







论文阅读:DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification
论文信息
这是一篇发表在CVPR 2022的文章,论文获取地址为:https://openaccess.thecvf.com/content/CVPR2022/html/Zhang_DTFD-MIL_Double-Tier_Feature_Distillation_Multiple_Instance_Learning_for_Histopathology_Whole_CVPR_2022_paper.html
代码地址为:https://github.com/hrzhang1123/DTFD-MIL

摘要
多实例学习 (MIL) 越来越多地用于组织病理学全视野数字切片图像 (WSI) 的分类。然而,这种特定分类问题的 MIL 方法仍然面临独特的挑战,尤其是那些与小样本队列(small sample cohorts)相关的方法。在这些方法中,WSI(包)的数量有限,而单个WSI的分辨率很大,这导致了需要从该WSI中裁剪大量的补丁(实例)。为了解决这个问题,我们建议通过引入伪包的概念来虚拟扩大包的数量,在此基础上构建了一个双层 MIL 框架来有效地使用内在特征。此外,我们还对基于注意力的 MIL 框架下推导实例概率和利用这个推导来帮助构建和分析所提出的框架的工作有一定贡献。所提出的方法在 CAMELYON-16 上大大优于其他最新方法,并且在 TCGA 肺癌数据集上的性能也更好。所提出的框架已准备好扩展到更广泛的 MIL 应用程序。该代码可在以下网址获得:https://github.com/hrzhang1123/DTFD-MIL。
1. 引言
整个全视野数字切片图像 (WSI) 的自动化对计算机视觉领域提出了重大挑战。WSIs在组织病理学中越来越多的应用,导致数字病理学为病理学家的工作流程和诊断决策提供了巨大的改进[7,21,24,29,31],但它也刺激WSIS的智能或自动分析工具的需求[11,20,36,40,44,48,49]。WSIs的分辨率非常大,从100M到10G,这种独特的特性使得直接将现有的机器学习技术转移到它们的应用中几乎是不可行的,因为这些现有技术最初是针对尺寸小得多的自然图像或医学图像。在基于深度学习的模型方面,大规模数据集和高质量注释是训练高容量模型的主要但关键的条件。然而,WSI巨大的分辨率给像素级标注带来了巨大的负担。这个问题反过来鼓励研究人员开发基于深度学习的模型,这些模型使用有限的标注进行训练,称为“弱监督”或“半监督”[22,26,35,41]。现有WSI分类的弱监督工作很大一部分以“多实例学习”(MIL)为特点[1,5,8,25]。在 MIL 框架下,一张切片(或 WSI)由多个实例组成, 这些实例是从这个切片中裁剪出的数百或数千个补丁(patch)。如果这些实例中至少有一个实例是疾病阳性,那么整个WSI被标记为阳性,否则标记为阴性。
已经有一些成功的尝试解决在各种计算机视觉任务中的MIL问题 [19,27,28,30,32]。然而,WSI固有的特征使得研发针对WSI分类的MIL解决方案与其他计算机视觉领域的解决方案相比,并不那么简单。这是因为WSI分类训练的唯一直接指导信息是几百张切片的标签。最不好的结果是过拟合问题,其中机器学习模型在优化过程中倾向于陷入局部最小值,而学习到的特征与目标疾病的相关性较低,因此训练的模型泛化能力较差。
为了解决基于MIL的WSI分类中的过拟合问题问题,最近的大部分工作都是建立在除了在队列中相对较少的切片的标签之外,利用更多信息来学习的基本思想之上的。相互实例关系是为此目的探索的一个重要方向,它已被经验证明是有效的。相互实例关系可以指定为空间 [6] 或特征距离 [18, 35, 37, 46],也可以由神经网络 (RNN) [3]、transformer [34] 和图卷积网络 [51] 等神经模块不可知地学习。
上述许多方法尽管在注意力得分的公式上有所不同,但它们都是基于注意力机制的MIL(AB-MIL)[14]。然而,在AB-MIL框架下明确推断实例概率被认为是不可行的[18],作为一种替代方法,注意力得分通常被用作正激活的指示[10,14,18,34]。在本文中,我们认为注意力得分并不是一个严格的度量,相反,我们贡献了在AB-MIL框架下推导实例概率。
考虑到WSI分辨率非常大,能被直接处理的单元是从WSI[12]裁剪到的小得多的补丁(patch)。基于MIL框架的WSI分类本质上是识别最独特的补丁,这些补丁大都对应于切片的标签。然而,WSI的数量有限,而一张WSI中有数百甚至数千个补丁(实例),用于学习的信息仅是切片级别的标签。此外,在许多组织病理学切片中,与阳性疾病对应的阳性区域仅占组织的一小部分,这导致切片中阳性实例的比例很小。因此,在MIL条件下引导模型识别阳性实例是具有挑战性的,因为这些因素共同导致了过拟合问题的恶化。
尽管最近的方法利用相互实例关系来改进 MIL,但它们并没有明确地直面上述 WSI 的固有特征引起的问题。为了缓解这些问题的负面影响,我们在所提出的框架中引入了“伪包”的概念。也就是说,我们将包(切片)的实例(补丁)随机分成几个更小的包(伪包),并为每个伪包分配原始包的标签,称为父包。该策略虚拟增加了包的数量,而在每个伪包内部的实例较少;它还支持双层特征蒸馏MIL模型(图1)。更具体地说,将第一层(Tier-1)AB-MIL模型应用于所有切片的伪包。然而,它有一个来自阳性父包的伪包可能不会被分配至少一个阳性实例的风险,在这种情况下引入了错误标记的伪包。为了解决这个问题,我们从每个伪包中提取特征向量,并在从切片的所有伪包中提取的特征上建立第二层(Tier-2)AB-MIL模型(见图 3)。通过蒸馏过程,Tier-1 模型为 Tier-2 模型提供不同特征的初始候选者,以便为相应的父包生成更好的表示。此外,为了特征蒸馏,我们利用为可视化深度学习特征而开发的Grad-CAM的基本思想[33],推导出AB-MIL框架下的实例概率。


