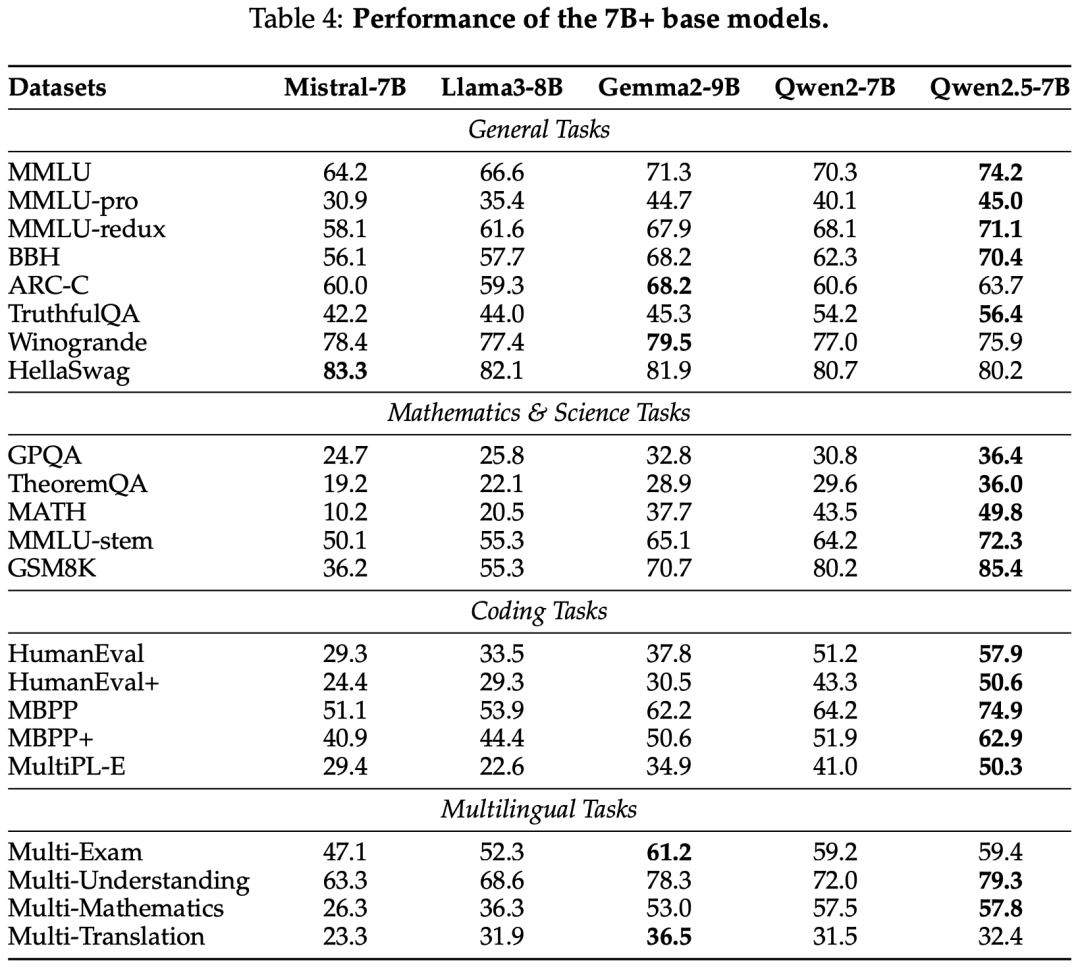
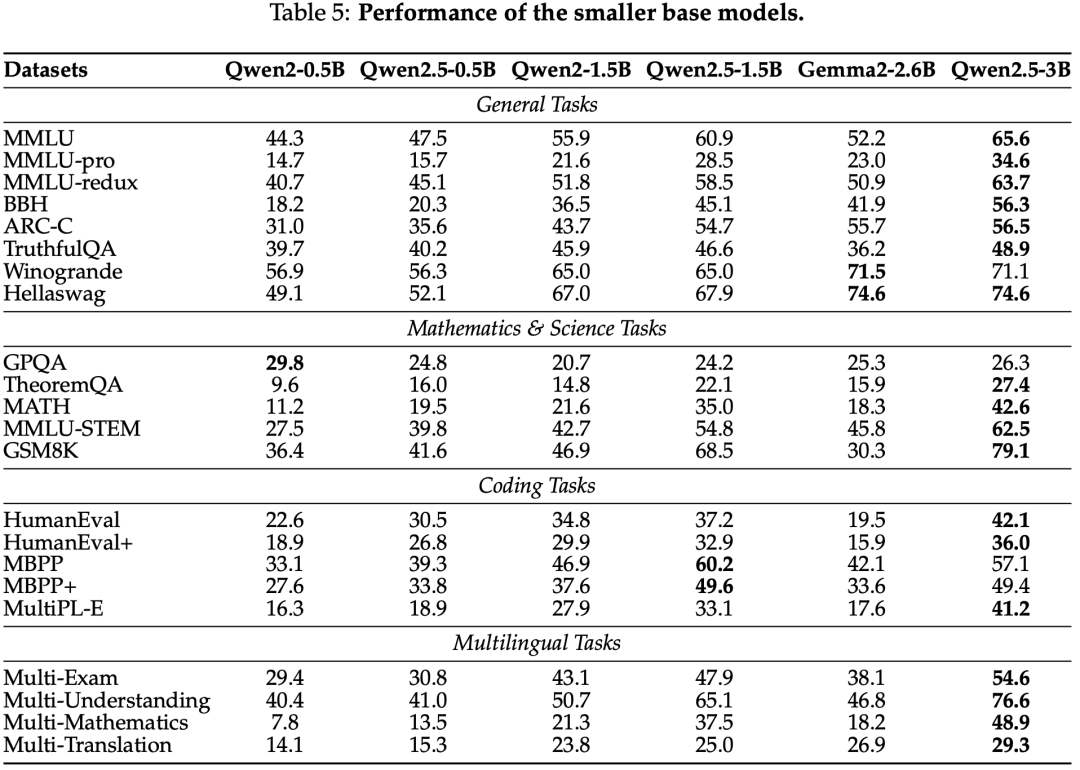
