






摘要
大型语言模型(LLM)因其在自然语言处理方面的进步而受到广泛关注,并在文本理解和生成方面展现出无与伦比的能力。然而,同时生成具有连贯文本叙述的图像仍然是一个不断发展的前沿领域。为此,我们引入了一种新的交错生成视觉和语言的技术,该技术以“生成式vokens”的概念为基础,充当协调图像文本输出的桥梁。我们的方法的特点是独特的两阶段训练策略,专注于无描述的多模态生成,其中训练不需要图像的全面描述。为了增强模型整合能力,引入了分类器无关的指导,从而增强了 vokens 在图像生成方面的有效性。我们的模型,MiniGPT-5 在 MMDialog 数据集上,比基线 Divter模型有了显着改进,并在 VIST 数据集上的人类评估中始终提供卓越或可比的多模态输出,这显示了其在不同基准上的有效性。
1.介绍
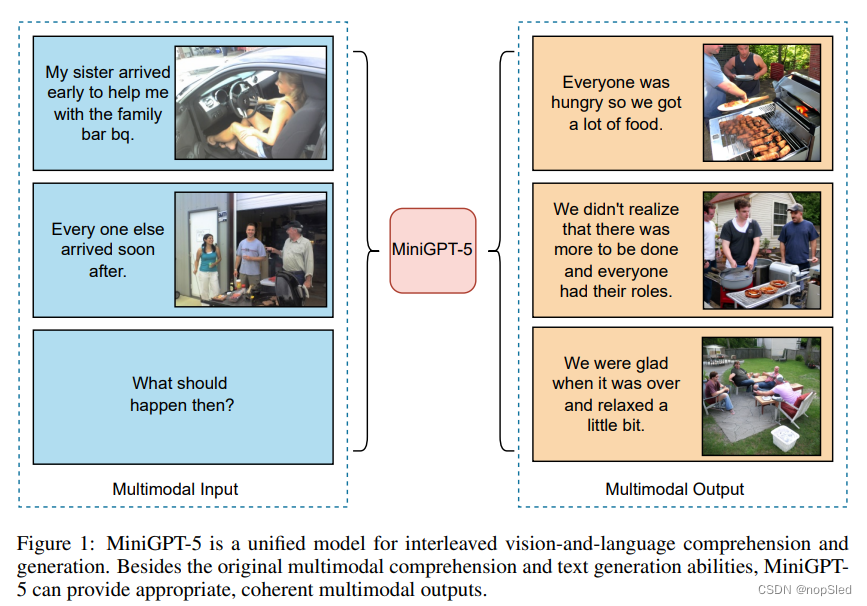
在最近大规模视觉和语言模型的发展中,多模态特征集成不仅是一种不断发展的趋势,而且是塑造从多模态对话agent到前沿内容创建工具等广泛应用的关键进步。随着研究和开发的激增,诸如此类的视觉和语言模型正处于一个时代的边缘,人们期望它们能够无缝地理解和生成文本和图像内容。这种多方面的能力至关重要,因为它可以促进虚拟现实、媒体和电子商务等各个领域之间的增强互动。本质上,任务是使模型能够使用视觉和文本模态连贯地合成、识别和响应,协调信息流并创建紧密的叙述。然而,当我们走上混合了文本和视觉模态并实现交替视觉和语言生成的道路时,如图 1 所示,我们认识到这是由大语言模型中更完善和更流畅的多模态交互的迫切需求所驱动的。然而,这段旅程充满了多重挑战。
首先,虽然当前SOTA的大语言模型(LLM)在理解文本和处理文本图像对方面表现出色,但它们在生成图像的微妙艺术方面却表现不佳。其次,与用于图像描述的传统任务不同,新兴的交替式视觉和语言任务严重依赖于以主题为中心的数据,通常会忽略彻底的图像描述符。即使在海量数据集上进行训练后,将生成的文本与相应的图像对齐仍然具有挑战性。最后,当我们突破LLM的界限时,大量的内存需求要求我们设计更有效的策略,特别是在下游任务中。
为了解决这些挑战,我们提出了 MiniGPT-5,这是一种以“生成式vokens”概念为基础的新的交替式视觉和语言生成技术。通过特殊的视觉token——“生成式vokens”,将 Stable Diffusion机制与LLM相结合,我们预示了一种多模式生成的新模式。与此同时,我们提出的两阶段训练方法强调了描述无关的基础阶段的重要性,即使在数据稀缺的情况下也使模型表现良好。我们的通用阶段没有特定领域的标注,使我们的解决方案与现有的工作不同。为了确保生成的文本和图像协调一致,我们的双损失策略开始发挥作用,并通过我们新的生成式voken 方法和分类器无关指导进一步增强。最后,我们的参数优化微调方法解决了内存限制,优化了训练效率。
基于这些技术,我们的工作标志着一种变革性的方法。如图 2 所示,使用 ViT(Vision Transformer)和 Qformer 以及大语言模型,我们将多模态输入转换为生成 voken,与高分辨率 Stable Diffusion 2.1 模型无缝配对,以生成基于上下文的图像。将图像作为辅助输入与指令微调方法相结合,并开创了文本和图像生成损失的先河,我们放大了文本和视觉之间的协同作用。我们提出的 MiniGPT-5,针对 CLIP 等模型的限制,巧妙地将扩散模型与 MiniGPT-4 融合,提供无与伦比的多模态结果,而无需依赖于特定领域的标注。至关重要的是,我们的策略可以利用多模态视觉语言base模型的进展,这为增强多模态生成能力带来光明的前景。
