






摘要
尽管视觉-语言-行动(VLA)模型在多种机器人任务上取得了进展,但它们存在关键问题,例如由于依赖于仅从成功演示中进行行为克隆,导致对未见任务的泛化能力较差。此外,它们通常会针对不同设置下专家收集的演示进行微调,从而引入分布偏差,限制了它们对多样化操作目标(如效率、安全性和任务完成)的适应性。为了弥合这一差距,我们引入了GRAPE:通过偏好对齐泛化机器人策略。具体而言,GRAPE在轨迹层面将VLA对齐,并从成功和失败的试验中隐式建模奖励,以增强对多样化任务的泛化能力。此外,GRAPE 将复杂的作任务分解为独立的阶段,并通过自定义的时空约束自动指导偏好建模,其中包含大型视觉语言模型提出的关键点。值得注意的是,这些约束是灵活的,可以根据不同的目标(如安全性、效率或任务成功)进行定制。我们在真实世界和模拟环境中对GRAPE进行了多样化任务的评估。实验结果表明,GRAPE提升了最先进的VLA模型的性能,在领域内和未见操作任务上的成功率分别提高了51.79%和58.20%。此外,GRAPE可以与各种目标(如安全性和效率)对齐,分别将碰撞率降低了37.44%,将 rollout 步长降低了11.15%。
引言
1. 引言
最近,视觉 - 语言 - 行动(VLA)模型迅速发展,简化了一般机器人操作任务,在受控环境变化下的一系列任务中展现出了令人印象深刻的能力(Black 等人,2024(π0: A vision-language-action flow model for general robot control);Kim 等人,2024(OpenVLA: An open-source vision-language-action model);Team 等人,2024(Octo: An open-source generalist robot policy);Brohan 等人,2023(Rt-2: Vision-language-action models transfer web knowledge to robotic control))。然而,这些模型面临着几个关键挑战,比如在新环境、物体、任务和语义情境中的泛化能力较差(Kim 等人,2024(OpenVLA: An open-source vision-language-action model))。造成这一限制的一个重要因素是它们依赖于监督微调(SFT),在这种方法中,VLA 模型只是通过行为克隆模仿成功轨迹中的动作,而没有对任务目标或潜在的失败模式形成全面理解(Kumar 等人,2021(Should I run offline reinforcement learning or behavioral cloning?))。虽然近端策略优化(PPO)等强化学习(RL)算法(Schulman 等人,2017(Proximal policy optimization algorithms))已被证明在提高其泛化能力方面很有前景(Zhai 等人,2024(Fine-tuning large vision-language models as decision-making agents via reinforcement learning)),但收集足够的在线轨迹以及明确定义奖励的成本过高,使得它们在训练 VLA 模型时不切实际(Team 等人,2024(Octo: An open-source generalist robot policy))。
此外,仅训练 VLA 模型来复制专家行为往往会导致行为崩溃 behavior collapse(Kumar 等人,2024(Training language models to self-correct via reinforcement learning)),规划出的轨迹通常不是最优的(Kim 等人,2024(OpenVLA: An open-source vision-language-action model))。