本质上,我们使用提出的双层 MIL 框架从另一个角度处理 WSI 分类的 MIL 问题。主要贡献是 :(1)我们引入了伪包的概念来缓解WSIs数量有限的问题。(2) 通过利用 Grad-CAM 的基本思想,我们在 AB-MIL 框架下推导出实例概率。给定 AB-MIL 是许多 MIL 工作的基础,实例概率推导可以帮助扩展相关 MIL 方法的研究。(3) 通过利用实例概率推导,我们制定了一个双层 MIL 框架,实验表明它在两个大型公共组织病理学 WSI 数据集上优于其他最新方法。
2. 相关工作
2.1. WSI分析中的多实例学习
为了证明弱监督学习的重要性,有一种趋势是开发用于 WSI 分析的 MIL 算法,其中只有切片标签可用于训练,而不是详细的像素级标注。MIL 模型通常可以分为两类,基于最终的包预测是否直接来自实例预测 [3, 9, 12, 15, 17, 47],或者来自实例特征的聚合[14, 18, 23, 34, 35, 42, 53]。对于前者,包预测通常通过平均池化(实例概率的平均值)或最大池化(实例概率的最大值)获得。相比之下,后者学习包的高级表示,并在该包表示上构建分类器以进行包级预测,通常称为包嵌入方法。尽管简单明了,但实例级概率池在经验上被证明不如包嵌入计数器的性能[34,42]。
许多基于包嵌入的模型采用AB-MIL的基本思想,即包嵌入(或包表示)是从单个实例的特征的权重中获得的,而这种最新工作的不同之处在于生成加权值的方法,通常称为注意力分数。例如,在原始论文 [14] 中,注意力分数由侧分支网络学习,在 DS-MIL [18] 中,注意力分数基于实例的特征与关键实例之间的余弦距离,而在Trans-MIL [34] 中,它们是TransFormer架构的输出,它对实例之间的相互关系进行编码。本质上,这些方法都是 AB-MIL,为了区分,我们将原始的 AB-MIL [14] 称为经典的 AB-MIL。我们提出的方法的主要组成部分也是基于注意力的,但它不限于生成注意力分数的方式。没有通用的损失函数,我们采用经典的 AB-MIL作为所提出框架中每一层的基本 MIL 模型。请注意,更改 AB-MIL 的其他变体将很简单,但不是本文的主要重点。
2.2. 基于梯度的类激活图
类激活图(CAM)[52]最初用作空间可视化工具,以揭示与深度学习模型分类相对应的图像中的位置。作为它最通用的版本,Grad-CAM (Grad-based Class Activation Map) [33] 能够从更复杂的多层感知 (MLP) 架构生成 CAM。许多工作不仅将 Grad-CAM 用作离线模型分析的强大工具,而且还作为为各种应用设计的深度学习模型中的嵌入组件。例如,CAM的一个显着能力是仅使用图像标签训练的模型的目标定位;因此,它在弱监督任务中盛行,例如分割 [4, 13, 16, 43] 和检测 [38, 45, 50],甚至知识蒸馏 [39]。
在本文中,我们证明了 AB-MIL 的框架是图像分类深度学习架构的一个特例。这一发现使得利用Grad-CAM的机制在ABMIL框架下直接推导出实例的阳性概率,推导有助于构建所提出的框架,也有助于相应的分析。
3. 方法
3.1. 回顾Grad-CAM和AB-MIL
3.1.1. Grad-CAM
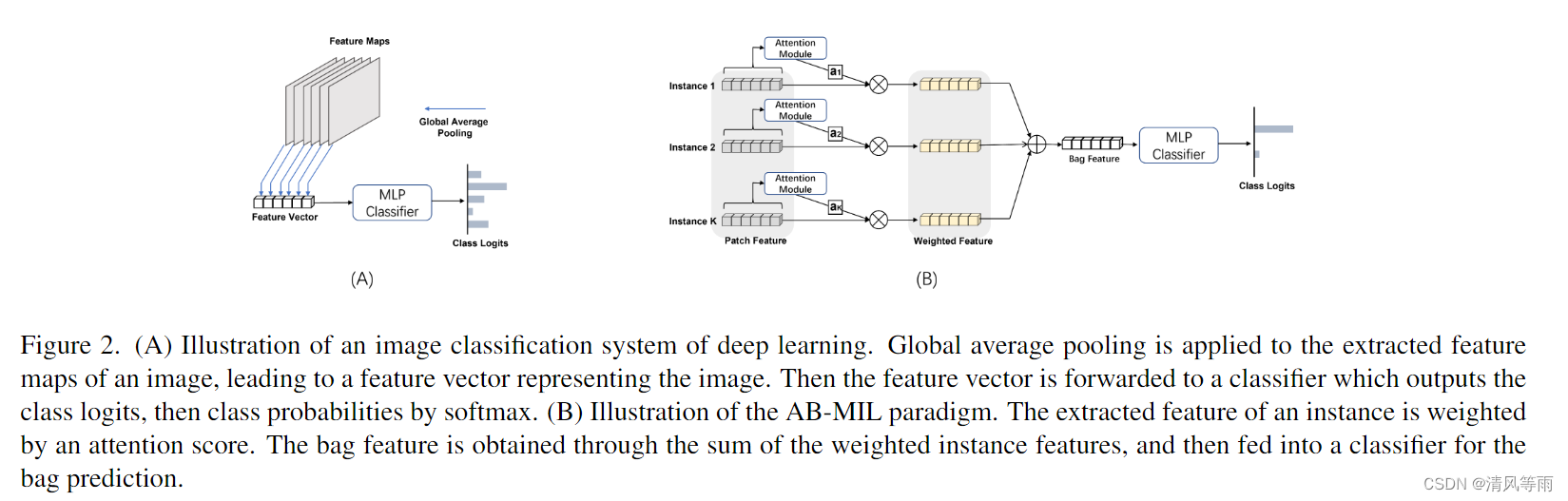
用于端到端图像分类的深度学习模型通常包括两个模块:用于高级特征提取的深度卷积神经网络 (DCNN) 和用于分类的多层感知器 (MLP)。将图像输入到DCNN中,生成特征图,随后通过池化操作成为特征向量。然后将特征向量前向传播到 MLP 以获得最终的分类概率(图 2.(a))。假设DCNN的最终输出特征图为
U
∈
R
D
×
W
×
H
U\in \mathbb{R}^{D×W ×H}
U∈RD×W×H,D为通道数,W, H分别为维数。对特征图施加全局平均池化会生成一个表示图像的特征向量,
f
=
GAP
W
,
H
(
U
)
∈
R
D
\begin{equation}f=\underset{W,H}{\operatorname*{GAP}}\left(U\right)\in\mathbb{R}^D\end{equation}
f=W,HGAP(U)∈RD其中
GAP
W
,
H
(
U
)
\underset{W,H}{\operatorname*{GAP}}\left(U\right)
W,HGAP(U)表示大小为H,W的全局平均池化操作,即
f
f
f的第
d
t
h
d_{th}
dth个元素,
f
d
=
1
W
H
∑
w
=
1
,
h
=
1
W
,
H
U
w
,
h
d
f_d = \frac1{WH}\sum_{w=1,h=1}^{W,H}U_{w,h}^{d}
fd=WH1∑w=1,h=1W,HUw,hd。将
f
f
f作为输入,MLP的输出作为类别
c
∈
{
1
,
2
,
…
,
C
}
c \in \left\{1, 2, \dots, C\right\}
c∈{1,2,…,C}的逻辑输出