我们主要的贡献在三个方面:
- 我们提出了一种使用新的且通用技术的多模态编码器,该技术已被证明比 LLM 更有效,并且还可以反转为生成 vokens,并将其与Stable Diffusion相结合以生成交替的视觉和语言输出(可以进行多模态生成的多模态语言模型)。
- 我们重点介绍了一种用于描述无关的多模态生成的新的两阶段训练策略。单模态对齐阶段从大型文本图像对中获取高质量的文本对齐的视觉特征。多模态学习阶段引入了新的训练任务,以提示上下文生成,确保视觉和文本提示能够很好地协调生成。在训练阶段加入分类器无关指导进一步提高了生成质量
- 与其他多模态生成模型相比,我们在 CC3M 数据集上实现了SOTA的性能。我们还在著名数据集(包括 VIST 和 MMDialog)上达到了前所未有的基准。
2.相关工作
Text-to-Image Generation。为了将文本描述转换为相应的视觉表示,文本到图像模型采用复杂的架构和复杂的算法,桥接了文本信息和视觉内容之间的差距。这些模型擅长解释输入文本的语义并将其转换为连贯且相关的图像。 该领域最近的一个值得注意的贡献是Stable Diffusion 2,它采用扩散过程来生成有条件的图像特征,然后根据这些特征重建图像。我们的研究旨在利用这种预训练的模型,增强其适应多模态输入和输出的能力。
Multimodal Large Language Models。随着大型语言模型 (LLM) 变得越来越有影响力和易于使用,越来越多的研究将这些预训练的 LLM 扩展到多模态理解任务领域。例如,为了重现 GPT-4 中令人印象深刻的多模态理解能力,MiniGPT-4 提出了一个投影层,将 BLIP 的预训练视觉组件与SOTA的开源大语言模型 Vicuna 对齐。在我们的工作中,我们利用 MiniGPT-4 作为基础模型,并将模型的功能扩展到多模态生成。
Multimodal Generation with Large Language Models。为了增强LLM无缝集成视觉和语言生成的能力,最近的研究引入了各种创新方法。例如,CM3Leon 提出了一种检索增强、纯解码器的架构,专为文本到图像和图像到文本应用而设计。类似地,Emu 采用预训练的 EVA-CLIP 模型将图像转换为一维特征,并微调 LLAMA 模型以通过自回归技术生成连贯的文本和图像特征。另一方面,GILL 和 SEED 都探索了将 vokens 映射到预训练来稳定扩散模型的文本特征空间的概念;GILL 采用编码器-解码器框架,而 SEED 采用可训练的 Q-Former 结构。与这些方法相比,我们的模型通过将 voken 特征与视觉信息对齐,采取了更直接的路线。此外,我们引入了几种旨在增强图像质量和上下文连贯性的训练策略。
3.方法
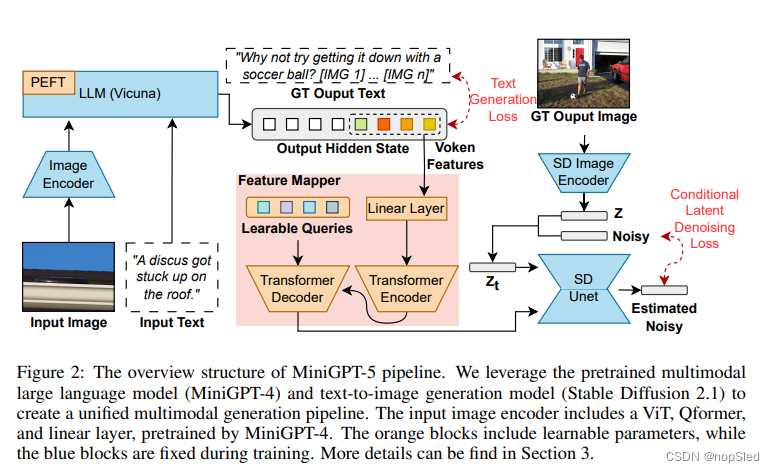