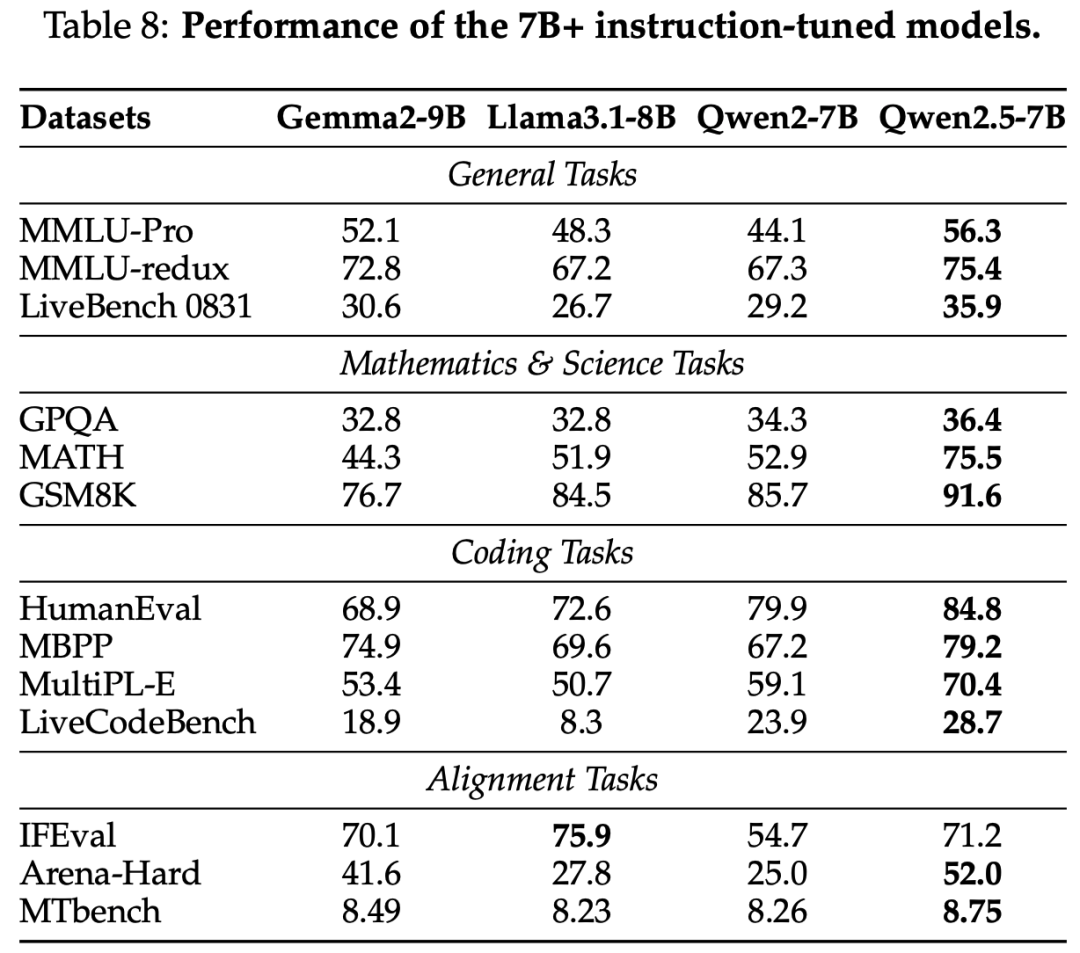
base model
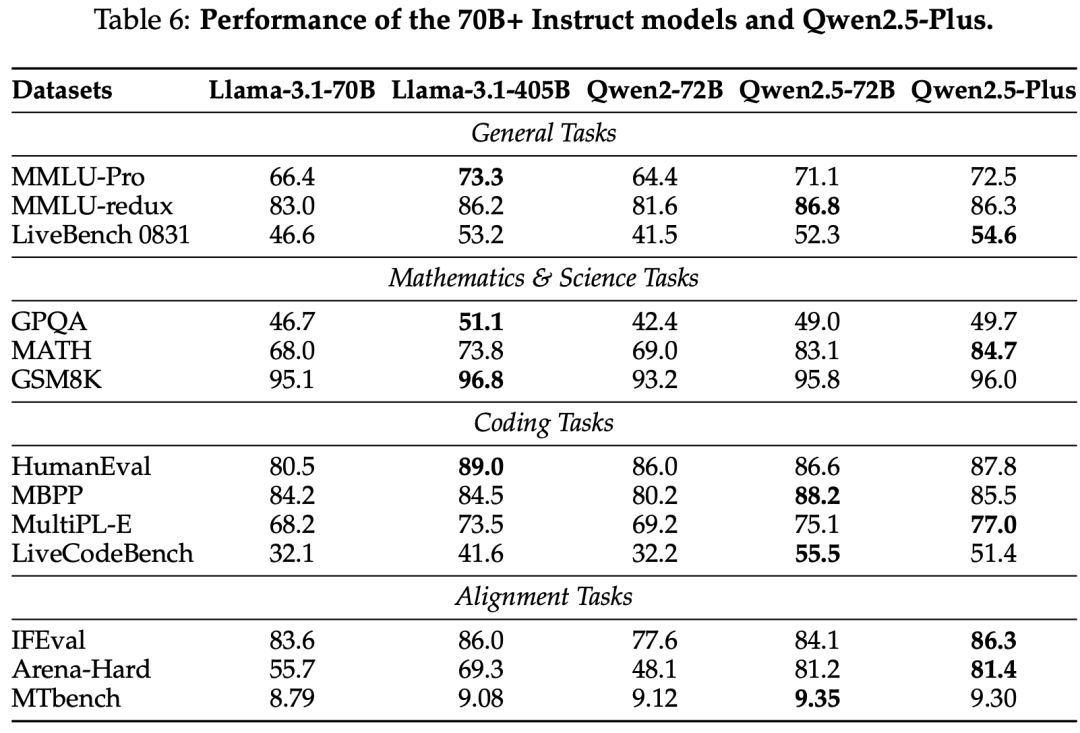