s
c
s^c
sc,其值表示属于类别c的图像的信号强度,然后可以通过softmax操作相应地获得预测的类概率。Grad-CAM生成的类别c的类激活图定义为特征图的加权和,
L
c
=
∑
d
D
β
d
c
U
d
,
β
d
c
=
1
W
H
∑
w
,
h
W
,
H
(
∂
s
c
∂
U
w
,
h
d
)
,
\begin{equation}L^c=\sum_d^D\beta_d^cU^d,\quad\beta_d^c=\frac{1}{WH}\sum_{w,h}^{W,H}\left(\frac{\partial s^c}{\partial U_{w,h}^d}\right),\end{equation}
Lc=d∑DβdcUd,βdc=WH1w,h∑W,H(∂Uw,hd∂sc),其中
L
c
∈
R
W
×
H
L^c\in\mathbb{R}^{W\times H}
Lc∈RW×H,
L
w
,
h
c
L_{w,h}^c
Lw,hc是
L
c
L^c
Lc在w,h处的幅度值,表明该位置往往是类别c的强度,
L
w
,
h
c
=
∑
d
=
1
D
β
d
c
U
w
,
h
d
\begin{equation}L_{w,h}^c=\sum_{d=1}^D\beta_d^cU_{w,h}^d\end{equation}
Lw,hc=d=1∑DβdcUw,hd
3.1.2. 基于注意力机制的多实例学习
考虑一个包的实例为 X = { x 1 , x 2 , … , x K } X = \left \{x_1, x_2,\dots,x_K \right \} X={x1,x2,…,xK},其中K是包中的实例数。每个实例 x k x_k xk, k ∈ 1 , 2 , … , K k \in 1, 2,\dots, K k∈1,2,…,K持有一个潜在标签 y k y_k yk ( y k = 1 y_k=1 yk=1表示正, y k = 0 y_k=0 yk=0表示负),假设是 y k y_k yk不知道的。MIL的目标是检测包中是否存在至少一个阳性实例。然而,为训练的时候,唯一能揭示的信息是包标签,定义为, Y = { 1 , if ∑ k = 1 K y k > 0 0 , otherwise \begin{equation}Y=\begin{cases}1,&\text{if }\sum_{k=1}^Ky_k>0\\0,&\text{otherwise}\end{cases}\end{equation} Y={1,0,if ∑k=1Kyk>0otherwise即,如果其中至少有一个实例为阳性,则包为阳性,否则为阴性。这个学习问题的一个直接解决方案是为每个实例分配包标签并相应地训练分类器,然后对单个实例分类应用最大或平均池化操作来获得包级结果[42]。另一种流行的策略是从包中提取的实例特征中学习包表示 F \boldsymbol{F} F,然后将该问题成为传统的分类任务,即分类器可以在包表示上进行训练。根据经验,包表示学习的策略被证明比实例池化策略更有效,我们称之为基于包嵌入的 MIL。包嵌入表示为, F = G ( { h k ∣ k = 1 , 2 , . . . , K } ) , \begin{equation}\boldsymbol{F}=G\left(\left\{\boldsymbol{h}_k\mid k=1,2,...,K\right\}\right),\end{equation} F=G({hk∣k=1,2,...,K}),其中 G 是一个聚合函数, h k ∈ R D \boldsymbol{h}_k \in \mathbb{R}^D hk∈RD 是实例k提取的特征。通常,许多工作采用注意力策略来获得包表示(或嵌入),如下所示, F = ∑ k = 1 K a k h k ∈ R D , \begin{equation}\boldsymbol{F}=\sum_{k=1}^Ka_k\boldsymbol{h}_k\mathrm{~}\in\mathbb{R}^D,\end{equation} F=k=1∑Kakhk ∈RD,其中 a k a_k ak是 h k \boldsymbol{h}_k hk的可学习标量权值,D是向量 F \boldsymbol{F} F和 h k \boldsymbol{h}_k hk的维数。该范式如图 2(b) 所示。[14,18,23] 中的注意力机制遵循这个公式,因此它们都属于 AB-MIL 的类别,但在生成注意力分数(权重值) a k a_k ak 的方式上有所不同。例如,经典AB-MIL[14]的权重定义为, a k = exp { w T ( tanh ( V 1 h k ) ⊙ s i g m ( V 2 h k ) ) } ∑ j = 1 K exp { w T ( tanh ( V 1 h j ) ⊙ s i g m ( V 2 h j ) ) } , \begin{equation}a_k=\frac{\exp\{\boldsymbol{w}^\mathrm{T}(\tanh(V_1\boldsymbol{h}_k)\odot\mathrm{sigm}(V_2\boldsymbol{h}_k))\}}{\sum_{j=1}^K\exp\{\boldsymbol{w}^\mathrm{T}(\tanh(V_1\boldsymbol{h}_j)\odot\mathrm{sigm}(V_2\boldsymbol{h}_j))\}},\end{equation} ak=∑j=1Kexp{wT(tanh(V1hj)⊙sigm(V2hj))}exp{wT(tanh(V1hk)⊙sigm(V2hk))},其中 w \boldsymbol{w} w, V 1 V_1 V1和 V 2 V_2 V2为可学习参数。