为了赋予大语言模型多模态生成能力,我们引入了一个集成了预训练的多模态大语言模型和文本到图像生成模型的结构化框架。为了解决模型领域之间的差异,我们引入了特殊的视觉token(称为“生成式vokens”),它能够直接对原始图像进行训练。此外,我们提出了两阶段训练方法,再加上分类器无关的指导策略,以进一步提高生成质量。后续部分将详细探讨这些元素。
3.1 MULTIMODAL INPUT STAGE
Multimodal Encoding。每个文本token都嵌入到向量
e
t
e
x
t
∈
R
d
e_{text} ∈\mathbb R^d
etext∈Rd中,而预训练的视觉编码器将每个输入图像转换为特征
e
i
m
g
∈
R
32
×
d
e_{img} ∈\mathbb R^{32×d}
eimg∈R32×d。这些嵌入被连接起来以创建输入提示特征。
Adding Vokens in LLM。由于原始LLM的词表
V
V
V仅包含文本token,因此我们需要在LLM和生成模型之间构建一座桥梁。因此,我们在LLM 词表
V
V
V中引入一组特殊token
V
i
m
g
=
{
[
I
M
G
1
]
,
[
I
M
G
2
]
,
.
.
.
,
[
I
M
G
n
]
}
V_{img}=\{[IMG1], [IMG2],...,[IMGn]\}
Vimg={[IMG1],[IMG2],...,[IMGn]}(默认
n
=
8
n=8
n=8)来作为生成式vokens。这些 voken作为LLM 输出隐藏状态用于后续图像生成,并且这些 voken 的位置可以表示交替图像的插入。在 MiniGPT-4 中所有预训练权重
θ
p
r
e
t
r
a
i
n
e
d
θ_{pretrained}
θpretrained 固定的情况下,可训练参数包括额外的输入嵌入
θ
v
o
k
e
n
θ_{voken}
θvoken和输出嵌入
θ
v
o
k
e
n
θ_{voken}
θvoken。
Parameter-Efficient Fine-Tuning (PEFT)。参数高效微调 (PEFT) 对于训练大型语言模型 (LLM) 至关重要。尽管如此,它在多模态环境中的应用在很大程度上仍未得到探索。我们在 MiniGPT-4 编码器上使用 PEFT 来训练模型以更好地理解指令或提示,从而增强其在新的甚至零样本任务中的性能。更具体地说,我们在整个语言编码器(MiniGPT-4 中使用的 Vicuna)上尝试了前缀微调和 LoRA。与指令微调相结合,它显着增强了再各种数据集(例如 VIST 和 MMDialog)的多模态生成性能。
3.2 MUTIMODAL OUPUT GENERATION
为了准确地将生成式token与生成式模型对齐,我们制定了一个用于维度匹配的紧凑映射模块,并结合了一些有监督损失,包括文本空间损失和潜在扩散模型损失。文本空间损失帮助模型学习token的正确位置,而潜在扩散损失直接将token与适当的视觉特征对齐。由于生成式vtoken的特征直接由图像引导,因此我们的方法不需要引入对图像的全面描述,从而实现描述无关学习。
Text Space Generation:我们首先遵循因果语言建模在文本空间中联合生成文本和voken。在训练过程中,我们将 voken 附加到实际图像的位置,并训练模型在预测文本的过程中也生成voken。具体来说,生成的token表示为
T
=
{
t
1
,
t
2
,
.
