






摘要
尽管开源大语言模型(LLM)(例如 LLaMA)取得了进步,但它们在工具使用功能(即使用外部工具(API)来完成人类指令)方面仍然受到严重限制。原因是当前的指令微调主要集中在基本语言任务上,而忽略了工具使用领域。这与目前 SOTA 闭源 LLM(例如 ChatGPT)的出色工具使用能力形成鲜明对比。为了弥补这一差距,我们引入了 ToolLLM,这是一个涵盖数据构建、模型训练和评估的通用工具使用框架。我们首先介绍 ToolBench,这是一个用于工具使用的指令微调数据集,它是使用 ChatGPT 自动构建的。具体来说,构建可以分为三个阶段:(i)API 收集:我们从RapidAPI Hub收集了16464个真实世界的RESTful API,涵盖49个类别; (ii) 指令生成:我们促使 ChatGPT 生成涉及这些 API 的各种指令,涵盖单工具和多工具场景; (iii) 解决方案路径标注:我们使用 ChatGPT 为每条指令搜索有效的解决方案路径(API 调用链)。为了增强LLM的推理能力,我们开发了一种新的基于深度优先搜索的决策树算法。它使LLM能够评估多个推理轨迹并扩展搜索空间。此外,为了评估LLM的工具使用能力,我们开发了一个自动评估器:ToolEval。基于ToolBench,我们对LLaMA进行微调以获得 ToolLLaMA,并为其配备神经API检索器,为每条指令推荐合适的API。实验表明,ToolLLaMA 表现出执行复杂指令和泛化到未见过的 API 的卓越能力,并且表现出与 ChatGPT 相当的性能。我们的 ToolLLaMA 还在数据集分布外的工具使用数据集 APIBench 中展示了强大的零样本泛化能力。代码、训练的模型和演示可在 https://github.com/OpenBMB/ToolBench 上公开获取。
1.介绍
工具学习旨在释放大语言模型 (LLM) 的力量,以有效地与各种工具 (API) 交互以完成复杂的任务。通过将 LLM 与 API 集成,我们可以极大地扩展它们的效用,并使它们能够充当用户和庞大的应用程序生态系统之间的高效中介。尽管 LLaMA 等开源LLM已经通过指令微调实现了多种功能,但它们在执行更高级别任务方面仍然缺乏复杂性,例如与工具(API)适当交互以完成复杂的人类指令。这种缺陷是因为当前的指令微淘主要集中在基本语言任务上,而相对忽视了工具使用领域。另一方面,当前最先进的(SOTA)LLM(例如ChatGPT和GPT-4)在使用工具方面表现出了令人印象深刻的能力,但它们是闭源的,其内部机制不透明。这限制了人工智能技术的民主化以及社区驱动的创新和发展的范围。对此,我们认为迫切需要赋能开源LLM熟练掌握多样化的API。
尽管之前的工作已经探索了构建用于使用工具的指令微调数据,但它们未能充分激发LLM内的工具使用能力,并且具有固有的局限性:(1)有限的API:它们要么无法涉及现实世界的API(例如RESTAPI) 或者只考虑小范围的API,因而多样性较差;(2)场景受限:现有工作仅限于使用单一工具的指令。相反,现实场景可能需要将多个工具交错在一起以进行多轮工具执行以解决复杂的任务。此外,他们经常假设用户提前手动为给定指令指定理想的 API 集,这对于大量现实世界的 API 集合来说是不可行的;(3)规划和推理能力较差:现有工作采用CoT或ReACT进行模型推理,无法充分引出存储在LLM中的能力,从而无法处理复杂的指令。此外,有些工作甚至不执行API来获取真实的响应,而这些响应是后续模型规划的重要信息。
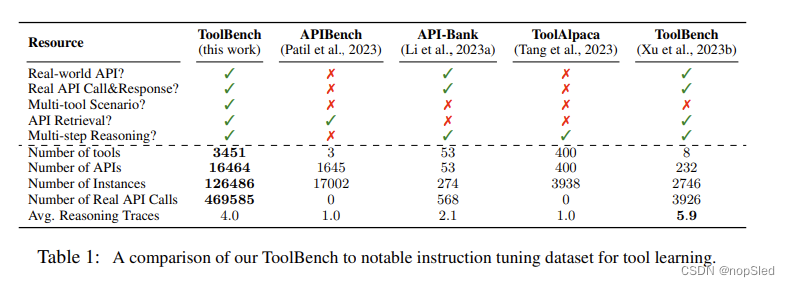