3.2. AB-MIL中实例概率的推导
尽管基于包嵌入的 MIL 具有更好的性能,但被认为解开实例的类别的概率是不可行的[18, 42]。然而,在本文中,我们表明可以在 AB-MIL 框架下推导出包中每个单独实例的预测概率。这种推导植根于以下命题,
命题 1 AB-MIL 的范式是用于图像分类的经典深度学习网络框架的一个特例 。(证明和解释在补充中。)
基于命题 1,可以安全地将 Grad-CAM 的机制应用于 AB-MIL 以直接推断实例作为某个类的信号强度。类似于等式(2),例如 k 为 c 类(c = 0 表示负数,c = 1 表示正数)的信号强度可以推导出为(见补充), L k c = ∑ d = 1 D β d c h ^ k , d , β d c = 1 K ∑ i = 1 K ∂ s c ∂ h ^ k , d \begin{equation}L_k^c=\sum_{d=1}^D\beta_d^c\hat{h}_{k,d},\quad\beta_d^c=\frac1K\sum_{i=1}^K\frac{\partial s_c}{\partial\hat{h}_{k,d}}\end{equation} Lkc=d=1∑Dβdch^k,d,βdc=K1i=1∑K∂h^k,d∂sc其中 s c s_c sc是MIL分类器中c类的输出概率, h ^ k , d \hat{h}_{k,d} h^k,d是 h ^ k \hat{h}_{k} h^k的第 d 个元素, h ^ k = a k K h k \hat{h}_k= a_kKh_k h^k=akKhk中的 a k a_k ak是等式(6)中定义的实例 k 的注意力分数。通过应用 softmax,则相应的概率, p k c = exp ( L k c ) ∑ t = 1 C exp ( L k t ) \begin{equation}p_k^c=\frac{\exp\left(L_k^c\right)}{\sum_{t=1}^C\exp\left(L_k^t\right)}\end{equation} pkc=∑t=1Cexp(Lkt)exp(Lkc)
3.3. 双层特征蒸馏多实例学习
在本节中,我们将介绍所提出的双层特征蒸馏 MIL 框架。
给定 N 个包(切片),在每个包中都有
K
n
K_n
Kn个实例(补丁),即
X
n
=
{
x
n
,
k
∣
k
=
1
,
2
,
…
,
K
n
}
X_n = \left \{x_{n,k} \mid k = 1, 2,\dots, K_n\right \}
Xn={xn,k∣k=1,2,…,Kn},
n
∈
{
1
,
2
,
…
,
N
}
n \in \left \{1, 2,\dots, N \right \}
n∈{1,2,…,N},包的真实标签是
Y
n
Y_n
Yn。实例对应的特征记为
h
n
,
k
h_{n,k}
hn,k,由骨干网H提取,即
h
n
,
k
=
H
(
x
n
,
k
)
h_{n,k} = H (x_{n,k})
hn,k=H(xn,k)。包(切片)中的实例被随机分成具有近似相等实例的M个伪包,
X
n
=
{
X
n
∣
m
=
1
,
2
,
…
,
M
}
X_n = \left \{X_n \mid m = 1, 2,\dots, M \right \}
Xn={Xn∣m=1,2,…,M}。伪包被分配了其父包标签的标签,即
Y
n
m
=
Y
n
Y_n^m = Y_n
Ynm=Yn。在 Tier-1 中,将表示为
T
1
T_1
T1的AB-MIL模型应用于每个伪包。假设伪包通过Tier-1模型的估计包概率为
y
n
m
y_n^m
ynm ,
y
n
m
=
T
1
(
{
h
k
=
H
(
x
k
)
∣
x
k
∈
X
n
m
}
)
,
\begin{equation}y_n^m=\mathrm{T}_1\big(\{\boldsymbol{h}_k=\mathrm{H}\left(x_k\right)\mid x_k\in\boldsymbol{X}_n^m\}\big),\end{equation}
ynm=T1({hk=H(xk)∣xk∈Xnm}),训练的 Tier-1的损失函数用交叉熵损失,定义为,
L
1
=
−
1
M
N
∑
n
=
1
,
m
=
1
N
,
M
Y
n
m
log
y
n
m
+
(
1
−
Y
n
m
)
log
(
1
−
y
n
m
)
\begin{equation}\mathcal{L}_1=-\frac1{MN}\sum_{n=1,m=1}^{N,M}Y_n^m\log y_n^m+(1-Y_n^m)\log{(1-y_n^m)}\end{equation}
L1=−MN1n=1,m=1∑N,MYnmlogynm+(1−Ynm)log(1−ynm)之后,使用 Eq.(8) 和 Eq.(9) 推导出每个伪包中实例的概率。基于导出的实例概率,提取每个伪包的特征,表示为第 n 个父包的第 m 个伪包的
f
^
n
m
\hat{f}_n^m
f^nm。所有蒸馏的特征都被转发到 Tier-2 AB-MIL,表示为
T
2
T_2
T2,用于父包的推理,
y
^
n
=
T
2
(
{
f
^
n
m
∣
m
∈
(
1
,
2
,
.