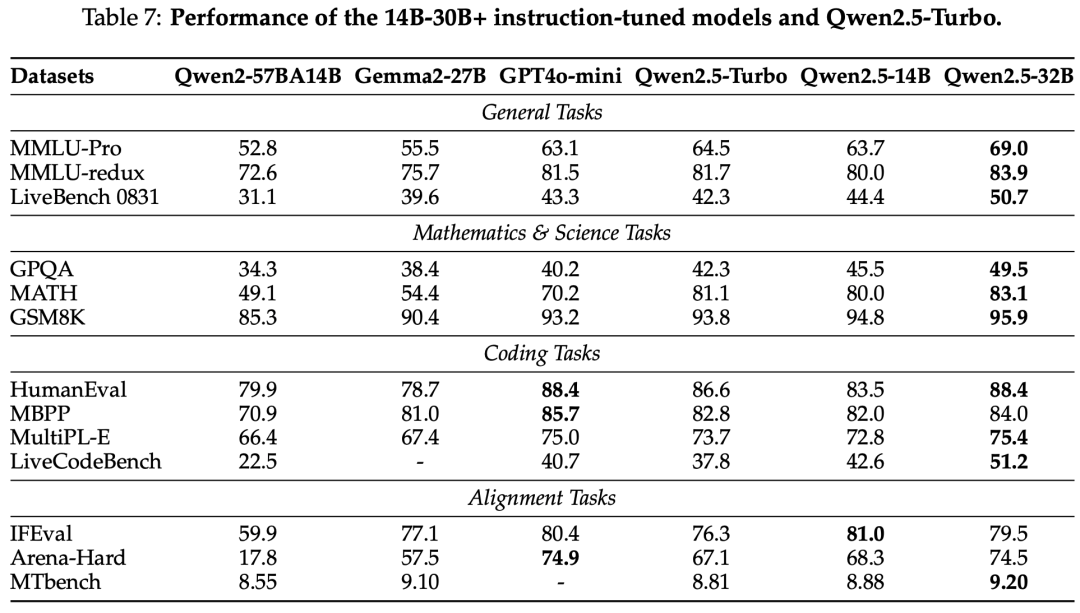
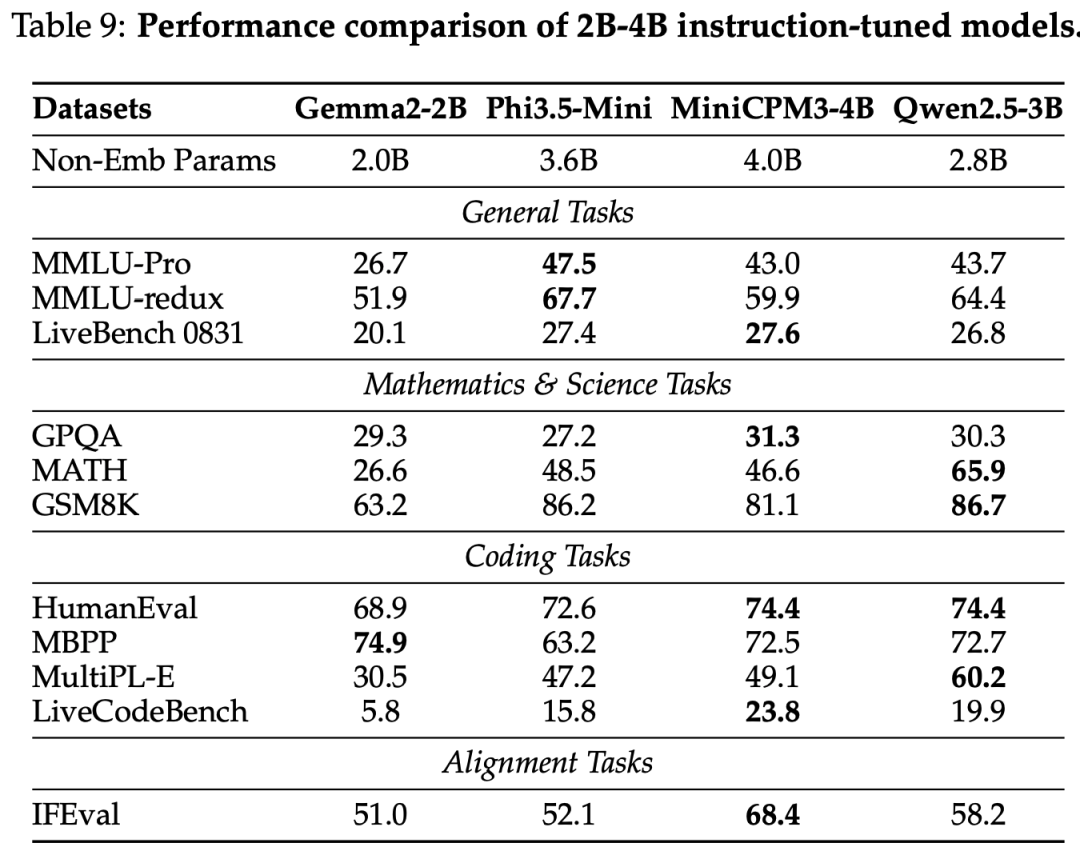
instruct model
