







应用RAG(Retrieval Augmented Generation,检索增强生成)构建本地知识库,并与LLM(大模型)相结合,可有效解决LLM知识更新难问题,已成为专业领域智能问答的首选,下面就以Ollama+Deepseek+RAGFlow为例构建本地知识库应用。
1、基本原理
详见:
[LLM]:检索增强生成技术:RAG_llm rag技术-CSDN博客
2、下载并安装Ollama
下载并安装Ollama,Ollama是一个本地化部署大模型的工具,它提供简洁的命令行界面和丰富的功能选项,支持Deepseek、llama3、Phi3、Qwen、Gemma、Mistral等大模型,即便是普通用户也可以在本地快速部署和应用大模型。


3、在Ollama中下载模型
安装好Ollama后,桌面工具栏会出现![]() 图标,启动cmd窗口直接输入Ollama,可以看到Ollama的主要命令及使用方法。
图标,启动cmd窗口直接输入Ollama,可以看到Ollama的主要命令及使用方法。
。
下面以安装deepseek-r1:8b大模型为例,执行以下命令:
ollama pull deepseek-r1:8b
等待模型安装完毕,运行以下命令:
ollama run deepseek-r1:8b即可启动大模型开始输入问题。

Ctrl+D可退出ollama并返回cmd窗口。
接下来下载embedding模型(嵌入式模型),它将本地知识库进行向量化处理,执行命令:
ollama pull shaw/dmeta-embedding-zh:latest使用以下命令可以查看已安装的模型:
ollama list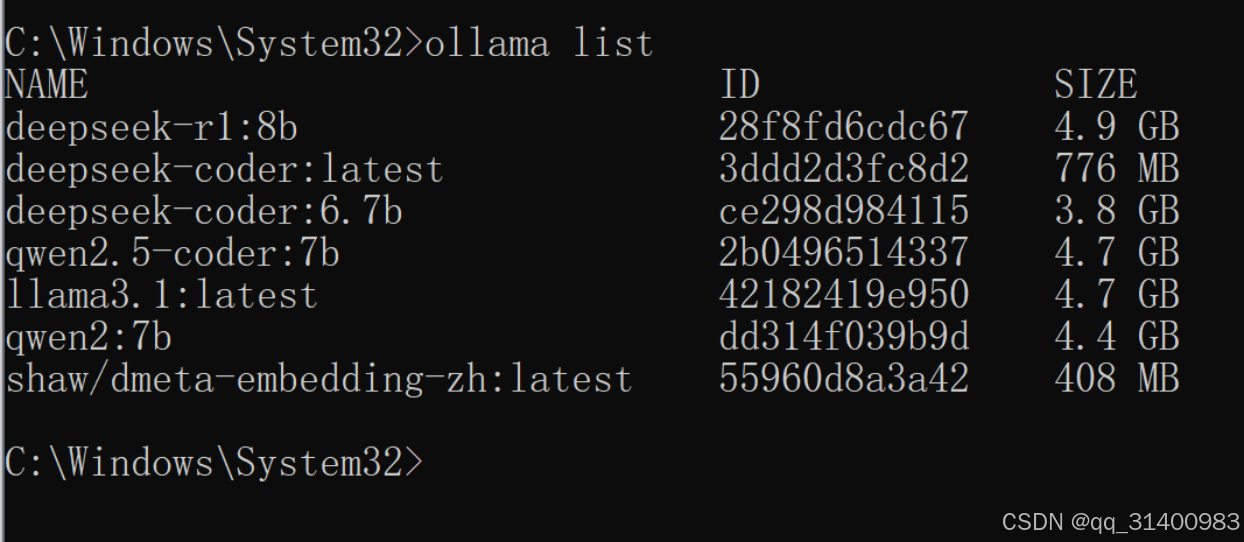
4、安装Docker

安装好和启动Docker Desktop。

(#此项非必须#)如果觉得命令行使用大模型不方便,也可在Docker安装Open WebUI,它可提供一个类似于ChatGPT的WEB界面使用大模型,命令如下:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main安装好后Docker显示如下:

访问http://localhost:3000/即可在WEB方式下使用ollama安装的大模型。
5、在Docker安装RAGFlow
运行以下命令:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
docker compose -f docker-compose-CN.yml up -d核心文件大小约为9GB,需要一段时间才能完成加载,完成后可执行以下命令检测服务器状态:
docker logs -f ragflow-server执行命令后如显示以下图形,表示安装成功。