.
.
,
M
)
}
)
\begin{equation}\hat{y}_n=\mathrm{T}_2\left(\left\{\hat{f}_n^m\mid m\in(1,2,...,M)\right\}\right)\end{equation}
y^n=T2({f^nm∣m∈(1,2,...,M)})训练
T
2
T_2
T2的Tier-2损失函数为,
L
2
=
−
1
N
∑
n
=
1
N
Y
n
log
y
^
n
+
(
1
−
Y
n
)
log
(
1
−
y
^
n
)
,
\begin{equation}\mathcal{L}_2=-\frac1N\sum_{n=1}^NY_n\log\hat{y}_n+(1-Y_n)\log(1-\hat{y}_n),\end{equation}
L2=−N1n=1∑NYnlogy^n+(1−Yn)log(1−y^n),所以整体优化过程为:
{
θ
1
,
θ
2
}
=
arg
min
θ
1
L
1
+
arg
min
θ
2
L
2
\begin{equation}\{\boldsymbol{\theta}_1,\boldsymbol{\theta}_2\}=\arg\min_{\boldsymbol{\theta}_1}\mathcal{L}_1+\arg\min_{\boldsymbol{\theta}_2}\mathcal{L}_2\end{equation}
{θ1,θ2}=argθ1minL1+argθ2minL2其中
θ
1
\theta_1
θ1和
θ
2
\theta_2
θ2分别是
T
1
T_1
T1和
T
2
T_2
T2的参数。需要注意的是,伪包存在一定比例的噪声标签,因为伪包可能无法通过随机分配分配至少一个正实例。而深度神经网络在一定程度上对噪声标签具有弹性。此外,噪声水平可以由每个父包中的伪包的数量大致控制,即 M。我们展示了 M 的值如何影响消融研究部分中提出的方法的性能。
四种特征蒸馏策略如下:
- MaxS 最大选择:选择伪包中实例的特征,该伪包从 Tier-1 MIL 模型中获得最大正概率,前向传播到 Tier-2 MIL 模型。
- MaxMinS MaxMin 选择:提取伪包中两个实例的特征并连接到 Tier-2 模型:具有最大概率的实例和伪包中概率最小的实例的特征。这样的选择是基于以下的考虑:如果只选择每个伪包中具有最大正概率的实例(如 MaxS 的情况),则经过训练的 Tier-2 模型的决策边界将倾向于过于紧密地推向正样本,并且可能会错过与负样本相似的真正情况 [47]。通过引入最大和最小概率的实例,它为 Tier-2 模型提供了松散的空间来生成父包的特征嵌入。
- MAS 最大注意力分数选择:将Tier-1 MIL 模型中具有最大分配注意力分数的伪包中实例的特征提炼到 Tier-2 MIL 模型中。