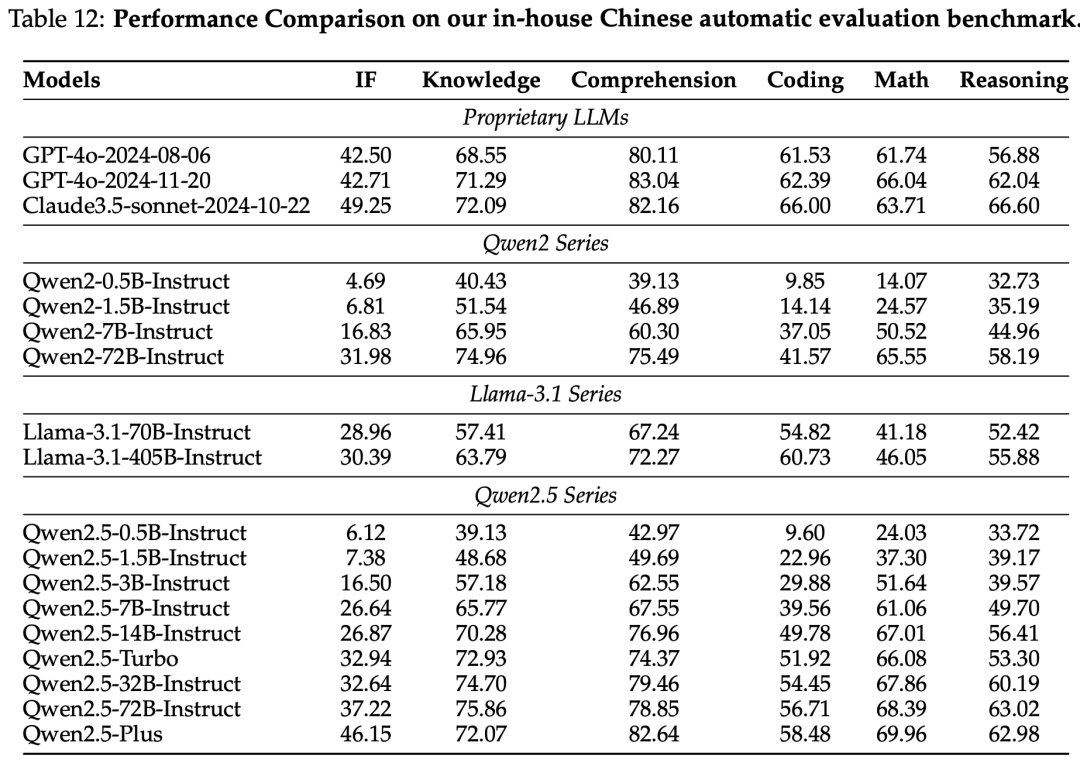
on our in-house Chinese automatic evaluation
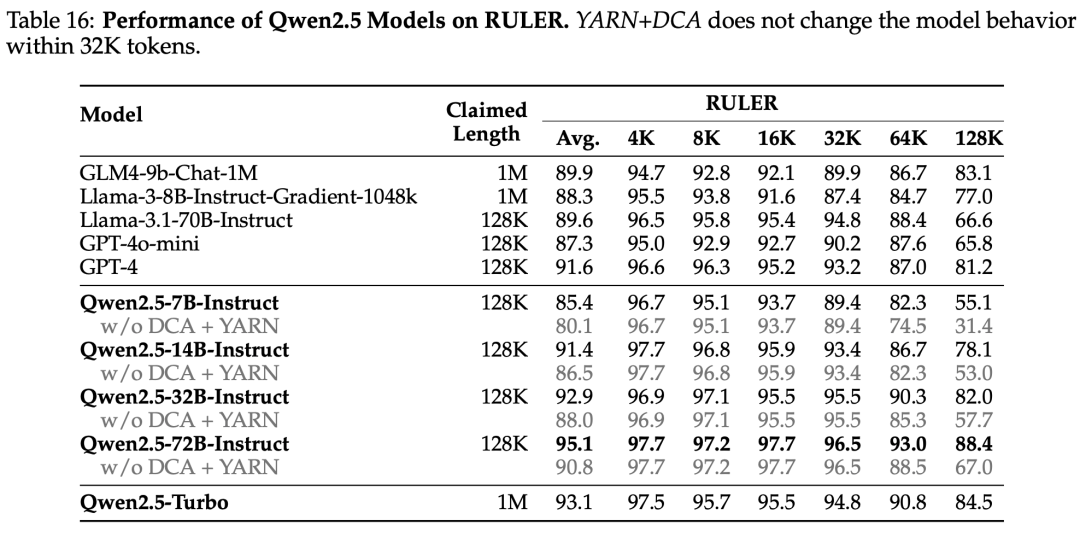
