







最近OCC的综述很多,这两天arxiv上又挂出来一篇,从信息融合的角度全面回顾了占用网络的相关工作,值得一看!
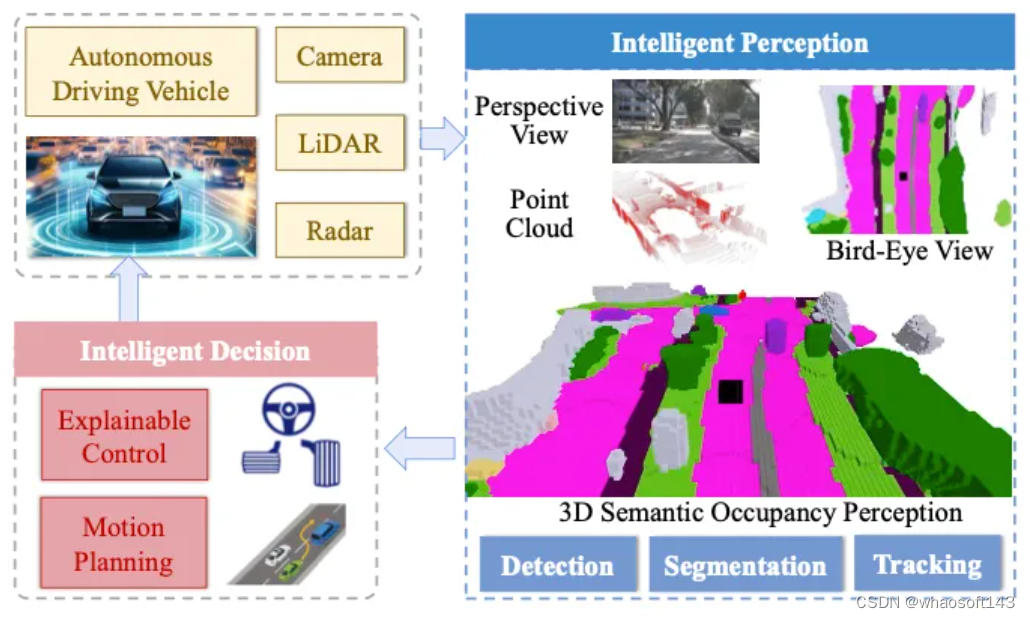
3D占用感知技术旨在观察和理解自动驾驶汽车的密集3D环境。由于其全面的感知能力,该技术正在成为自动驾驶感知系统的一种趋势,并引起了工业界和学术界的极大关注。与传统的BEV感知类似,3D占用感知具有多源输入的性质,具有信息融合的必要性。然而,不同之处在于,它捕捉了2D BEV忽略的垂直结构。在这项调查中,我们回顾了关于3D占用感知的最新工作,并对各种输入模态的方法进行了深入分析。具体来说,我们总结了一般的网络管道,重点介绍了信息融合技术,并讨论了有效的网络训练。我们在最流行的数据集上评估和分析了最先进的占用感知性能。此外,还讨论了挑战和未来的研究方向。
开源仓库:https://github.com/HuaiyuanXu/3D-Occupancy-Perception
总结来说,本文的主要贡献如下:
-
我们系统地回顾了自动驾驶领域3D占用感知的最新研究,涵盖了整体研究背景、对其重要性的全面分析以及对相关技术的深入讨论。
-
我们提供了3D占用感知的分类,并详细阐述了核心方法论问题,包括网络pipeline、多源信息融合和有效的网络训练。
-
我们提供了3D占用感知的评估,并提供了详细的性能比较。此外,还讨论了目前的局限性和未来的研究方向。
背景
Occ历史回顾
占用感知源于占用网格映射(OGM),这是移动机器人导航中的一个经典主题,旨在从有噪声和不确定的测量中生成网格图。该地图中的每个网格都被分配了一个值,该值对网格空间被障碍物占据的概率进行评分。语义占用感知源于SUNCG,它从单个图像中预测室内场景中所有体素的占用状态和语义。然而,与室内场景相比,研究室外场景中的占用感知对于自动驾驶来说是必不可少的。MonoScene是仅使用单眼相机进行户外场景占用感知的开创性工作。特斯拉在2022年CVPR自动驾驶研讨会上宣布了其全新的纯视觉的占用网络,与MonoScene并驾齐驱。这个新网络根据环绕视图RGB图像全面了解车辆周围的3D环境。随后,占用感知引起了广泛关注,推动了近年来自动驾驶占用感知研究的激增。