- AFS 聚合特征选择:从伪包中的所有实例聚合的特征,如Eq.(6)所示,被转发Tier-2模型。
我们在实验部分评估了这 4 种策略的性能。
4. 实验
在本节中,我们展示了与其他方法相比,所提出的方法在组织病理学 WSI 上的其他最新 MIL 工作的性能,并定性地验证了实例概率推导的可靠性。我们还进行消融研究以进一步研究所提出的方法。更多的实验结果在补充材料中给出。
4.1. 数据集
我们在两个公共组织病理学WSI数据集上评估了所提出的方法:CAMELYON-16[2]和Caner基因组图谱(TCGA)肺癌。有关这两个数据集的详细信息,请参阅补充。
对于预处理,我们应用OTSU的阈值方法对每个WSI中的组织区域进行定位。然后从组织区域提取20X放大倍率上大小为256 × 256像素的非重叠补丁。CAMELYON-16数据集共有 370万个补丁,TCGA Lung Cancer 数据集中有 830百万个补丁。
4.2. 实施细节
实现在补充材料中描述。有关详细信息,请参阅发布的代码。
4.3. 评估指标
对于所有实验,曲线下面积 (AUC) 是报告的主要性能指标,因为它对类别不平衡更加全面和不太敏感。此外,还考虑了切片级精度 (Acc) 和F1分数,该分数由0.5的阈值决定。
对于 CAMELYON-16,官方训练集进一步随机分为训练集和验证集,比例为 9:1。实验运行 5 次,报告 CAMELYON-16 官方测试集上的性能指标平均值和相应的 95% 置信区间 (CI-95)。对于 TCGA 肺癌,我们在患者水平上以 65:10:25 的比例将数据集随机分成训练集、验证集和测试集。采用4倍交叉验证,并报告4个测试文件夹性能指标的平均值。由于对于每个测试文件夹,性能差异很大,只有 4 个值的 CI-95 使用较少;因此,我们改为报告相应的标准方差。
4.4. 与现有方法的性能比较
与以下方法相比,我们展示了所提出的方法在 CAMELYON-16 和 TCGA 肺癌数据集上的实验结果:(1)传统的实例级 MIL,包括 MeanPooling 和 Max-Pooling。(2) 基于 RNN 的 RNN-MIL [3]。(3) 经典的 AB-MIL [14]。(4) AB-MIL的三种变体,包括非局部注意池DSMIL[18]、单注意分支CLAM-SB[23]和多分支CLAM-MB[23]。(5)基于Transformer的MIL,Trans-MIL[34]。所有其他方法的结果来自在相同设置下使用官方代码进行的实验。如表1所示,除了Trans-MIL外,所提出的模型与其他工作的模型具有相似的模型大小和计算复杂性,而Trans-MIL在模型大小和计算复杂性方面要大得多。
CAMELYON-16 测试集的结果如表 1 所示,而 TCGA 肺癌的结果如表 2 所示。一般来说,实例级方法(平均池化、最大池化)在性能上不如基于包嵌入的方法。