这是因为 SFT 数据集通常是未经整理的,由从专家那里收集的离线演示组成,这些演示隐含地包含了不同的价值观(例如任务完成度、安全性和成本效益),但在数据中并没有明确界定(O’Neill 等人,2023(Open x-embodiment: Robotic learning datasets and rt-x models);Walke 等人,2023(Bridgedata v2: A dataset for robot learning at scale))。通过 SFT 简单地模仿这些行为可能会使模型产生混淆,导致次优轨迹偏离演示的实际目标。一些方法试图通过明确定义一组目标并分层解决它们来应对这一挑战(Huang 等人,2024(Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation))。然而,这种方法会带来额外的推理开销,并且缺乏可扩展性(Li 等人,2024b(HAMSTER: Hierarchical action models for open-world robot manipulation))。
为了解决这些问题,我们提出了 GRAPE(通过偏好对齐泛化机器人策略),以减轻使用 RL 目标训练 VLA 模型的高昂成本,同时为适应定制的操作目标提供灵活性。如图 2 所示,GRAPE 引入了轨迹级偏好优化(TPO),通过从成功和失败的试验中隐式地建模奖励,在轨迹层面上对齐 VLA 策略,提高了对各种任务的泛化能力。为了进一步减轻轨迹排序的难度,并为任意对齐目标提供偏好,GRAPE 提议将复杂的操作任务分解为多个独立阶段,并采用大型视觉模型为每个阶段提出关键点,每个关键点都与一个时空约束相关联。值得注意的是,这些约束是灵活的,可以根据不同的操作目标(如任务完成度、机器人交互安全性和成本效益)进行定制,以使模型与之对齐。我们在广泛的真实世界任务和两个模拟环境中对 GRAPE 进行了评估。实验结果表明,GRAPE 优于最先进的 VLA 模型,在域内和未见操作任务上的成功率分别提高了 51.79% 和 58.20%。此外,GRAPE 可以与诸如安全性和效率等多种目标对齐,分别将碰撞率降低 37.44%,将轨迹步长缩短 11.15%。
2. 通过偏好对齐泛化机器人策略
2.1. 预备知识
在推理过程中,VLA 通常以任务指令q进行初始化,在每个时间步t,它接收环境观察ot(通常是一幅图像)并输出一个动作at ,我们可以将由θ参数化的 VLA 的动作策略表示为πθ(ai∣(oi,q))。为了完成任务,VLA 与环境进行迭代交互,并获得长度为T的轨迹![]() 。通常,VLA 通过 SFT 进行微调以模仿专家行为:
。通常,VLA 通过 SFT 进行微调以模仿专家行为:
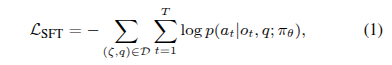
其中![]() 表示包含N个专家轨迹的训练集。具体来说,
表示包含N个专家轨迹的训练集。具体来说,![]() 强制 VLA 记住从分布
强制 VLA 记住从分布![]() 中采样的每个观察所对应的动作,导致对新任务设置的泛化能力较差。值得注意的是,虽然我们遵循 O’Neill 等人(2023(Open x-embodiment: Robotic learning datasets and rt-x models))和 Brohan 等人(2023(Rt-2: Vision-language-action models transfer web knowledge to robotic control)),并基于马尔可夫决策过程(MDP)假设(Sutton,2018(Reinforcement learning: An introduction))考虑基于步骤的策略 step-wise policy,但我们的方法可以很容易地适应非 MDP 情况(通常将过去的交互历史,如视频或一系列图像作为状态(Cheang 等人,2024(GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation)))和扩散策略(一次生成多个未来步骤(Team 等人,2024(Octo: An open-source generalist robot policy)))。
