






对话系统整理
!对话系统的类型划分
分为检索式+生成式+混合式(两者的混合)
检索式:提前把答案整理存到库里,对用户的query进行理解后检索查询到合适的答案再返回。优点:可干预,稳定。缺点:无法应对闲聊类的问题
生成式:用于闲聊的问题。通过模型或者规则的方式生成回复。优点:泛化能力强,缺点:可控性低,需要考虑生成的句子逻辑上的合理性等。
分为单轮对话系统+多轮对话系统
多轮对话:需要 DM模块来管理对话内容,需要DST来维护对话状态,需要DP(dialog policy)来评定给出最终回复。
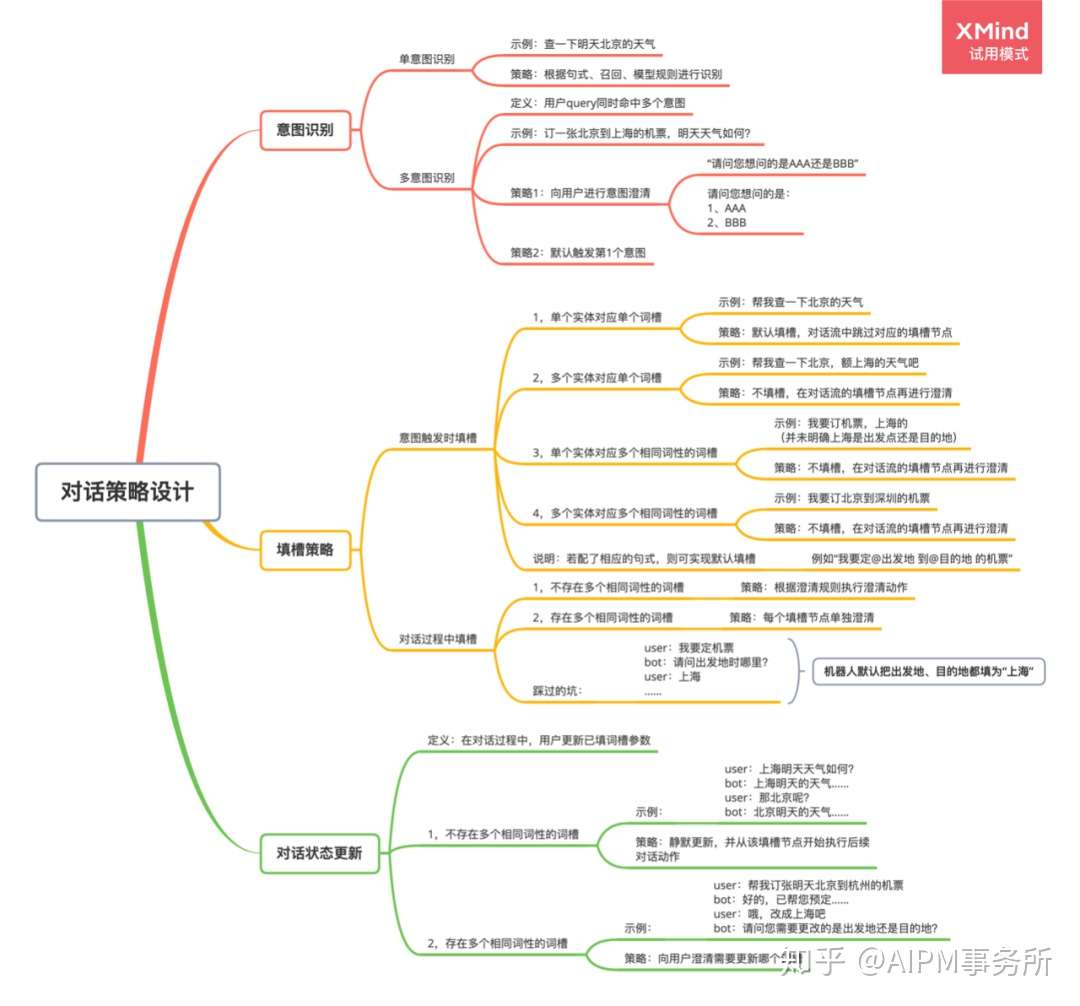
!对话意图的识别方法
主要包含三种识别方式:模型、召回、句式
- 模型:根据配置的相似句训练分类模型,对用户query进行模型识别相应意图。
- 召回:对用户query进行检索匹配,相似度超过阈值时则触发对应的意图。
- 句式:句式是通过词槽、词典来表示某类问法的句子模板,当用户query中的信息片段严格匹配或模糊匹配配置的句式并且超过阈值时,则触发该意图。
!对话信息词槽的槽值的获取方法(slot提取方法)
通常,词槽的槽值识别来源包括2种:
- 用户自定义词典:用户可自定义创建词典,并配置该词典对应的实体词及同义词。创建词典后,机器人则会将query与用户创建的词典内容进行匹配,若匹配中,则抽取该内容并填入对应的槽位。(先分词,再分后的词去词典中查询,查询得到返回对应的槽位名称和槽值: 北京-city)
- 系统预置词典:相比于用户自定义创建的词典,系统预置的词典,用户可直接使用,能够大大降低用户的配置成本。系统预置词典通常有两种来源: (通用词典,预定义,可复用)