.
.
,
t
m
}
T=\{t_1,t_2,...,t_m\}
T={t1,t2,...,tm},其中
t
i
∈
V
∪
V
i
m
g
t_i∈V∪V_{img}
ti∈V∪Vimg,因果语言建模损失定义为:
L
t
e
x
t
:
=
−
∑
i
=
1
m
l
o
g
p
(
t
i
∣
e
t
e
x
t
,
e
i
m
g
,
t
1
,
.
.
.
,
t
i
−
1
;
θ
p
r
e
t
r
a
i
n
e
d
,
θ
v
o
k
e
n
i
n
p
u
t
,
θ
v
o
k
e
n
o
u
t
p
u
t
)
,
w
h
e
r
e
t
i
∈
V
∪
V
i
m
g
(1)
L_{text}:=-\sum^m_{i=1}log~p(t_i|e_{text},e_{img},t_1,...,t_{i-1};\theta_{pretrained},\theta_{voken_input},\theta_{voken_output}),where~t_i\in V∪V_{img}\tag{1}
Ltext:=−i=1∑mlog p(ti∣etext,eimg,t1,...,ti−1;θpretrained,θvokeninput,θvokenoutput),where ti∈V∪Vimg(1)
Mapping Voken Features for Image Generation:接下来,我们将输出隐藏状态
h
v
o
k
e
n
h_{voken}
hvoken 与文本到图像生成模型的文本条件特征空间对齐。将voken特征
h
v
o
k
e
n
h_{voken}
hvoken映射到一个合理的图像生成条件特征
e
t
e
x
t
e
n
c
o
d
e
r
∈
R
L
×
d
^
e_{text_encoder}\in \textbf R^{L×\hat d}
etextencoder∈RL×d^(其中
L
L
L是文本到图像生成模型中文本编码器的最大输入长度,
d
^
\hat d
d^是文本到图像生成模型中编码器输出特征的维度)。我们构建了一个特征映射器模块,包括一个两层 MLP 模型
θ
M
L
P
θ_{MLP}
θMLP、一个四层编码器-解码器transformer模型
θ
e
n
c
−
d
e
c
θ_{enc-dec}
θenc−dec,和一个可学习的解码器特征序列
q
q
q。映射后的特征
h
^
v
o
k
e
n
\hat h_{voken}
h^voken 由下式给出:
h
^
v
o
k
e
n
:
=
θ
e
n
c
−
d
o
c
(
θ
M
L
P
(
h
v
o
k
e
n
)
,
q
)
∈
R
L
×
d
^
(2)
\hat h_{voken}:=\theta_{enc-doc}(\theta_{MLP}(h_{voken}),q)\in \textbf R^{L\times \hat d}\tag{2}
h^voken:=θenc−doc(θMLP(hvoken),q)∈RL×d^(2)
Image Generation with Latent Diffusion Model (LDM):为了生成适当的图像,映射特征
h
^
v
o
k
e
n
\hat h_{voken}
h^voken 被用作去噪过程中的条件输入。直观上,
h
^
v
o
k
e
n
\hat h_{voken}
h^voken 应该表示相应的文本特征,指导扩散模型生成实际图像。我们使用潜在扩散模型(LDM)的损失作为指导。在训练过程中,实际图像首先通过预训练的 VAE 转换为潜在特征
z
0
z_0
z0。然后,我们通过将噪声
ϵ
ϵ
ϵ 添加到
z
0
z_0
z0 来获得噪声潜在特征
z
t
z_t
zt。使用预训练的 U-Net 模型
ϵ
θ
ϵ_θ
ϵθ 来计算条件 LDM 损失:
L
L
D
M
:
=
E
ϵ
∈
N
(
0
,
1
)
,
t
[
∣
∣
ϵ
−
ϵ
t
h
e
t
a
(
z
t
,
t
,
h
^
v
o
k
e
n
)
∣
∣
2
2
]
(3)
L_{LDM}:=\mathbb E_{ϵ\in\mathcal N(0,1),t}[||ϵ-ϵ_{theta}(z_t,t,\hat h_{voken})||^2_2]\tag{3}