中采样的每个观察所对应的动作,导致对新任务设置的泛化能力较差。值得注意的是,虽然我们遵循 O’Neill 等人(2023(Open x-embodiment: Robotic learning datasets and rt-x models))和 Brohan 等人(2023(Rt-2: Vision-language-action models transfer web knowledge to robotic control)),并基于马尔可夫决策过程(MDP)假设(Sutton,2018(Reinforcement learning: An introduction))考虑基于步骤的策略 step-wise policy,但我们的方法可以很容易地适应非 MDP 情况(通常将过去的交互历史,如视频或一系列图像作为状态(Cheang 等人,2024(GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation)))和扩散策略(一次生成多个未来步骤(Team 等人,2024(Octo: An open-source generalist robot policy)))。
2.2. TPO:轨迹偏好优化
为了提高泛化能力,我们遵循Schulman等(2017)Proximal Policy Optimization Algorithms;Bai等(2022),并通过RL目标进一步微调VLA策略。设rϕ表示由ϕ参数化的奖励函数,我们有 ![]()
其中β控制与通过SFT在等式(1)中训练的参考策略的偏差,
![]() 是在指令q下策略π生成整个轨迹ζ的可能性。然后,我们遵循Rafailov等(2024),并从排名靠前的轨迹集中推导出轨迹奖励r(ζ)的分析重参数化:
是在指令q下策略π生成整个轨迹ζ的可能性。然后,我们遵循Rafailov等(2024),并从排名靠前的轨迹集中推导出轨迹奖励r(ζ)的分析重参数化:
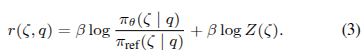
类似于Rafailov等(2024),我们采用Bradley-Terry(BT)(Bradley & Terry,1952)模型,并从排名靠前的轨迹集中建模rϕ。具体而言,设![]() 分别表示从相同初始状态开始的选定轨迹和被拒绝轨迹,我们可以将轨迹奖励建模目标公式化为:
分别表示从相同初始状态开始的选定轨迹和被拒绝轨迹,我们可以将轨迹奖励建模目标公式化为:
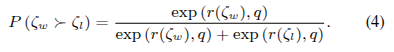
然后,我们遵循Rafailov等(2024),将等式(3)代入等式(4),并获得与等式(2)等价的轨迹偏好优化(TPO)损失LTPO:
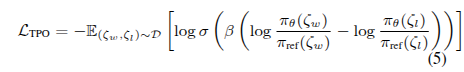
其中我们可以进一步从MDP中分解轨迹ζ的可能性,并将其分解为各个状态-动作对,即![]() ,并进一步得到
,并进一步得到
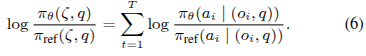
然后,我们将等式(6)代入等式(5),以获得以逐步状态-动作对表示的TPO损失LTPO。我们的TPO损失等式(6)具有以下优势:
(1)它在轨迹层面将策略πθ全局对齐到人类偏好,同时仅使用VLA收集的逐步rollout;
(2)它通过将梯度反向传播到轨迹沿线的所有状态-动作对,稳定策略并将其引导至最终目标;
(3)它通过从成功和失败的轨迹中学习,显著增强泛化能力。尽管Finn等(2016)Guided Cost Learning: Deep Inverse Optimal Control via Policy Optimization指出,扩大采样轨迹的规模可以减少奖励建模中的偏差,但这也增加了训练成本。因此,尽管我们的方法可以轻松扩展,我们仍然保持讨论为二元情况,即仅存在一个选定/被拒绝的轨迹。
2.3. 引导成本偏好生成
虽然给定 TPO 目标公式(5),我们可以使策略朝着通过相应偏好排序的轨迹定义的任意目标对齐,但这需要人类专业知识和冗长的手动注释,成本较高。因此,为了更好地扩展针对任意对齐目标(例如任务完成度、安全性、效率)的偏好合成,我们提出了引导成本偏好生成(GCPG),以自动整理整合不同对齐目标的偏好。