早期的户外占用感知方法主要使用激光雷达输入来推断3D占用。然而,最近的方法已经转向更具挑战性的以视觉为中心的3D占用预测。目前,占用感知研究的一个主要趋势是以视觉为中心的解决方案,辅以以激光雷达为中心的方法和多模式方法。占用感知可以作为端到端自动驾驶框架内3D物理世界的统一表示,随后是跨各种驾驶任务(如检测、跟踪和规划)的下游应用。占用感知网络的训练在很大程度上依赖于密集的3D占用标签,导致了多样化街景占用数据集的开发。最近,利用大型模型强大的性能,将大型模型与占用感知相结合,有望缓解繁琐的3D占用标签需求。
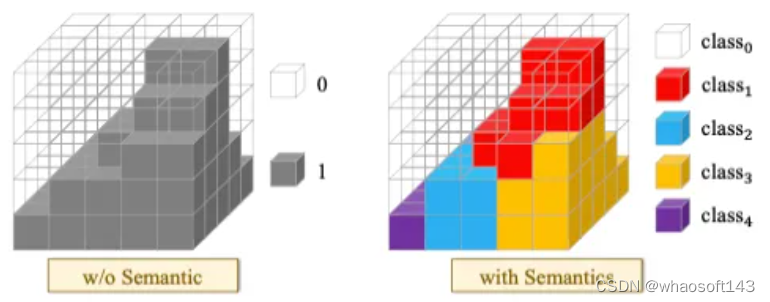
与OCC的相关任务主要包含:
-
BEV感知
-
3D语义场景补全
-
视觉3D重建
方法论
表1详细介绍了自动驾驶占用感知的最新方法及其特点。该表详细说明了每种方法的发布地点、输入方式、网络设计、目标任务、网络培训和评估以及开源状态。下面,我们根据输入数据的模态将占用感知方法分为三种类型。它们分别是以激光雷达为中心的占用感知、以视觉为中心的占据感知和多模态占用感知。随后,讨论了占用网络的训练及其损失函数。最后,介绍了利用占用感知的各种下游应用程序。

LiDAR-Centric Occupancy Perception
General Pipeline
以激光雷达为中心的语义分割仅预测稀疏点的语义类别。相比之下,以激光雷达为中心的占用感知提供了对环境的密集3D理解,这对自动驾驶系统至关重要。对于激光雷达传感,所获取的点云具有固有的稀疏特性,并受到遮挡。这就要求以激光雷达为中心的占用感知不仅解决了场景从稀疏到密集的占用推理,而且实现了对物体的部分到完全估计。
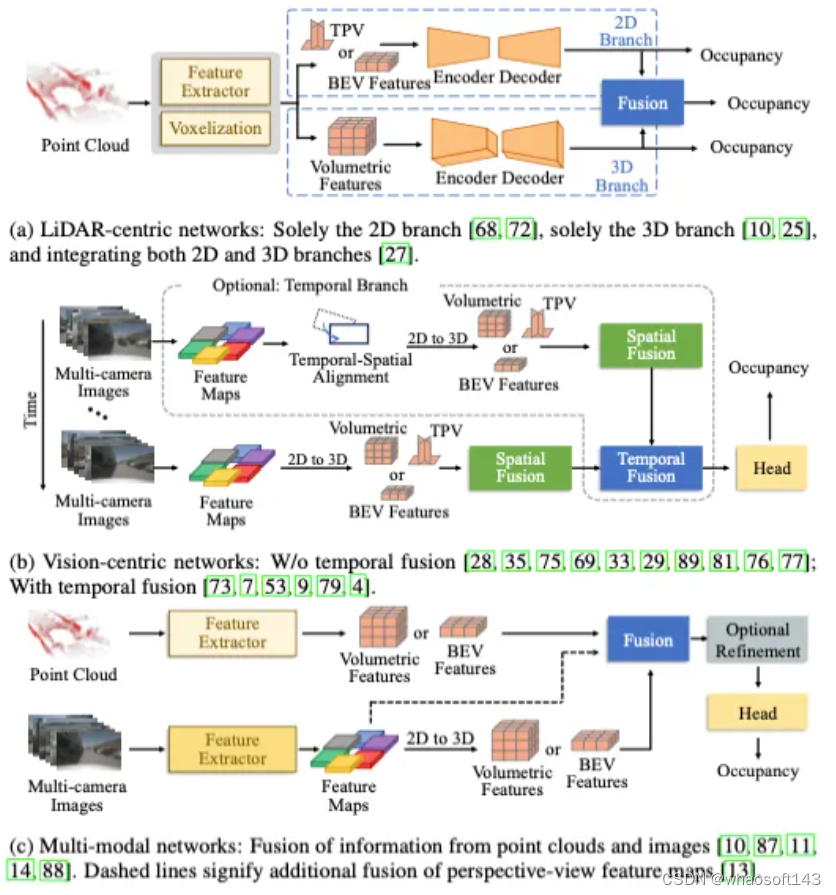
图3a说明了以激光雷达为中心的占用感知的一般流程。输入点云首先进行特征提取和体素化,然后通过编码器-解码器模块进行表示增强。最终,推断出场景的完整和密集占用。
以激光雷达为中心的OCC信息融合
一些作品直接利用单个2D分支来推理3D占用,例如DIF和PointOcc。在这些方法中,只需要2D特征图而不是3D特征体积,从而减少了计算需求。然而,一个显著的缺点是高度信息的部分丢失。相反,3D分支不
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