LLDM:=Eϵ∈N(0,1),t[∣∣ϵ−ϵtheta(zt,t,h^voken)∣∣22](3)
这种综合方法利用了预训练模型、专用token和创新训练技术的功能,确保对文本和视觉元素的理解和生成一致。
3.3 TRAINING STRATEGY
考虑到文本和图像之间不可忽略的领域迁移,我们观察到对有限的交替文本和图像数据集进行直接训练可能会导致错位和图像质量下降。因此,我们采用两种不同的训练策略来缓解这个问题。第一个策略包括结合分类无关的引导技术,该技术增强了生成token在整个扩散过程中的有效性。第二种策略分两个阶段展开:最初的预训练阶段侧重于粗略特征对齐,然后是致力于复杂特征学习的微调阶段。
Classifier-free Guidance (CFG):为了增强生成的文本和图像之间的连贯性,我们首先利用分类无关指导的思想进行多模态生成。在文本到图像的扩散过程中引入了分类无关引导。该方法观察到生成模型
P
θ
P_θ
Pθ 可以通过使用条件 dropout 同时对有条件生成和无条件生成进行训练来实现改进的有条件结果。在我们的背景下,我们的目标是强调可训练条件
h
v
o
k
e
n
h_{voken}
hvoken并且生成模型是固定的。在训练过程中,我们以 10% 的概率将
h
v
o
k
e
n
h_{voken}
hvoken 替换为零特征
h
0
∈
0
n
×
d
h_0 ∈\textbf 0^{n×d}
h0∈0n×d,得到无条件特征
h
^
0
=
θ
e
n
c
−
d
e
c
(
θ
M
L
P
(
h
0
)
,
q
)
\hat h_0 = θ_{enc-dec}(θ_{MLP}(h_0), q)
h^0=θenc−dec(θMLP(h0),q)。推理过程中,
h
^
0
\hat h_0
h^0作为负向提示,来精化去噪过程,表示为:
l
o
g
P
θ
^
(
ϵ
t
∣
z
t
+
1
,
h
^
v
o
k
e
n
,
h
^
0
)
=
l
o
g
P
t
h
e
t
a
(
ϵ
t
∣
z
t
+
1
,
h
^
0
)
+
γ
(
l
o
g
P
t
h
e
t
a
(
ϵ
t
∣
z
t
+
1
,
h
^
v
o
k
e
n
)
−
l
o
g
P
θ
(
ϵ
t
∣
z
t
+
1
,
h
^
0
)
)
(4)
log~\hat{P_{\theta}}(ϵ_t|z_{t+1},\hat h_{voken},\hat h_0)=log~P_{theta}(ϵ_t|z_{t+1},\hat h_0)+\gamma(log~P_{theta}(ϵ_t|z_{t+1},\hat h_{voken})-log~P_{\theta}(ϵ_t|z_{t+1},\hat h_0))\tag{4}
log Pθ^(ϵt∣zt+1,h^voken,h^0)=log Ptheta(ϵt∣zt+1,h^0)+γ(log Ptheta(ϵt∣zt+1,h^voken)−log Pθ(ϵt∣zt+1,h^0))(4)
Two-stage Training Strategy:认识到纯文本生成和文本-图像生成之间的重要领域差距,我们提出了一种两阶段训练策略:单模态对齐阶段(UAS)和多模态学习阶段(MLS)。最初,我们将 voken 特征与单个文本-图像对数据集中的图像生成特征对齐,例如 CC3M,其中每个数据样本仅包含一个文本和一张图像,并且文本通常是图像的标题。在此阶段,我们利用图像释义作为 LLM 输入,使 LLM 能够生成
v
o
k
e
n
voken
voken。由于这些数据集包含图像描述信息,我们还引入了辅助损失来帮助 voken 对齐,以最小化文本到图像生成模型中生成特征
h
^
v
o
k
e
n
\hat h_{voken}
h^voken 和来自文本编码器
τ
θ
τ_θ
τθ 的标题特征之间的距离:
L
c
a
p
:
=
M
S
E
(
h
^
v
o
k
e
n
,
τ
θ
(
c
)
)
(5)
L_{cap}:=MSE(\hat h_{voken},\tau_{\theta}(c))\tag{5}
Lcap:=MSE(h^voken,τθ(c))(5)


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