2.3.1. 多阶段时间关键点约束
基于 Huang 等人(2024(Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation))的见解,我们通过将轨迹分解为时间阶段并分配成本来量化每个阶段的性能,从而解决为复杂操作任务指定精确轨迹偏好的复杂性问题。然后,我们聚合这些阶段特定的成本,以获得对每个轨迹的整体评估。具体来说,我们采用基于 VLM 的阶段分解器MD(附录 A 中有详细说明),将轨迹划分为S个连续阶段,公式表示为:
![]()
其中ζi表示轨迹ζ的第i个阶段。
在获得阶段分解后,我们进一步使用视觉 - 语言模型(例如 DINOv2(Oquab 等人,2023(DINOv2: Learning robust visual features without supervision)))来识别作为每个阶段参考指标的关键点。然后,我们促使强大的大语言模型(LLM)(Achiam 等人,2023(GPT-4 technical report))为每个阶段提出与对齐目标相对应的成本函数(示例见附录 E.2),成本越低表示对目标的符合程度越好。具体来说,阶段Si的成本![]() 使用其相应的关键点κsi计算。
使用其相应的关键点κsi计算。
然后,为了聚合整个轨迹的成本,我们不是线性地对每个阶段进行求和,而是应用指数衰减来捕捉每个时间阶段的因果依赖关系(例如,如果一个轨迹在前面的阶段产生了高成本,那么预计它在后续阶段的表现也不会好),定义为外部奖励:
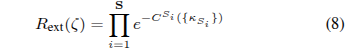
公式(8)聚合了每个阶段的单个成本和子目标,以解决维度诅咒问题,并有效地遵循定制的对齐方式。
2.3.2. 引导成本偏好生成
为了进一步提高偏好合成的稳定性和最优性,我们从自奖励(Zhou 等人,2024b(Calibrated self-rewarding vision language models))中获得灵感,认为一个更优的轨迹应该同时得到外部评判(如公式(8))和模型自身的确认。因此,我们结合两个额外的奖励,得到 GCPG 奖励:
![]()
其中Rself(ζ)是由π提供的自我评估分数,等于生成轨迹ς的对数似然:
![]()
Isuccess(ζ)是一个二元指示函数,表示轨迹ζ是否成功完成任务:
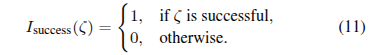
λ是调整每个奖励重要性的权重参数。直观地说,公式(10)可以看作是公式(11)提供的稀疏信号的密集近似,进一步由公式(8)校准,以获得对轨迹的整体评估,该评估考虑了其最优性以及与通过公式(8)中的外部奖励指定的定制目标的对齐程度。
2.4. 迭代偏好优化
在生成偏好之后,我们接着讨论迭代偏好优化策略。受策略梯度强化学习(on-policy RL)实践(Schulman 等人,2017(Proximal policy optimization algorithms))的启发,这种方法通常比离策略训练产生更优的策略。我们通过 TPO 使用在线收集的轨迹对 SFT VLA 模型进行迭代微调。例如,在第k次迭代中,我们(1)首先对各种任务采样大量轨迹,得到![]() ;(2)然后使用公式(9)计算每个轨迹的成本,并根据每个任务相应地对这些轨迹进行排序;(3)我们为每个任务将排名前m和后m的轨迹配对,得到
;(2)然后使用公式(9)计算每个轨迹的成本,并根据每个任务相应地对这些轨迹进行排序;(3)我们为每个任务将排名前m和后m的轨迹配对,得到个选择 - 拒绝轨迹对;(4)然后通过公式(5)使用 TPO 对相同的采样策略进行微调,得到更新后的策略。我们重复这个过程K次,得到与目标目标对齐的最终模型。我们在算法 1 中详细说明了 GRAPE 迭代偏好优化过程。

3. 实验
在本节中,我们在真实和模拟环境中评估GRAPE的性能,回答以下四个关键问题:
(1)与基于SFT的基线模型相比,GRAPE是否提升了VLA模型的性能?
(2)引导成本偏好选择和迭代偏好优化在增强模型性能方面有多有效?
(3)每个奖励成分对整体模型性能的贡献是什么?
(4)GRAPE能否支持与不同对齐目标的灵活对齐?