为了促进开源 LLM 中的工具使用能力,我们引入了 ToolLLM,这是一个通用工具使用框架,包括数据构建、模型训练和评估。如图 1 所示,我们收集了一个高质量的指令调优数据集 ToolBench。它是使用 ChatGPT (gpt-3.5-turbo-16k) 自动构建的。ToolBench与以往工作的比较如表1所示。具体而言,ToolBench的构建分为三个阶段:
- API Collection:我们从 RapidAPI(https://rapidapi.com/hub)收集了 16,464 个表征状态转移 (REST) API,RapidAPI 是一个托管开发人员提供的大量实际 API 的平台。这些 API 涵盖 49 个不同的类别,例如社交媒体、电子商务和天气。对于每个API,我们从RapidAPI中抓取详细的API文档,包括功能描述、所需参数、API调用的代码片段等。通过理解这些文档来学习执行API,LLM可以泛化到训练期间未见过的新API;
- Instruction Generation:我们首先从整个集合中采样 API,然后提示 ChatGPT 为这些 API 生成不同的指令。为了涵盖实际场景,我们策划了涉及单工具和多工具场景的指令。这确保我们的模型不仅学习如何与各个工具交互,而且还学习如何组合它们来完成复杂的任务;
- Solution Path Annotation:每个解决方案路径可能包含多轮模型推理和实时 API 调用以得出最终响应。然而,即使是最复杂的 LLM,即 GPT-4,复杂的人类指令的通过率也很低,导致标注效率低下。为此,我们开发了一种新的基于深度优先搜索的决策树(DFSDT)来增强LLM的规划和推理能力。与传统的 ReACT 相比,DFSDT 使LLM能够评估多种推理路径,并做出深思熟虑的决定,要么撤回步骤,要么沿着有希望的路径继续前进。在实验中,DFSDT显着提高了标注效率,并成功完成了那些使用ReACT无法完成的复杂指令。
为了评估LLM的工具使用能力,我们开发了一个由 ChatGPT 支持的自动评估器 ToolEval。它包含两个关键指标:(1) 通过率,衡量LLM在有限预算内成功执行指令的能力;(2) 获胜率,比较两种解决方案路径的质量和实用性。我们证明 ToolEval 实现了与人类评估的高度相关性,并为测试环境的使用提供了稳健、可扩展且可靠的评估。
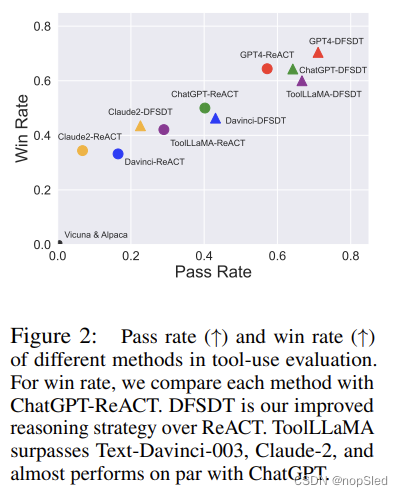
通过在ToolBench上微调LLaMA,我们得到ToolLLaMA。根据我们的 ToolEval 进行评估后,我们得出以下结论:
- ToolLLaMA 展示了处理单工具和复杂多工具指令的引人注目的能力。如图 2 所示,ToolLLaMA 的性能优于 Text-Davinci-003 和 Claude-2,达到了与“教师模型”ChatGPT 相当的性能,仅略逊于 GPT4。此外,ToolLLaMA 对以前未见过的 API 表现出强大的泛化能力,只需要 API 文档即可有效地适应新的 API。这种灵活性允许用户无缝地整合新颖的 API,从而增强模型的实用性。
- 我们表明,我们的 DFSDT 可以作为增强 LLM 推理能力的通用决策策略。DFSDT 通过考虑多个推理轨迹拓宽了搜索空间,并取得了比 ReACT 显着更好的性能。
- 我们训练了一个神经 API 检索器,这减少了实践中从大型 API 池中手动选择的需要。如图1所示,给定一条指令,API检索器会推荐一组相关的API,这些API被发送到ToolLLaMA进行多轮决策,得出最终答案。尽管筛选了大量 API,检索器仍表现出卓越的检索精度,返回与真实情况紧密一致的 API。
