






 N-BEATS是一种深度学习模型,专为时间序列预测设计,强调可解释性。模型通过基础Block和双残差Stack实现预测,其中基础函数可以是通用结构或具有解释性的趋势和季节性模型。实验表明,N-BEATS在M4等数据集上表现出色,且可解释性结构在趋势和季节性分解上优于通用结构。模型通过集成多个变体提升预测性能,并在实际应用中可能需要考虑预测长度和数据粒度的影响。
N-BEATS是一种深度学习模型,专为时间序列预测设计,强调可解释性。模型通过基础Block和双残差Stack实现预测,其中基础函数可以是通用结构或具有解释性的趋势和季节性模型。实验表明,N-BEATS在M4等数据集上表现出色,且可解释性结构在趋势和季节性分解上优于通用结构。模型通过集成多个变体提升预测性能,并在实际应用中可能需要考虑预测长度和数据粒度的影响。

论文:ICLR2020 | N-BEATS: NEURAL BASIS EXPANSION ANALYSIS FOR INTERPRETABLE TIME SERIES FORECASTING [1]
代码:https://github.com/ElementAI/N-BEATS
录播:https://www.bilibili.com/video/BV1zP4y177x6?spm_id_from=333.999.0.0
引用量:149
一、介绍
在M4竞赛中,前排基本都用机器学习的方法,但赢家们还结合了传统统计模型,例如选手Smyl的方法是:带残差/关注机制的神经空洞LSTM + 经典Holt-Winter统计模型。受到M4竞赛的启发,作者想探究在TS预测背景下的纯DL模型结构,同时想让模型具有可解释性,让模型能够抽取可解释性因子后,给出预测结果。
N-BEATS的贡献主要有两点:
● 深度神经结构:没用时序特别组成成分,用单纯的DL也能超过M3和M4竞赛中做的好的统计方法。
● 对时序可解释的DL:N-BEATS模型能跟传统时序中”seasonality-trend-level“的方法(序列分解)相近,输出的结果具有可解释性。
二、问题声明
先了解下离散时间下单一时序点预测的评估函数:MAPE、sMAPE、MASE和OWA。
1. MAPE
MAPE为mean absolute percentage error: ● 优点:忽略时序scale的影响,可以对比多条序列。
● 缺点:真实值有0的话,无法计算。
2. sMAPE
sMAPE为symmetric mean absolute percentage error。 ● 优点:避免当真实值为0时,MAPE会变很大的情况。另外当预测值/真实值均为0值,达到sMAPE的上限200%。
● 缺点:文章[2]提到,sMAPE在修正无边的不对称性的同时,引入了另一种由公式的分母引起的微妙的不对称性。假设有真实值A=100和预测值F=120。sMAPE为18.2%。现在是一个非常相似的情况,其中真实值=100,预测值F=80。在这里,我们得出的sMAPE为22.2%。
3. MASE
MASE为mean absolute scaled error[3]。 m为周期数,当m=1,为non-seasonal MASE。分母是 in-sample one-step naive forecast method的预测结果,这种预测方法是:t时刻预测值 = t-1时刻真实值。
● 优点:scale-independent。另外,不像MAPE在真实值趋向于0时,误差会变得很大。对称性很好,sMAPE对大和小预测值上误差不一致,预测小的会更大误差。因此sMAPE的对称性没那么好,MASE便不会如此。
4. OWA:
OWA是M4竞赛里面用的指标overall weighted average:分母是使用Naive2方法下的MAPE和sMAPE。 ïï在M4文档[4]中,有提及Naive方法就是t时刻预测值 = t-1时刻真实值,而在Naive2的M4代码[5]中,是先将序列进行乘性序列分解,然后原始序列/季节序列便得到seasonally-adjusted时序,之后用Naive即可。
Dec <- decompose(input,type="multiplicative")
des_input <- input/Dec$seasonal
...