3.1. 实验设置
实现细节。我们采用OpenVLA(Kim等,2024)作为骨干模型,使用LoRA微调和AdamW优化器进行监督和偏好微调。在监督微调阶段,我们使用4×10−5的学习率和16的批量大小。对于偏好微调,我们应用2×10−5的学习率和相同的批量大小。有关训练过程和数据集的更多详细信息,请参阅附录A和B。 基线模型。我们首先将GRAPE与两个在机器人控制任务中表现出色的领先机器人学习模型进行比较。第一个模型,Octo(Team等,2024)是一个基于大型Transformer的策略模型。第二个模型,OpenVLA(Kim等,2024)是一个7B VLA模型。这两个模型都使用从相应环境中采样的相同数据集进行了监督微调。我们分别将这些监督微调模型表示为Octo-SFT和OpenVLA-SFT。此外,我们将GRAPE(利用轨迹偏好优化)与原始逐步直接偏好优化进行比较,后者直接针对每个步骤定义的偏好进行训练,表示为OpenVLA-DPO。
3.2. 在模拟环境中的评估
评估设置。
按照Kim等(2024)的方法,我们在两个机器人模拟环境:Simpler-Env(Li等,2024a)和LIBERO(Liu等,2023)中评估GRAPE的性能。在Simpler-Env中,我们评估模型的领域内性能以及在三个方面(主体、物理和语义)的泛化能力:主体(泛化到未见物体)、物理(泛化到未见物体大小/形状)和语义(泛化到未见指令)。在LIBERO中,我们在四个任务上测试我们的模型:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-Long。所有任务都是领域内任务。有关实验设置的更多详细信息,请参阅附录C.2。 结果。我们使用Simpler-Env和LIBERO中所有任务的成功率作为主要评估指标,同时我们还记录了Simpler-Env中的抓取率。图3和图4分别报告了Simpler-Env和LIBERO的结果。根据结果,GRAPE在Simpler-Env中平均比Octo-SFT和OpenVLA-SFT高出131.72%和46.10%,在LIBERO中平均高出8.53%和7.36%
结果:我们使用 Simpler-Env 和 LIBERO 中所有任务的成功率作为主要评估指标,同时记录 Simpler-Env 中的抓取率。Simpler-Env 和 LIBERO 的结果分别如图 3 和图 4 所示。
Figure 3: Comparison of GRAPE with OpenVLA and Octo fine-tuned on the same data on the Simpler-Env environment. We report the in-domain performance, which includes four tasks and three generalization evaluations (subject, physical, and semantic), where each incorporates multiple tasks.
Figure 4: Comparison of GRAPE with OpenVLA and Octo fine-tuned on the same data on the LIBERO environment. We report the performance on four types of LIBERO tasks.
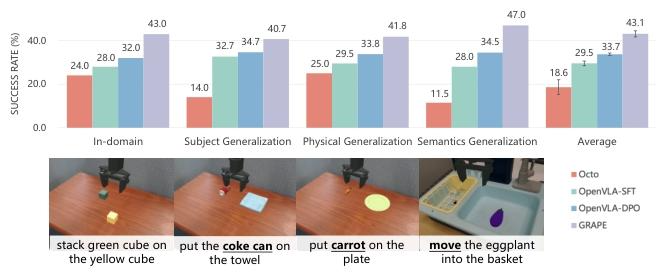
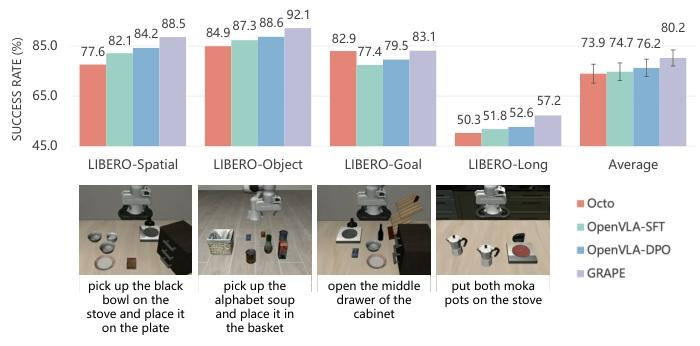
根据结果,GRAPE 在 Simpler-Env 中平均优于 Octo-SFT 和 OpenVLA-SFT 131.72% 和 46.10%,在 LIBERO 中平均优于它们 8.53% 和 7.36%。更多结果见附录 D。这一结果符合我们的预期,因为从偏好比较中学习增强了与轨迹完成度的对齐,从而提升了性能。此外,GRAPE 在显著提升域内性能的同时,还通过在轨迹层面上对齐任务完成度,增强了 VLA 策略在 OOD 任务上的泛化能力。此外,GRAPE 在两个环境中均优于 OpenVLA-DPO,平均提升 33.14%,证明了轨迹级偏好优化的有效性,因为它从全局轨迹层面的成功和失败中学习,避免了低层次步骤噪声的干扰。
3.3. 真实世界机器人环境评估