- 使用模型;由算法提供命名实体识别模型,可识别“人名”、“地名”、“组织名”等实体(基于序列标注任务,模型能够自动标注出句子中可能包含的实体) (slot模型)
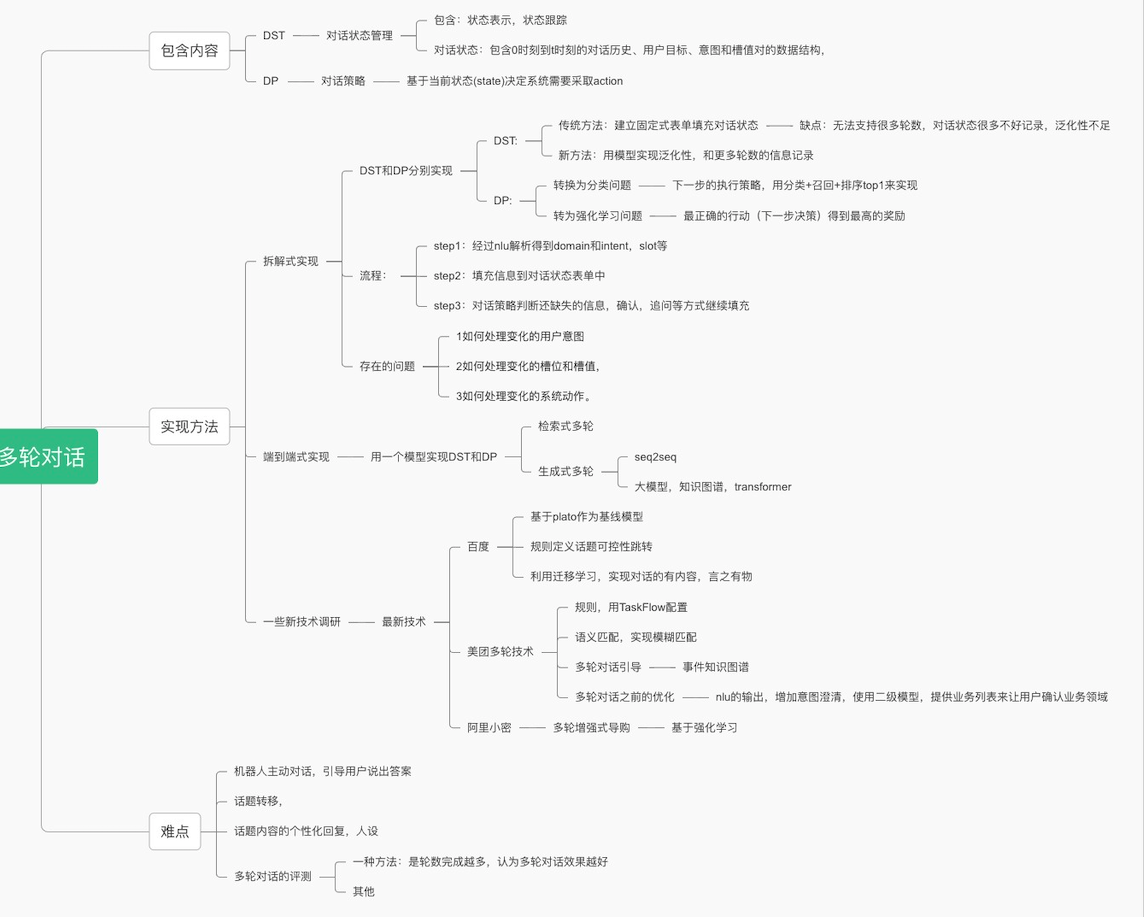
!DM的内容
包含了对话管理+对话策略
-
对话管理:
DST(Dialog State Tracking)就是根据所有对话历史信息推断当前对话状态St和用户目标。往往是pipeline对话系统中至关重要的一个模块,上接NLU,下接Policy。
如果把DST当做是一个黑盒的话,那么就可以简化为如下“输入–>输出”的形式,
- 输入往往包含:ASR、SLU 的输出结果N-best,系统采取的action,外部知识等等;
- 输出:对化状态St,用于选择下一步动作;
先配置不同对话节点,再根据对话顺序将节点连接起来形成对话流
对话节点:包括填槽,回复,函数等。
-
如何使用模型做对话管理
https://zhuanlan.zhihu.com/p/51476362建模型对象:对话状态建模。对话状态包括:对话历史,用户意图,槽值对,系统action等。
输入:意图、槽值对(Un)、系统上一步的动作(An-1)和上一步的状态(Sn-1)。 输出:当前状态(Sn)。举例:用CRF对DST建模的方法
输入: 1.对话序列,包括一系列的用户和系统的对话轮,包含用户话语U和系统动作A。这些都能转换为特征向量。 2.特征向量,包含用户话语中提取中的特征,例如意图信息,历史状态信息,槽值依赖,关键词匹配,词性标注等。 输出: 1.状态序列。预测出的最可能的状态序列 2.状态标签。标签表示了该时间的对话状态。比如用户是否已经提供了某个槽值,系统是否需要更多信息。