f3 <- naive(des_input, h=fh)$mean*SIout #Naive2三、N-BEATS
我们先看下N-BEATS整体结构示意图,再细聊结构中的各个模块:
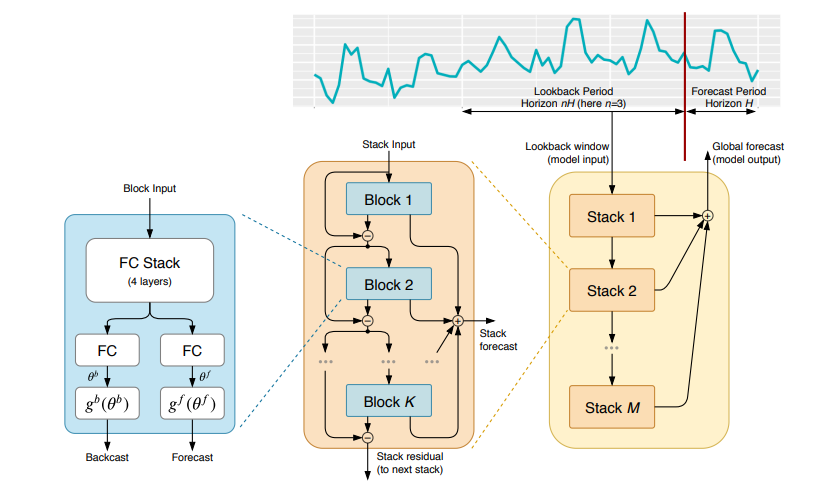
图1:N-BEATS结构图
1. 基础Block
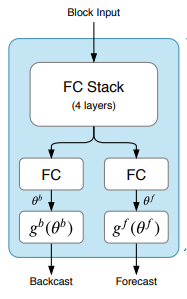
图2:Block
先看图1左边的Block,N-BEATS有多个Block:
● 第1个Block的输入是:真实窗口序列 ;
●第2个Block开始便是:上一步窗口的残差序列 。
x窗口长度在2H-7H之间,H为预测长度。Block的输出是对当前窗口时刻点的预测 (Backcast)和对未来预测窗口内时刻点的预测 (Forecast)。
Block包括两部分:
● FC网络:输出前向放大系数(expansion coefficient) 和后向放大系数 ;
● 基础层:基础层(basis layer)接收前后向放大系数,输入基础函数(basis function),输出前后序列的预测结果 和 。
Block的操作如下:
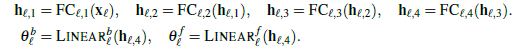
FC Stack内,每层的函数是RELU+FC,以FC Stack中第一层为例,它是 。而后面的FC便只是简单的线性映射层 。
基础函数 和 是用于剔除输入数据中对预测无用的部分。基础函数的具体内容会在后面细讲。
2. 双残差Stack
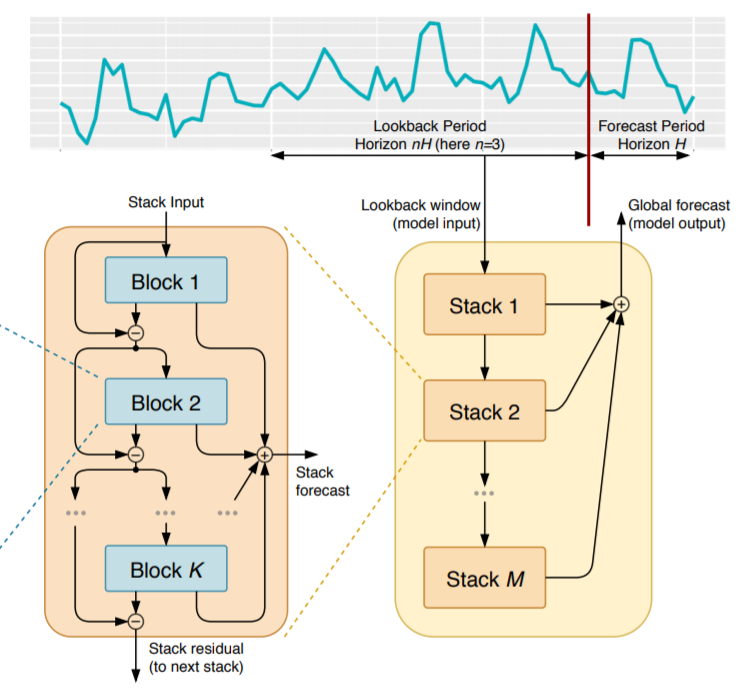
图2:双残差Stack
图2能看到两个残差分支:
● 后向预测: ;
● 前向预测: 。
上游Block把 中无用部分移除掉,这使得下游Block的预测任务更容易。从预测上看,Block的输出由浅到深,是个层次分解的过程,每个Stack的输出是由各Block预测值求和得到。
3. 解释性
对前面的基础函数 和 ,作者提供两种方法:一种通用DL结构,一种是用于模型解释的结构。
(1) 通用结构
此结果不依赖于TS的领域知识,block的输出如下:
的维度是 ,其中H是预测长度。 第一个维度是表示预测的时间长度,第二维度是对应每个放大系数,因此每一列的 可以看作是有一种时序波形,预测结果相当于多个波形的加权求和。该通用函数的弊端在于解释性差。
(2) 可解释性结构
时序分解成趋势和季节性,常用STL方法,但作者设计了一种将趋势和季节性分解嵌入模型中,使得Stack输出更具解释性的结构。
● 趋势模型:采用多项式函数(degree p较小,2或3)来描述缓慢变化的时序趋势。 其中 ,相当于 (x为uniform-distributed),t的范围在[0,1),让模型学习\theta,获取趋势。比如t=0,趋势 ,数据样例可访问[6]。
● 季节性模型:使用傅里叶级数。 有H行,其中分一半参数给cos,一半参数分给sin。
整个可解释性结构,包括2个stack:第一个为trend stack,第二个为seasonal stack。每个stack有3个blocks,所以2个stack就有6个blocks。而通用结构是2个stacks(共有30个blocks)。
4. 集成
在M4竞赛的所有赢家,都融合了多个模型。这里作者也做了集成,而且用了180个模型(太疯狂了...),然后取预测中位数。模型的集成方面有:
● 不同的metrics。
● 不同训练长度。
● 不同随机初始化。
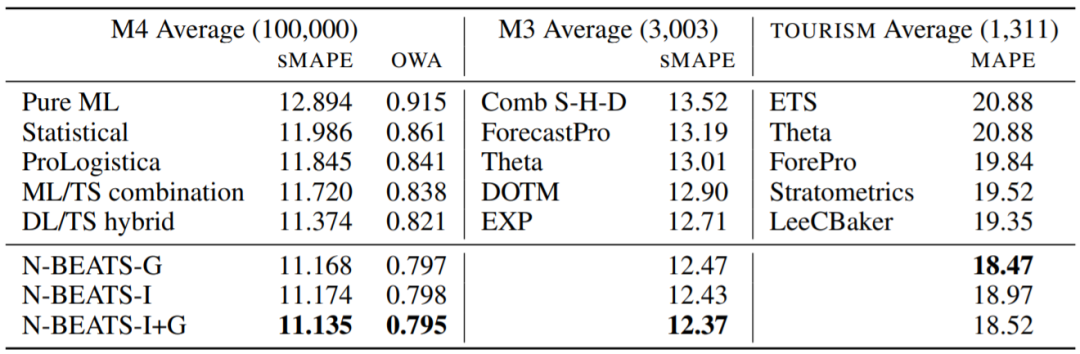