然后网络浏览器中,输入服务器的IP地址(http://localhost/)即可登录RAGFlow(首次登录需进行注册)登录后设置为简体中文。

6、在RAGFlow中配置模型
(1)配置embedding模型
点击右上角“设置”,选择“模型提供商”,选择Ollama并添加模型。


设置模型类型为“embedding”,输入模型名称和模型Url后“确定”即可(IP地址就是本机IP,默认端口为11434)。
(2)配置chat模型
配置方法同上。
配置好模型后,可选择Ollama“展示更多模型”查看。

7、在RAGFlow中配置知识库
(1)创建知识库,选择模型
回到RAGFlow首页,进入“知识库”,选择“创建知识库”。
输入知识库名称,分别设置“语言”为“中文”、“嵌入模型”为“shaw/dmeta-embedding-zh:latest”。“解析方法”需根据自己创建的知识库类型进行选择,系统给出了每种方法的分块方法说明,以及支持的文件类型。

设置完成后“保存”。
(2)上传知识库文件
保存知识库设置后,系统自动进入数据集设置,选择“新增文件”,加载本地需上传的知识库文件(文件格式要符合知识库设置时限定的文件格式)。
我这里是简单构建了一个关于网络安全法的问答数据集。


(3)解析文件
点击解析状态下的![]() 开始解析文件,解析成功后就可以使用了。
开始解析文件,解析成功后就可以使用了。

8、知识库应用
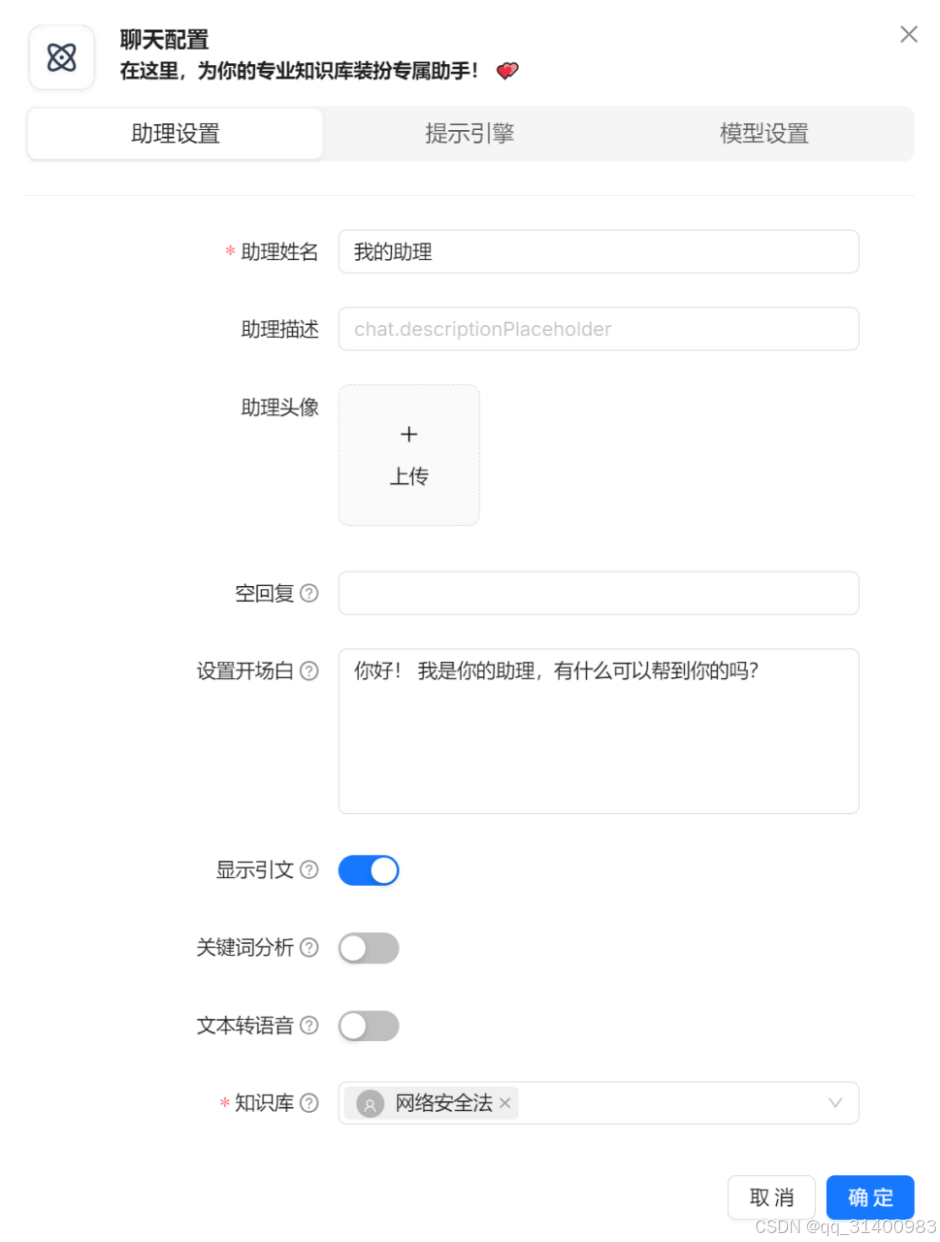
进入“聊天”,选择“新建助理”,在助理设置页面设置“助理姓名”,选择该助理要使用的知识库。