!多轮对话的实现方法调研
!我们是如何做DM的
论文:微软TCP
Task Completion Platform: A self-serve multi-domain goal oriented dialogue
platform
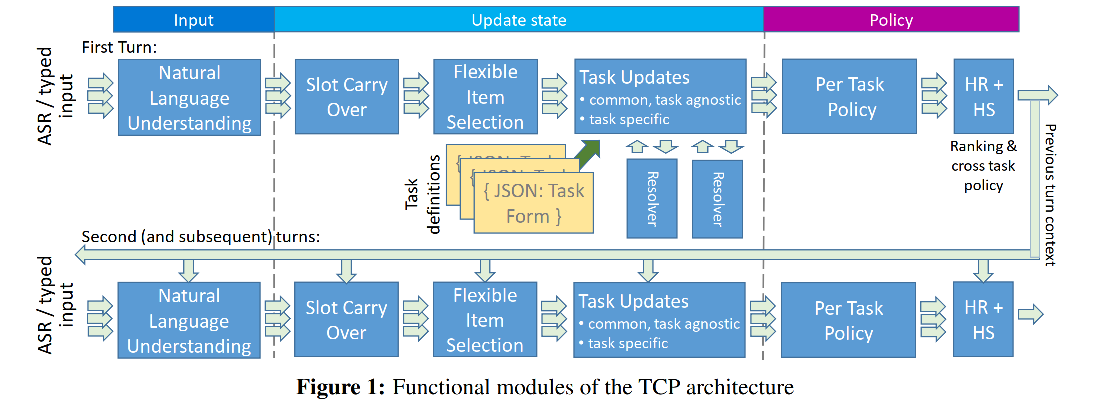
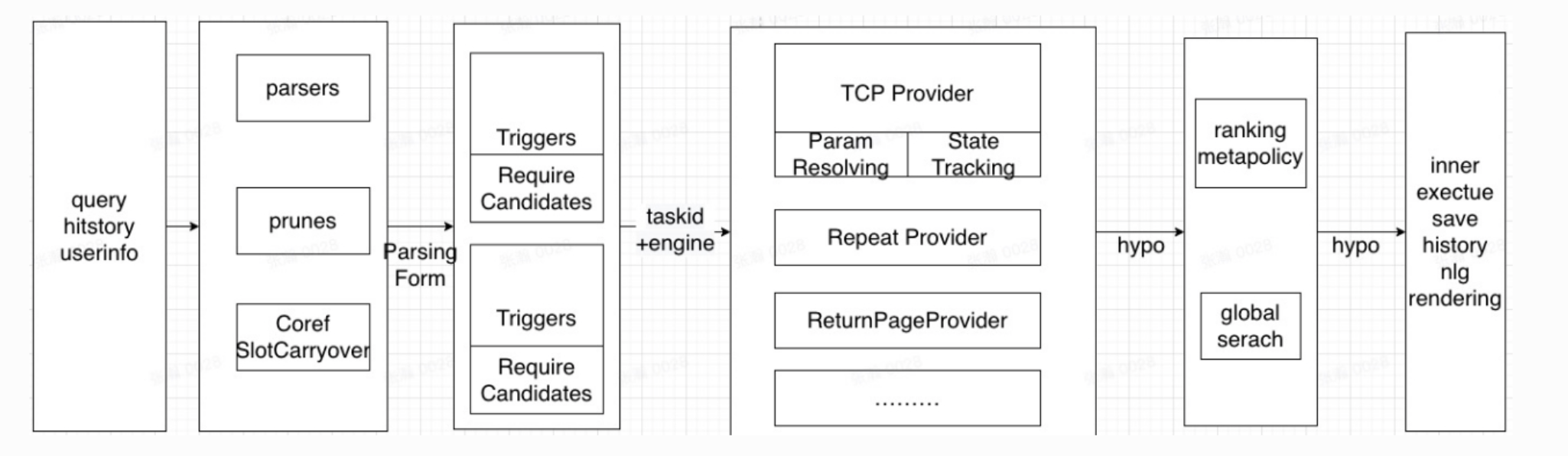
主要思路:
-
使用模块化架构,其对话管理过程被分为可以独立更新和改进的离散单元。核心模块包括输入的初步处理、对话状态更新和策略执行。
-
引入了一种名为TaskForm的任务配置语言,它允许任务定义与平台的对话策略分离。这种分离使得新任务的创建变得简单快捷,同时对话策略和平台功能可以独立于任务进行演进
-
多个NLU模型并行运行。每个模型专注提取其特定领域的意图和槽位。系统得到多个nlu模型的结果后,使用prune,裁减掉无slot的结果,或者其他不靠谱结果。最终保留两个到6个结果。
-
到达ranking阶段,使用不同的policy输出不同结果:ranking:单个挑选出来 metapolicy:两个合并起来 global serach:6个合并起来
-
SCO:slot carry over.使用规则和模型相结合的方式上下文传递slot。
规则传递:根据上⼀轮的domain以及intent,来判断本轮的domain和intent的规则
domain判断例子:
^(那){0,1}.{0,2}(明天|后天|大后天|今天|昨天|前天|大前天|听日)(的|嘅){0,1}(呢){0,1}$ && .context ||| public.weather => qa_classification: same; priority: 5含义为:
当该轮句子为:明天呢, 并且 前一句的domain是weather的情况下,该轮的domain与前轮一致。intent判断例子:(相同domain下的二轮)
例子:
^(那|那么){0,1}(换成|改成|改为|改成)?.{0,1}${time}.{0,1}$&& $..last_intent ||| rain =>rain如上,含义(大概为)
该轮句式为 “^(那|那么){0,1}(换成|改成|改为|改成)?.{0,1}${time}.{0,1}$” ,并且满足条件 “last_intent 为 rain的情况下,该轮的intent 也是rain。 -
上图中的ranking policy的含义:至少两个对话假设或者对话结果,要做判断,根据nlu结果,cpsp结果等,去掉一些结果。只输出有效的结果。
-
DM的输入内容

-
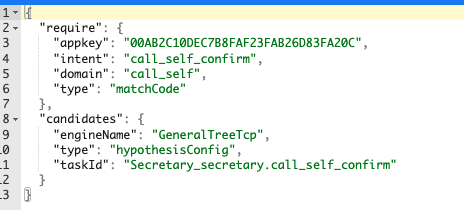
Triggers:一个触发器,使用appkey+domain+intent作为唯一索引。同一个task对应多个产品线的触发的话,要定义多个trigger。格式如下。意思是满足如下appkey+domain,intent输入下的taskID是。。。call_self_confirm. 也可以定义must_trigger utterances,表示必须满足某个出发语句,才会触发该行为。
-
Resolvers:一个对话解析器,对应一个垂直搜索,比如查询天气,心灵鸡汤,笑话等。用resolverid作为唯一标识
项目方面提问:
- 为何使用传统老旧的maxent,svm这些,而不是深度学习算法?