评估设置:我们在 30 个任务上进行了 300 次真实世界实验,以评估 GRAPE 的泛化能力。评估重点包括分布内评估和五种分布外泛化类型:视觉、主体、动作、语义和语言接地泛化。其中,视觉泛化评估适应新视觉环境的能力;主体泛化评估识别和处理陌生物体的能力;动作泛化衡量在不同动作上的表现;语义泛化评估对相似含义提示的响应;语言接地泛化衡量对空间方向的理解。实验设置的详细信息见附录 C.1,并在图 5 中说明。
Figure 5: Comparison of GRAPE with OpenVLA and Octo fine-tuned on the same data on the real-world environment. We report the in-domain performance, which includes four tasks and five generalization evaluations (visual, subject, action,semantic, and language grounding), where each incorporates multiple tasks. We also report the average performance across all tasks

结果:在真实世界实验中,GRAPE 在各种任务上显著优于其他模型。值得注意的是,在域内任务中,GRAPE 的成功率达到 67.5%,比 OpenVLA-DPO 的 50%、OpenVLA-SFT 的 45% 和 Octo-SFT 的 20% 分别提高了 17.5%。此外,在视觉泛化任务中,GRAPE 表现出更高的适应性,成功率为 56%。在更具挑战性的动作泛化任务中,尽管 OpenVLA-SFT 表现平平,GRAPE 仍优于 OpenVLA-SFT,表明其在理解各种动作和根据语言执行命令方面的潜力。考虑所有类别的任务,GRAPE 的总平均成功率为 50.3%,比 OpenVLA-DPO 的 39.3%、OpenVLA-SFT 的 32.3% 和 Octo-SFT 的 5.7% 分别提高了 11%。这一性能突出了(1)GRAPE 在处理复杂多变任务环境中的有效性和适应性;(2)验证了与 OpenVLA-DPO 相比,轨迹级偏好优化在从全局成功和失败模式中学习的有效性
3.4. 奖励模型消融研究
在本节中,我们进行消融研究,分析公式(9)中每个奖励组件对最终性能的贡献:外部目标对齐奖励![]() 、自我评估奖励\(
、自我评估奖励\(\)和成功指标\(
\)。此外,我们还进行了单独的消融研究,强调使用完整奖励分数进行偏好选择的重要性,并将其与仅基于成功随机选择一个成功轨迹作为偏好轨迹和一个失败轨迹作为拒绝轨迹的方法进行比较。Simpler-Env 环境中的结果如表 1 所示。
表1:奖励分数的消融研究。此处,“基于\(
\)的随机选择”是指随机选择一条成功的轨迹作为被选轨迹,以及一条失败的轨迹作为被拒绝轨迹,
是由生成轨迹
的对数似然所提供的自我评估分数,
表示公式(8)中定义的目标对齐的多阶段奖励,
是一个二元指示函数,用于指示轨迹
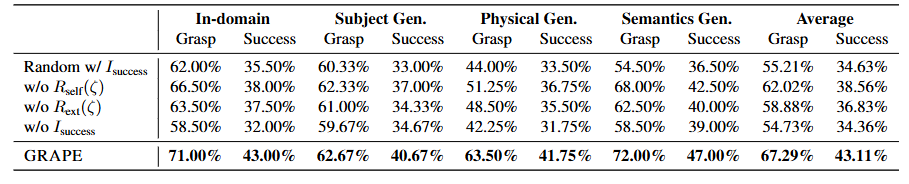
结果表明:(1)使用完整奖励分数(公式(9))进行偏好排序显著优于仅基于成功的随机选择;(2)所有奖励组件均对模型性能有贡献。这些发现与我们的预期一致。具体而言,通过鼓励选择生成概率更高的轨迹来增强 GRAPE 的鲁棒性。同时,
![]() 引导模型学习特定行为,如安全性和效率。最后,
引导模型学习特定行为,如安全性和效率。最后,作为关键指标,引导模型优先考虑成功轨迹。
3.5. 迭代偏好优化分析
在本节中,我们分析迭代偏好优化的性能。我们在 Simpler-Env 环境中进行实验,并根据训练迭代次数报告结果,如图 6 所示。
Figure 6: Performance of GRAPE during iterative preference optimization via TPO. We demonstrate the average success rate for each iteration across in-domain tasks and three types of generation tasks (subject, physical, semantics).