图3:在M4、M3和TOURISM测试集上的表现(数据集后面括号内的数字是指时序条数,N-BEATS后缀G为通用结构,I为可解释性结构)
在M4数据集上,使用GPU训练一个N-BEATS模型,耗时在30分钟-2小时之间。
5. 实验和结论
实验发现,数据粒度越小的数据集,预测不确定性更高,建议预测长度H不要太大。另外,对于模型的可解释性,透过下图便能发现:N-BEATS-I在trend stack和seasonal stack的数据明显比N-BEATS-G好。
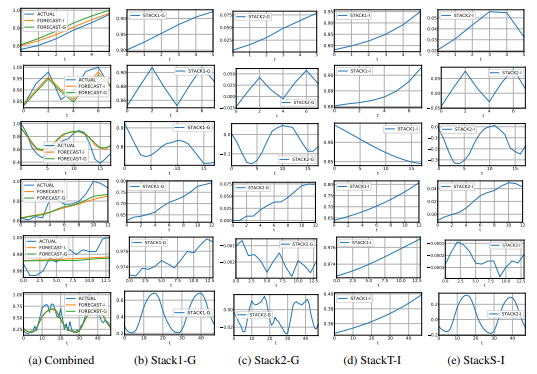
图4:通用结构和可解释性结构的输出对比
\theta是梯度更新后给basis function的,因此\theta是它的条件参数,除此之外g(\theta)内无其他参数需要更新,这便认为g(\theta)相对固定,所以block增加或者stack增加,能提高模型的泛化能力。但提高block/stack/fc layer数量给SMAPE带来的下降会趋于平缓。
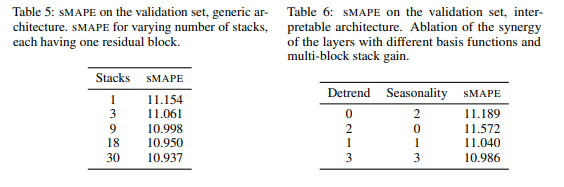
图5:不同stacks和blocks数量下的SMAPE
四、心得
阅读本文,个人心得如下:
● 模型结构中Block和双残差Stack设计很有意思,上一轮预测残差作为下一个block的输入。此外,为了增加模型可解释性,将序列分解加入到basis function当中,并有trend stack和seasonal stack分别输出结果,方便可视化解释序列预测结果。
● 但实验是在M4比赛后才做的,据社群朋友反馈,测试集已经公开了,而且用了180个模型融合才比M4第一名高了3%。真实业务场景下的效果还有待考究。
参考资料
[1] Oreshkin, B. N., Carpov, D., Chapados, N., & Bengio, Y. (2019). N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. *arXiv preprint arXiv:1905.10437*.
[2] 选择正确的错误度量标准:MAPE与sMAPE的优缺点 - deephub,文章:https://zhuanlan.zhihu.com/p/273208331
[3] Mean absolute scaled error - Wikipedia,百科:https://en.wikipedia.org/wiki/Mean_absolute_scaled_error
[4] M4 Competitors Guide,文档:https://usermanual.wiki/Pdf/M4CompetitorsGuide.719015056/view
[5] Benchmarks and Evaluation.R - M4-methods,代码:https://github.com/Mcompetitions/M4-methods/blob/master/Benchmarks%20and%20Evaluation.R
[6] N-BEATS: NEURAL BASIS EXPANSION ANALYSIS FOR INTERPRETABLE TIME SERIES FORECASTING - Keshav G,博文:https://kshavg.medium.com/n-beats-neural-basis-expansion-analysis-for-interpretable-time-series-forecasting-91e94c830393
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