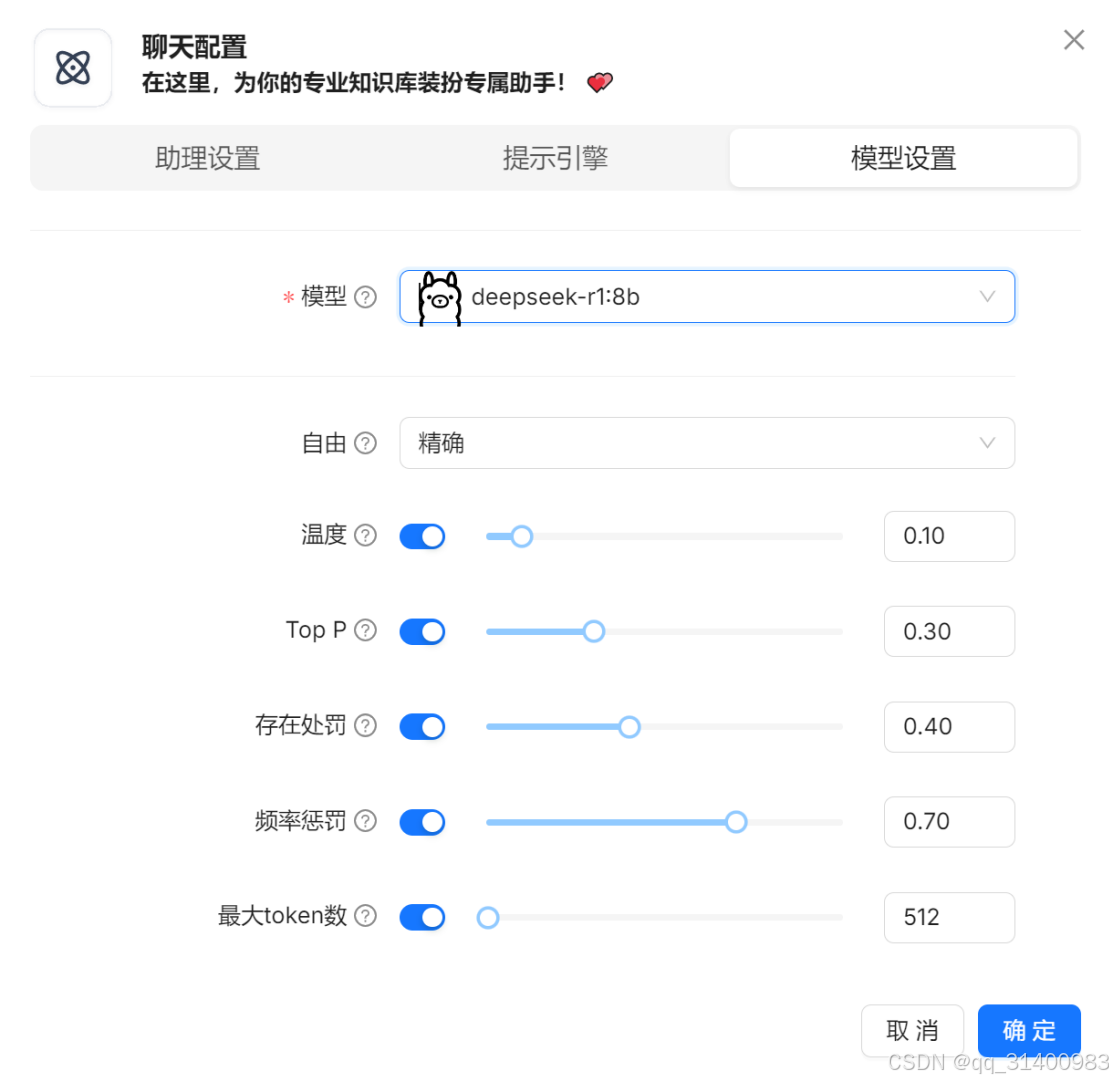
在模型设置页面选择要使用的模型,并选择“确定”。
接下来就可以在聊天窗口开始使用集成了本地知识库的大模型了。
选择设置好的助理,提出问题。
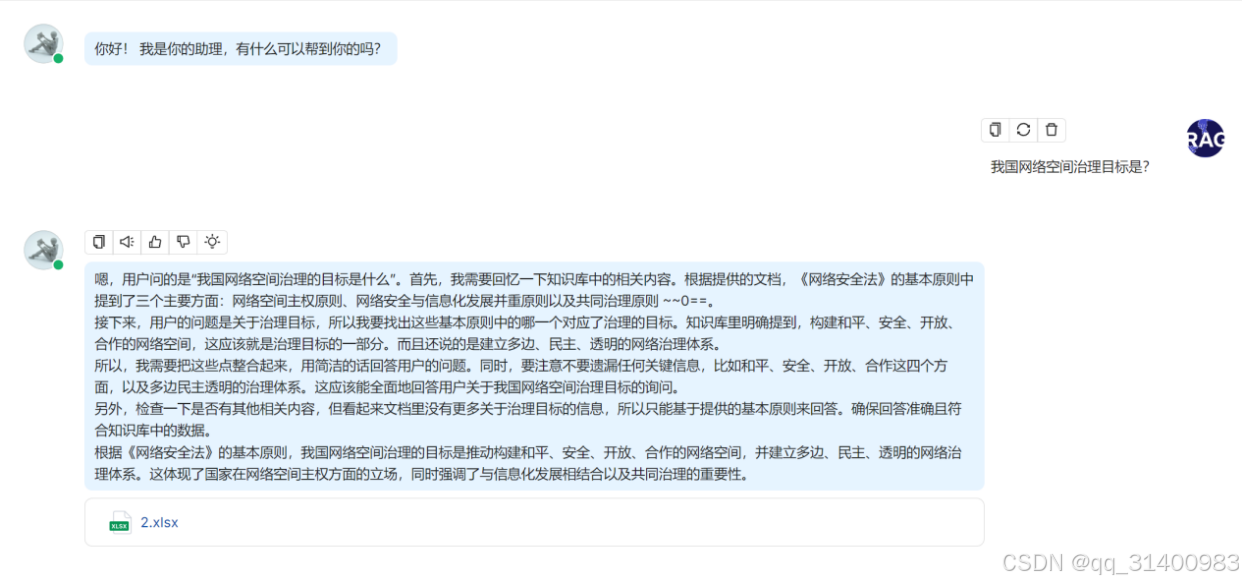
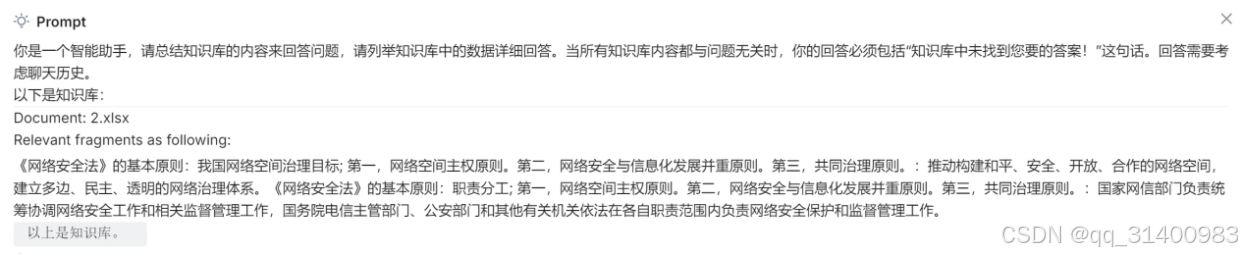
系统回答问题时会注明使用到的知识库文件,鼠标点击![]() 可弹出“Prompt”提示使用了知识库文件的哪些内容。
可弹出“Prompt”提示使用了知识库文件的哪些内容。

















 8704
8704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