长文本
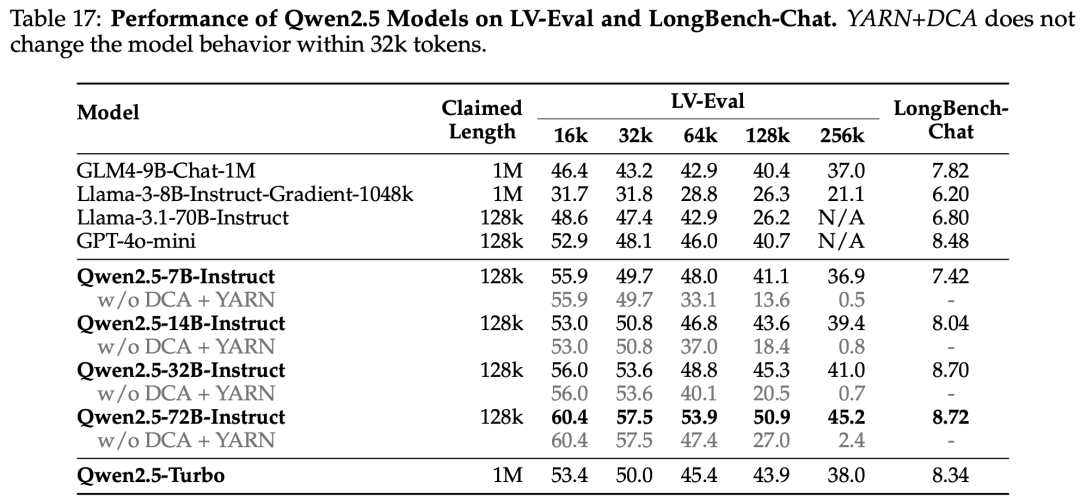
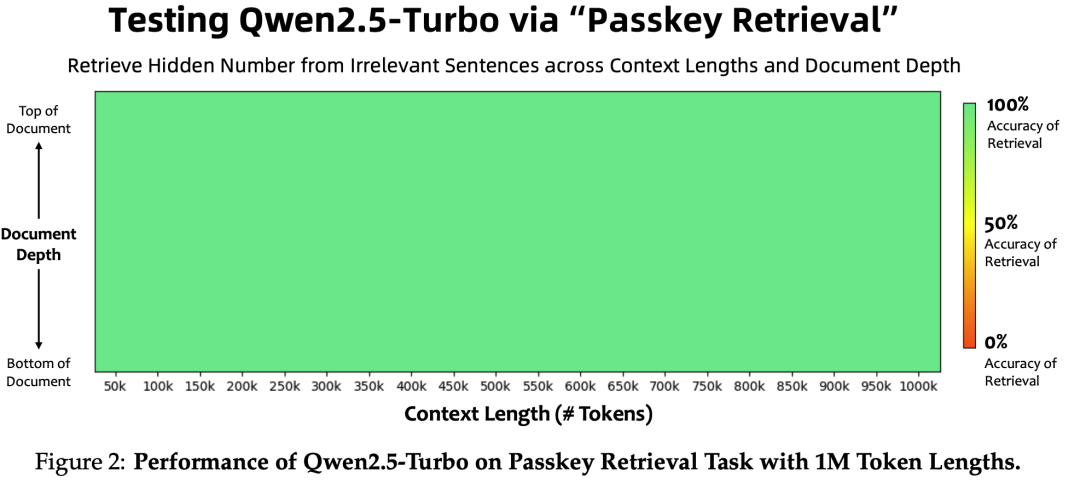