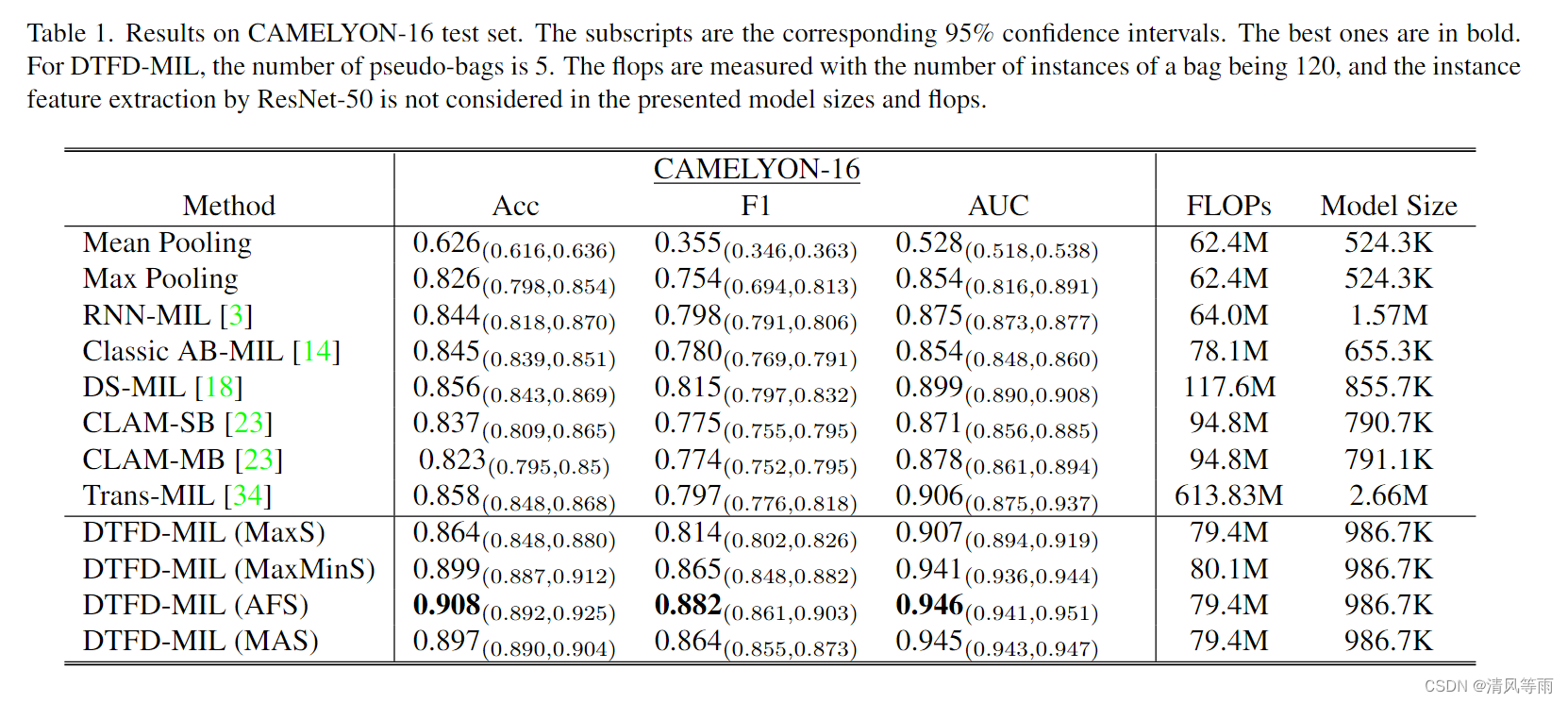

对于 CAMELYON-16,大多数阳性切片在整个组织区域仅包含一小部分肿瘤。在提出的具有不同特征提取的 DTFD-MIL 方法中,MaxS 的性能最差,但除了最近的 Trans-MIL 之外,它仍然优于其他现有的 MIL 方法。其他 3 个 DTFD-MIL 实现了相似的性能,明显优于其他。例如,与其他现有方法相比,DTFD-MIL(AFS) 在 AUC 中至少高出 4%。
对于TCGA肺癌,除了DTFD-MIL(MaxS),所提出的方法也取得了领先的性能,DTFD-MIL(MaxMinS)获得了96.1%的最佳AUC值。然而,由于阳性切片中的肿瘤区域明显更大,即使是实例级方法在TCGA肺癌数据集上也能表现良好,导致所提出的方法相对于其他现有方法的优越性不太明显。相比之下,对于更具挑战性的数据集 CAMELYON-16,所提出的方法对阳性切片中肿瘤区域的一小部分情况表现出更强的鲁棒性。
4.5. 检测结果的可视化
为了进一步探索所提出的实例概率推导,我们训练了一个经典的 AB-MIL 模型,并从 CAMELYON16 生成 5 个切片的 5 个子领域的热图。这些热图来自(1)归一化注意力分数(基于注意力的); (2) 分别由等式(8)和等式(9)的补丁概率推导(基于推导)。直接来自注意力模块的注意力分数归一化为
a
k
′
=
(
a
k
−
a
min
)
/
(
a
max
−
a
min
)
a_k^{'}=\left(a_k-a_{\min}\right)/\left(a_{\max}-a_{\min}\right)
ak′=(ak−amin)/(amax−amin)[14,18,23,34],其中
a
m
i
n
a_{min}
amin 和
a
m
a
x
a_{max}
amax 分别是切片中补丁的最小和最大注意力分数。为了更好地展示,我们删除了基于推导的热图(第三行)中补丁的估计概率,其值在 0.5 左右,因此包含的信息很少。
图 4 中的热图显示了与注意力分数相比,实例概率推导在定位正激活方面的更好能力。具体来说,通过实例概率推导的热图中的正激活更加一致和准确,并且与注意力分数相比表现出更好的对比。此外,在真实标签的阴性切片中,注意力分数热图中总是有很强的假阳性区域,而在实例概率推导的热图中,这些区域中的大多数可以被正确识别为阴性。在补充材料中,我们对为什么与注意力分数相比,实例概率推导对于正激活检测更有效率进行了更深入的分析。

4.6. 消融研究
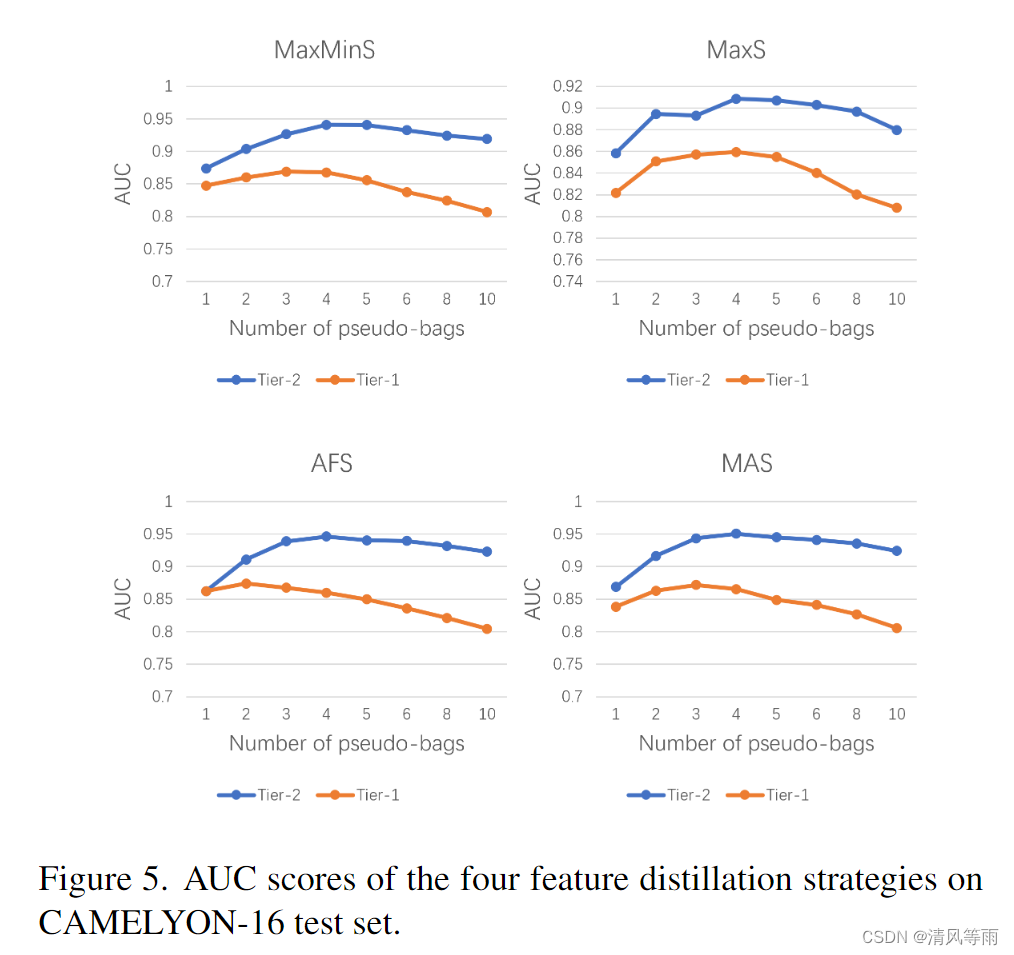
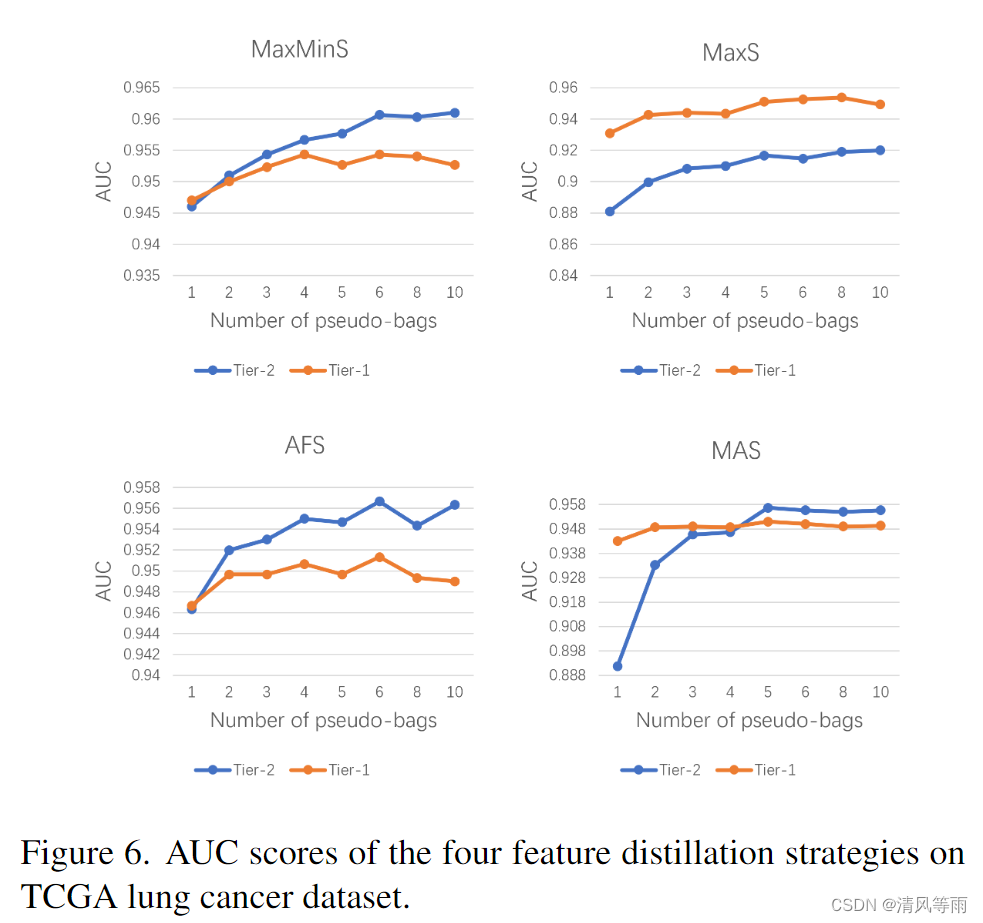
图5和图6分别为CAMELYON-16和TCGA肺癌数据集上不同数量的伪包的AUC评分。在每个子图中,蓝色曲线表示 Tier-2 MIL 模型,而红色曲线表示直接处理伪包的 Tier-1 MIL 模型。