- ToolLLaMA 在分布外 (OOD) 数据集 APIBench 上表现出强大的泛化性能。 尽管没有对 APIBench 上的任何 API 或指令进行训练,但 ToolLLaMA 的性能与专门为 APIBench 设计的管道 Gorilla 相当。
2.DATASET CONSTRUCTION
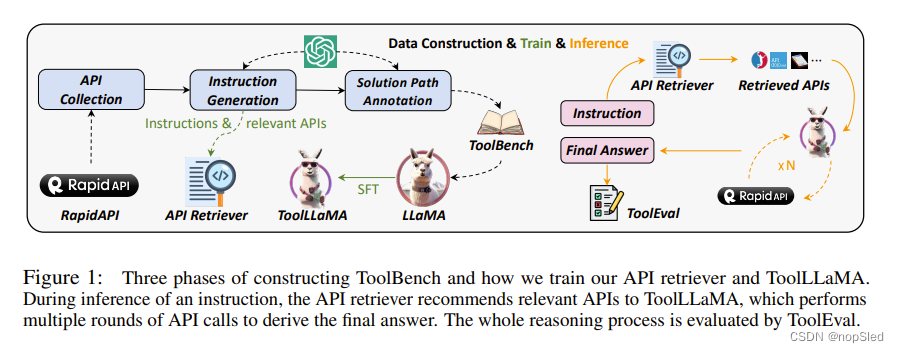
我们介绍了 ToolBench 的三阶段构建过程:API 收集(第 2.1 节)、指令生成(第 2.2 节)和解决方案路径标注(第 2.3 节)。 所有过程均基于 ChatGPT (gpt-3.5-turbo-16k),需要最少的人工监督,并且可以轻松扩展到新的 API。
2.1 API COLLECTION
我们首先介绍 RapidAPI 及其层次结构,然后介绍我们如何抓取和过滤 API。
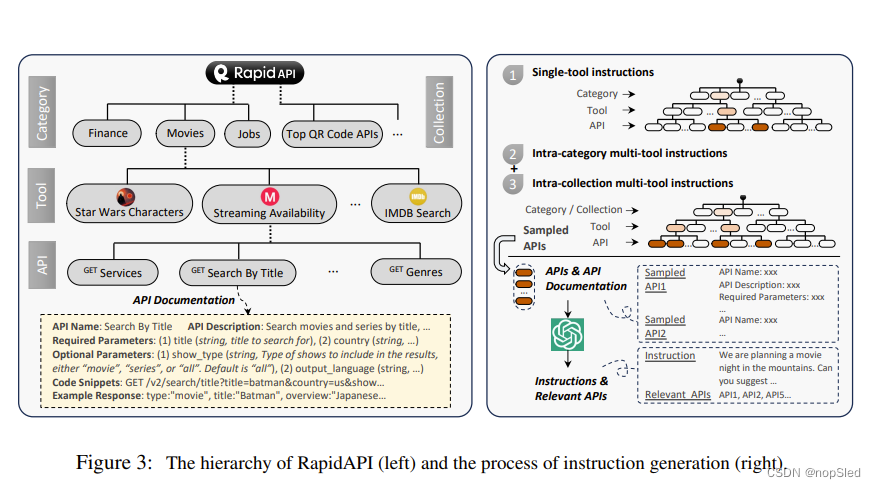
RapidAPI Hub。RapidAPI 是一个领先的 API 市场,它将开发人员与数千个实际 API 连接起来,简化了将各种服务集成到应用程序中的流程。开发人员只需注册 RapidAPI key即可测试并连接各种 API。RapidAPI 中的所有 API 均可分为 49 个粗粒度类别(link),例如体育、金融和天气。这些类别将 API 与最相关的主题相关联。此外,该中心还提供 500 多个细粒度分类,称为集合(link),例如中文 API 和数据库 API。同一集合中的 API 具有共同的特征,并且通常具有相似的功能或目标。
Hierarchy of RapidAPI。如图3所示,每个工具可能由多个API组成。对于每个工具,我们会抓取以下信息:工具的名称和描述、主机的 URL 以及属于该工具的所有可用 API;对于每个 API,我们记录其名称、描述、HTTP 方法、必需参数、可选参数、请求正文、API 调用的可执行代码片段以及 API 调用响应示例。这种丰富而详细的元数据可以作为LLM理解和有效使用 API 的宝贵资源,即使是以zero-shot的方式也是如此。
API Filtering。最初,我们从 RapidAPI 收集了 10853 个工具(53190 个 API)。然而,这些 API 的质量和可靠性可能存在很大差异。特别是,某些 API 可能维护得不好,例如返回 404 错误或其他内部错误。为此,我们执行了严格的过滤过程(详细信息参见附录 A.1),以确保 ToolBench 的最终工具集可靠且功能齐全。最后,我们只保留了 3451 个高质量工具(16464 个 API)。
2.2 INSTRUCTION GENERATION
与之前的工作不同,我们特别关注指令生成的两个关键方面:(1)多样性:训练LLM处理广泛的API使用场景,从而提高其通用性和鲁棒性;(2)多工具使用:反映经常需要多种工具相互作用的现实情况,提高LLM的实际适用性和灵活性。为此,我们不是从头开始考虑每一个指令,然后搜索相关 API,而是对 API 的不同组合进行采样,并制作涉及它们的各种指令。
Generating Instructions for APIs。将总的API集合定义为
S
A
P
I
\mathbb S_{API}
SAPI,每次,我们从
S
A
P
I
\mathbb S_{API}
SAPI中采样一些API:
S
N
s
u
b
=
{
A
P
I
1
,
⋅
⋅
⋅
⋅
,
A
P
I
N
}
\mathbb S^{sub}_N=\{API_1,····,API_N\}
SNsub={API1,⋅⋅⋅⋅,APIN}。我们提示 ChatGPT 了解这些 API 的功能,然后生成 (1) 涉及