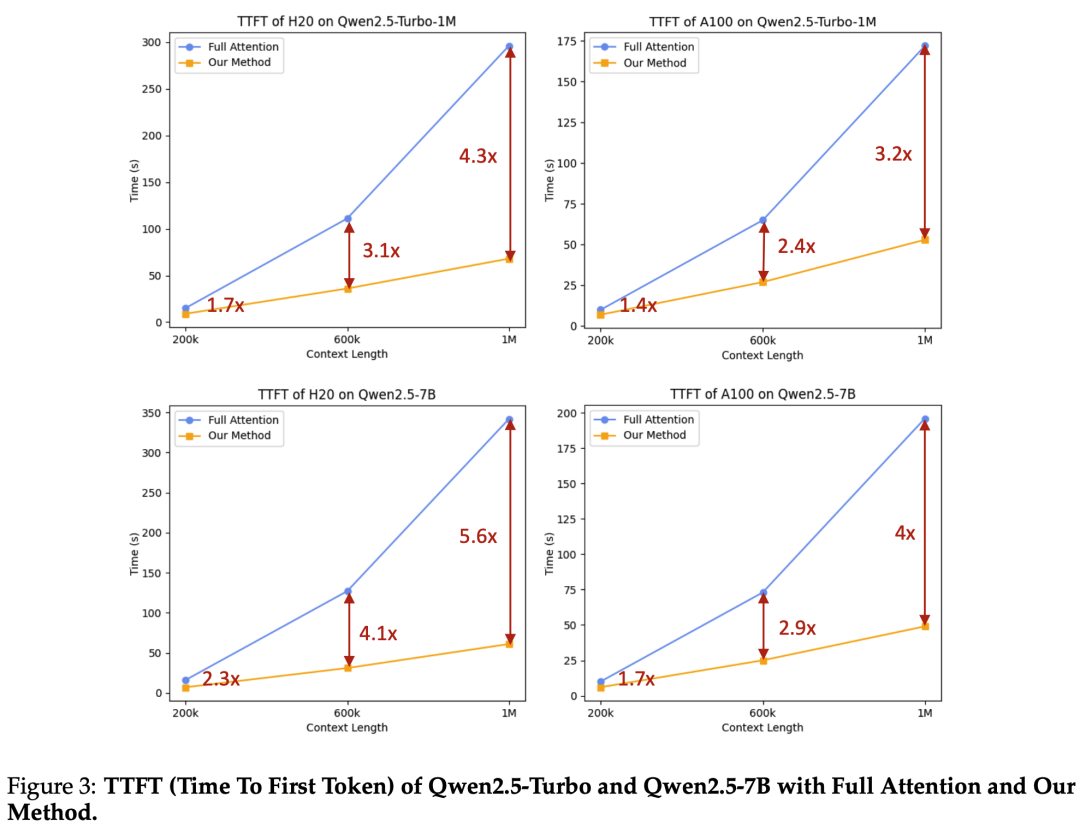
结论
Qwen2.5 代表了大型语言模型的重大进步,提供了多种配置,并且在多个基准测试中表现出色。Qwen2.5 的强大性能、灵活架构和广泛可用性使其成为学术研究和工业应用的宝贵资源。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