答:本项目有如下特点:
1.query属于超短文本
2.领域多,对应分类标签多
3.多产品线增量式迭代,协议持续更新
4.新老feature存在语义歧义或重叠
5.多平台,云端+嵌入式
6.模型需要受语义协议严格规约
传统机器学习算法,模型简单,细节清晰,迭代快,在线多个SVM二分类,快速迭代,最小范围更新;离线Max Entropy 多分类,模型小,内存占用小,速度快
对比:
CNN,自动特征提取,黑盒模型,训练慢,bug fix模型迭代复杂
预训练模型Bert/Albert,通用语言模型,蕴含通用知识,参数量大,训练慢,预测慢,迭代复杂
CRF,标配模型,特征模板复杂,提取特征能力有限
BiLSTM-CRF,自动特征提取,黑盒模型,速度慢,不能并行
Bert-CRF:OOV能力强悍,但对模型的控制比较难
!大模型发展和DM的结合
利用大模型构建任务型对话系统有以下优点:
- 避免了大量的有监督数据的标注问题。
- 多轮对话可以在闲聊和任务型对话之间无缝转换。
- 利用 Agent 来执行对话任务
- 便于业务冷启动,降低人工成本,模型泛化性好
有以下缺点:
-
回复内容的不确定性,无法知道某条语料和外部知识的对应关系,可能会生成不匹配的回复内容
-
推理性能的瓶颈。一般会存在多次的LLM推理调用,对话的实时性得不到保障
-
生成内容的不可控,可能输出有害言论。
解决:融合检索式回答,对敏感性提问,返回特定的回复内容。
-
在情感化,人设角色定制化,人格方面还有空间
详解参考 :
[]: 基于大模型如何做任务型对话/对话管理
一种做法是:用大模型去改造传统链路中的每个模块,比如用大模型去提升领域分类、意图识别、槽位抽取和对话管理等任务等。
如论文: Are Large Language Models All You Need for Task-Oriented Dialogue?
还有一种做法,用prompt限定对话内的topic,prompt限定可以采取的action。设计了一个能够自动管理话题和跟踪对话状态的AI代理。可以实现如下功能;
1.任务引导。用prompt限定对话topic后,可以主动对用户发起提问,来收集必要信息。
参考论文:DiagGPT: An LLM-based and Multi-agent Dialogue System with
Automatic Topic Management for Flexible Task-Oriented Dialogue
参考:
https://zhuanlan.zhihu.com/p/32716205 多轮对话之对话管理(Dialog Management)
https://mp.weixin.qq.com/s/6g9XTyLux9mIvIHrJNvUHg 对话系统之概述
https://blog.csdn.net/samurais/article/details/119809399 智能对话机器人之多轮对话工作机制 | Chatoper
https://mp.weixin.qq.com/s/cMYEp8J4SzU7yjGTF2TG9Q diaggpt: 基于大模型的多轮对话话题管理

















 2700
2700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