S
N
s
u
b
\mathbb S^{sub}_N
SNsub 中 API 的可能指令 (
I
n
s
t
∗
Inst_*
Inst∗),以及 (2) 每个指令 (
I
n
s
t
∗
Inst_*
Inst∗) 的相关 API (
S
∗
r
e
l
⊂
S
N
s
u
b
\mathbb S^{rel}_*⊂\mathbb S^{sub}_N
S∗rel⊂SNsub),即
{
[
S
1
r
e
l
,
I
n
s
t
1
]
,
⋅
⋅
⋅
⋅
,
[
S
N
′
r
e
l
,
I
n
s
t
N
′
]
}
\{[\mathbb S^{rel}_1,Inst_1],····,[\mathbb S^{rel}_{N′}, Inst_{N′}]\}
{[S1rel,Inst1],⋅⋅⋅⋅,[SN′rel,InstN′]},其中
N
′
N′
N′表示生成的实例的数量。这些(指令、相关 API)对将用于训练第 3.1 节中的 API 检索器。我们使用不同的采样策略(稍后介绍)来覆盖所有 API 及其大部分组合,从而确保我们指令的多样性。
ChatGPT 的提示由以下部分组成:(1) 指令生成任务的一般描述,(2)
S
N
s
u
b
\mathbb S^{sub}_N
SNsub 中每个 API 的综合文档,这有助于 ChatGPT 了解其功能和相互作用,以及 (3) 三个上下文中的种子示例
{
s
e
e
d
1
,
s
e
e
d
2
,
s
e
e
d
3
}
\{seed1,seed2,seed3\}
{seed1,seed2,seed3}。每个种子示例都是由人类专家编写的理想指令生成。这些种子示例可通过上下文学习更好地规范 ChatGPT 的行为。总共,我们为单工具/多工具设置编写了 12 / 36 个不同的种子示例 (
S
s
e
e
d
\mathbb S_{seed}
Sseed),并每次随机采样三个示例。指令生成的详细提示在附录 A.7 中描述。总的来说,生成过程可以表述如下:
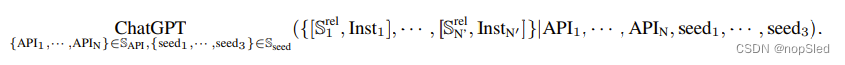
Sampling Strategies for Different Scenarios。如图 3 所示,对于单工具指令 (I1),我们迭代每个工具并为其 API 生成指令。然而,对于多工具设置,由于RapidAPI中不同工具之间的互连稀疏,从整个工具集中随机采样工具组合往往会导致一系列不相关的工具无法被单个指令自然地覆盖。为了解决稀疏性问题,我们利用 RapidAPI 层次结构信息。 由于属于同一 RapidAPI 类别或集合的工具通常在功能和目标上彼此相关,因此我们从同一类别/集合中随机选择 2-5 个工具,并从每个工具中采样最多 3 个 API 来生成指令。我们将生成的指令分别表示为类别内多工具指令(I2)和集合内多工具指令(I3)。通过严格的人工评估,我们发现这样生成的指令已经具有很高的多样性,涵盖了各种实际场景。我们还使用 Atlas(link)提供可视化说明来支持我们的主张。
生成初始指令集后,我们通过评估
S
N
s
u
b
\mathbb S^{sub}_N
SNsub 中是否存在来进一步过滤那些具有幻觉相关 API 的指令。最后,我们收集了近 20 万个合格的(指令、相关 API)对,其中 I1、I2 和 I3 的实例分别为 87413、84815 和 25251 个。
2.3 SOLUTION PATH ANNOTATION

如图 4 所示,给定指令
I
n
s
t
∗
Inst_*
Inst∗,我们提示 ChatGPT 搜索有效的操作序列:
{
a
1
,
⋅
⋅
⋅