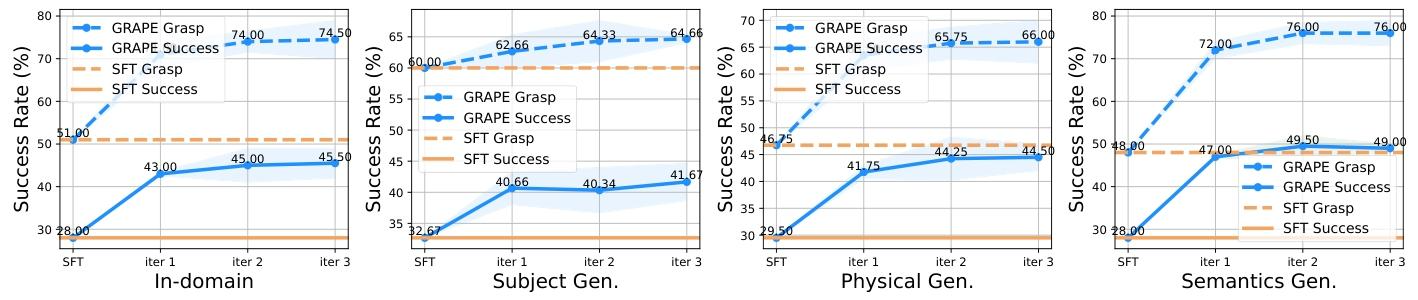
这里,SFT 表示偏好优化前的监督微调 OpenVLA 模型。在实验中,GRAPE 在域内性能、主体泛化、物理泛化和语义泛化方面分别取得了 17.5%、9.0%、15.0% 和 21.0% 的提升。研究结果表明,GRAPE 在迭代过程中逐步提升模型性能,展示了其提升生成偏好数据质量并实现更好泛化的能力。值得注意的是,随着模型接近收敛,改进幅度逐渐减小,这与我们的预期一致。
3.6. 不同对齐目标分析
3.6.1. 定量分析
在证明 GRAPE 在提高 VLA 模型泛化能力(通过成功率衡量)的有效性后,我们进一步研究其与灵活目标(如效率和安全性)对齐的潜力。回顾公式(8),我们发现调整阈值参数可以通过影响轨迹偏好选择来引导模型优先考虑特定目标。在本研究中,我们重点关注两个新的对齐目标:安全性和效率。安全性旨在最小化机器人与物体之间的碰撞,而效率旨在减少机器人完成任务所需的平均步数。为了实现这些目标,我们设置较低的碰撞成本阈值以强调安全性,设置较低的路径成本阈值以优先考虑效率。然后将这些修改后的设置应用于原始的真实世界和模拟评估。我们训练模型以对齐安全性和效率目标,将这些模型分别称为 GRAPE-Safety 和 GRAPE-Efficiency(实验设置的详细信息见附录 C.2)。
结果如表 2 所示,我们使用碰撞率、步长和成功率分别评估安全性、效率和泛化能力。
Table 2: Results with respect to different objectives. GRAPE-Safety, GRAPE-Efficiency, GRAPE-TC are models trained with safety, efficiency, task completion objectives, respectively. Here, we use collision rate (CR), step length (SL), success rate (SR) to evaluate the safety, efficiency and task completion capabilities.
