







RetinaNet
论文
Focal Loss for Dense Object Detection
模型结构
RetinaNet是一种基于特征金字塔网络(Feature Pyramid Network)和Focal Loss损失函数的目标检测模型,由Facebook AI Research团队在2018年提出。RetinaNet旨在解决传统目标检测算法(如Faster R-CNN)在检测小目标时表现不佳的问题。与传统的目标检测算法相比,RetinaNet具有更高的检测精度和更快的检测速度。它对小目标的检测表现尤为优秀,在各种视觉任务中都取得了很好的效果,例如物体检测、行人重识别等。
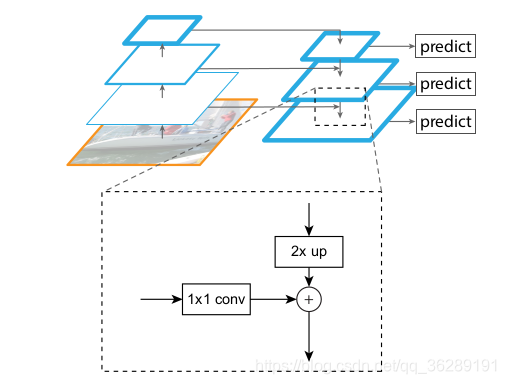
RetinaNet的网络结构主要分为两个部分:特征提取网络和检测头。
- 特征提取网络:RetinaNet采用了ResNet作为特征提取网络,通过不同深度的ResNet模块对输入图像进行特征提取,得到一系列的特征金字塔图。这些特征金字塔图代表了不同尺度的物体信息,可以用于检测不同大小的目标。
- 检测头:RetinaNet的检测头由两个分支组成,一个分支用于预测目标的置信度,另一个分支用于预测目标的边界框。每个分支都由一系列卷积层和全连接层组成,最终输出一个特定数量的预测值。置信度分支使用Focal Loss损失函数来处理正负样本不均衡问题,边界框分支使用Smooth L1 Loss损失函数来计算边界框的误差。
在检测过程中,RetinaNet首先在特征金字塔图上进行目标检测,然后在检测结果中使用非极大值抑制(NMS)来消除重叠的边界框,并保留置信度最高的边界框。

算法原理
RetinaNet网络即ResNet+FPN+FCN网络的组合,损失函数为Focal loss也是one-stage的目标检测算法,最大的贡献就是解决了前景背景种类不均衡问题,让one-stage算法的精度也能达到two-stage的水平。主要是通过重塑了标准的交叉熵损失函数,以减少对容易分类例子的损失,并由此提出来一种新的损失函数Focal Loss,这个损失函数的出现就是为了解决在训练过程中一些稀疏难以区分的样本,可能会被大量容易区分的消极样本压倒的问题。
RetinaNet的主网络部分采用的是FPN结构,两个不同任务的子网络,一个是分类网络,一个是位置回归网络。
环境配置
Docker (方法一)
提供光源拉取的训练的docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/custom:mlperf_retinanet_mpirun
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
docker run -it --name mlperf_retinanet --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
Dockerfile (方法二)
docker build --no-cache -t mlperf_retinanet:latest .
docker run -it --name mlperf_retinanet --shm-size=32G --device=/dev/kfd --device=/dev/dri/ --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --ulimit memlock=-1:-1 --ipc=host --network host --group-add video -v <Host Path>:<Container Path> <Image ID> /bin/bash
# <Image ID>用上面拉取docker镜像的ID替换
# <Host Path>主机端路径
# <Container Path>容器映射路径
镜像版本依赖:
- DTK驱动:dtk22.10
- python: python3.7.12
测试目录
/root/RetinaNet
数据集
模型训练的数据集来自训练数据:Open Images,该数据一个大规模的图像数据集,由Google在2016年发布。该数据集包含了超过900万张标注图像,其中每张图像都包含了多个物体的边界框和类别标签,可用于各种计算机视觉任务,例如物体检测、物体识别、场景理解等。
该数据集的来源为OpenImages-v6,可按照官方教程进行数据下载,数据大小约为352G;该网络采用的预训练模型为来自ImageNet的ResNeXt50_32x4d,同样可通过上述方式进行自行下载;
数据集的目录结构如下:
<DOWNLOAD_PATH>
│
└───info.json
│
└───train
│ └─── data
│ │ 000002b66c9c498e.jpg
│ │ 000002b97e5471a0.jpg
│ │ ...
│ └─── metadata
│ │ classes.csv
│ │ hierarchy.json
│ │ image_ids.csv
│ └─── labels
│ detections.csv
│ openimages-mlperf.json
│
└───validation
└─── data
│ 0001eeaf4aed83f9.jpg
│ 0004886b7d043cfd.jpg
│ ...
└─── metadata
│ classes.csv
│ hierarchy.json
│ image_ids.csv
└─── labels
detections.csv
openimages-mlperf.json
训练
单机8卡
单机8卡进行性能&&精度测试
nohup bash sbatch.sh >& bs16_epoch6.log &
#输出结果见bs16_epoch6.log
#注:可通过修改dcu.sh中DATASET_DIR参数按需修改输入数据的位置
result

精度
采用上述输入数据,加速卡采用Z100L * 8,可最终达到官方收敛要求,即34.0% mAP (注:运行完成退出时如有报错可忽略,该bug不影响运行会在下一版本修复)
| 卡数 | 类型 | 进程数 | 达到精度 |
|---|---|---|---|
| 8 | 混合精度 | 8 | 34.0% mAP |
应用场景
算法类别
目标检测
热点应用行业
制造,政府,医疗,科研
















 3108
3108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