,
a
N
}
\{a_1, ···, a_N\}
{a1,⋅⋅⋅,aN}。 这样的多步骤决策过程被视为 ChatGPT 的多轮对话。在每一轮
t
t
t,模型根据之前的交互生成一个动作
a
t
a_t
at,即
C
h
a
t
G
P
T
(
a
t
∣
{
a
1
,
r
1
,
⋅
⋅
⋅
,
a
t
−
1
,
r
t
−
1
}
,
I
n
s
t
∗
)
ChatGPT(a_t|\{a_1, r_1,···, a_{t−1}, r_{t−1}\}, Inst_*)
ChatGPT(at∣{a1,r1,⋅⋅⋅,at−1,rt−1},Inst∗),其中
r
∗
r_*
r∗ 表示真实的 API 响应。对于每一个
a
t
a_t
at,ChatGPT应该指定它的“想法”,即使用哪个API,以及该API的具体参数,即at具有以下格式:“
T
h
o
u
g
h
t
:
⋅
⋅
⋅
,
A
P
I
N
a
m
e
:
⋅
⋅
⋅
⋅
,
P
a
r
a
m
e
t
e
r
s
:
⋅
⋅
⋅
Thought:···, API~Name:····, Parameters:· ··
Thought:⋅⋅⋅,API Name:⋅⋅⋅⋅,Parameters:⋅⋅⋅”。
为了利用 ChatGPT 的函数调用功能,我们将每个 API 视为一个特殊函数,并将其 API 文档输入到 ChatGPT 的函数字段中。这样,模型就明白了如何调用API。对于每条指令
I
n
s
t
∗
Inst_*
Inst∗,我们将所有采样的 API
S
N
s
u
b
\mathbb S^{sub}_N
SNsub 作为可用函数提供给 ChatGPT。为了让 ChatGPT 完成一个动作序列,我们定义了两个附加函数,即“Finish with Final Answer”和“Finish by Giving Up”。前一个函数有一个参数,对应于原始指令的详细最终答案;而后一个函数是针对多次API调用尝试后所提供的API无法完成原始指令的情况而设计的。
Depth First Search-based Decision Tree。在我们的试点研究中,我们发现CoT或ReACT具有固有的局限性:(1)error propagation:错误的操作可能会进一步传播错误并导致模型陷入错误循环,例如不断地以错误的方式调用API 或幻觉 API; (2)limited exploration:CoT或ReACT只探索一种可能的方向,导致对整个动作空间的探索有限。因此,即使是 GPT-4 也常常无法找到有效的解决方案路径,从而导致标注变得困难。
为此,我们提出构建决策树来扩大搜索空间并增加找到有效路径的可能性。如图 4 所示,我们的 DFSDT 允许模型评估不同的推理路径,并选择 (1) 沿着有希望的路径继续进行,或者 (2) 通过调用“Finish by Giving Up”函数放弃现有节点并扩展新的节点。 在节点扩展期间,为了使子节点多样化并扩展搜索空间,我们向 ChatGPT 提示先前生成的节点的信息,并明确鼓励模型生成不同的节点。对于搜索过程,我们更喜欢深度优先搜索(DFS)而不是广度优先搜索(BFS),因为只要找到一条有效路径就可以完成标注。使用 BFS 将花费过多的 OpenAI API 调用。更多细节在附录 A.8 中描述。我们对所有生成的指令执行 DFSDT,并仅保留那些传递的解决方案路径。最终,我们生成 126486 个(指令、解决方案路径)对,用于训练第 3.2 节中的 ToolLLaMA。

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