从这些曲线中,我们可以总结:
- 伪包思想有利于 Tier-1 和 Tier-2 MIL 模型。然而,Tier-1 模型对 CAMELYON16 中的伪包数量更敏感:随着伪包数量的增加(到3),相应的 AUC 分数急剧下降。相比之下,Tier1 模型对 TCGA 肺癌数据集中的伪包数量不太敏感,并且即使使用适当数量的伪包也能实现高级性能。这种现象主要是由于肿瘤通常是 CAMELYON-16 阳性切片中的次要区域,而在 TCGA 肺癌中,情况逆转;因此,在 CAMELYON-16 中,伪包可能无法从阳性父包中至少分配一个正实例。这很好地证明了我们的初始动机,即在相应伪包的蒸馏特征上构建第二层 MIL 模型,并且通常 Tier-2 模型的性能确实优于 Tier-1 模型,尤其是在 CAMELYON-16 中。
- 在四种特征蒸馏策略中,DTFD-MIL (MaxS) 性能不能与其他三种相媲美,在 TCGA 肺癌数据集上,当使用 MaxS 特征蒸馏时,Tier-2 MIL 模型甚至不如 Tier-1 MIL 模型。这意味着采用具有最高正响应的实例来形成包的表示并不总是最佳选项。这种现象也符合图4的观察结果,其中负切片中最强的激活来自中性甚至空白区域(对应于肿瘤大约零概率),而不是非肿瘤组织区域。
5. 结论
本文的第一个贡献是在 AB-MIL 框架下推导实例概率,我们定性地证明了导出的实例概率是正区域检测广泛使用的注意力分数更可靠的度量。然后我们提出了 DTFD-MIL,它利用了伪包和双层 MIL 的思想。实例概率的推导用于 DTFD-MIL 中的特征蒸馏。实验结果表明,所提出的 DTFD-MIL 确实为解决具有优异性能的 MIL 问题提供了新的视角,而不是像其他最新作品那样利用相互实例关系。最后,我们还期望实例概率的推导将作为开发相关 MIL 模型或未来工作中的相关分析的有用工具,就像它在本文提出的 DTFD-MIL 中所起的作用一样。
总结
这篇文章主要是创新性的引入了伪包的概念,通过伪包来增加阳性区域(也就是肿瘤区域)占包(WSI)的面积,从而加大模型对阳性区域的关注。伪包的标签是通过父包(就是原始WSI)的标签。但是伪包中的实例则是随机分配,这就导致了如果父包是阳性(即有癌症区域),那么伪包可能不能至少分配一个阳性实例(也就是可能会出现伪包是阳性标签,但里面的实例却全部都是阴性的)。虽然作者通过特征蒸馏等方式来降低这个影响,但并不能消除这个影响。
此外,文中有很多地方并没有讲述的很清楚,而是放在了补充细节里面。这可能是因为CVPR的篇幅限制。因此,之后找到补充细节再将其在微信公众号中进行补充。


















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