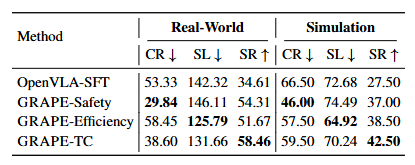
根据表 2,GRAPE-Safety 和 GRAPE-Efficiency 在碰撞率和步长方面分别表现更优,同时与 OpenVLA-SFT 相比保持了相当的成功率。结果表明,GRAPE 可以通过相应调整多阶段成本函数,轻松适应灵活的对齐目标,如安全性和效率,同时任务成功率的下降最小。
3.6.2. 案例研究
我们在图 7 中进一步展示了一个案例研究,以分析 GRAPE 对不同对齐目标的适应性。
图7:通过安全目标对齐的GRAPE(GRAPE-Safety)与通过任务完成目标对齐的GRAPE(GRAPE-TC)以及OpenVLA-SFT的对比。具体而言,我们在一项安全关键任务中评估它们的性能,任务指令为:拿起白色盒子并放入黑色锅中。
具体而言,我们考虑一个安全关键的拾取任务,其中在物体和目标之间放置了一个障碍物。具体来说,OpenVLA-SFT 在没有偏好对齐的情况下无法完成任务。然而,我们可以看到,虽然对齐任务完成度的 GRAPE(图 7 第二行)能够有效拾取并放置物体,但由于策略被对齐以积极提升任务成功率而未明确解决安全问题,它也会与障碍物碰撞。相反,GRAPE-Safety 学会了在高效完成任务的同时避免与障碍物碰撞。表 2 和图 7 均表明,只需调整成本函数,GRAPE 就能有效适应不同的目标。更多案例和详细的安全评估任务见附录 E.1。
4. 相关工作
4.1. 视觉 - 语言 - 行动模型
先前的机器人学习工作(Huang 等人,2024(Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation);Li 等人,2024b(HAMSTER: Hierarchical action models for open-world robot manipulation);Chen 等人,2024c(Safe reinforcement learning via hierarchical adaptive chance-constraint safeguards);Mu 等人,2024a(RoboCodex: Multimodal code generation for robotic behavior synthesis);Huang 等人,2023(VoxPoser: Composable 3D value maps for robotic manipulation with language models);Liang 等人,2023a(Code as policies: Language model programs for embodied control);Mu 等人,2024b(EmbodiedGPT: Vision-language pre-training via embodied chain of thought))通常采用分层规划策略。例如,Code as Policies(Liang 等人,2023a(Code as policies: Language model programs for embodied control))和 EmbodiedGPT(Mu 等人,2024b(EmbodiedGPT: Vision-language pre-training via embodied chain of thought))使用 LLM 和 VLM 生成高层动作计划,然后依赖低层控制器生成局部轨迹。然而,此类模型低层技能有限,难以推广到日常任务。VLA 模型倾向于通过将 VLM 作为骨干并在模型内直接生成动作来扩展低层任务。它们通常通过两种主流方法实现动作规划:(1)离散化动作空间(Kim 等人,2024(OpenVLA: An open-source vision-language-action model);Brohan 等人,2023(Rt-2: Vision-language-action models transfer web knowledge to robotic control);2022(Rt-1: Robotics transformer for real-world control at scale)),如 OpenVLA(Kim 等人,2024(OpenVLA: An open-source vision-language-action model)),通过将动作截断为少量动作标记来保留自回归语言解码目标。然而,这会引入误差,导致一些方法(Black 等人,2024(π0: A vision-language-action flow model for general robot control))采用更新的结构(Zhou 等人,2024a(TransFusion: Predict the next token and diffuse images with one multi-modal model)),集成扩散头进行动作预测,避免离散化。(2)扩散模型(Chi 等人,2023(Diffusion policy: Visuomotor policy learning via action diffusion);Xian 等人,2023(ChainedDiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation);Janner 等人,2022(Planning with diffusion for flexible behavior synthesis);Liang 等人,2023b(AdaptDiffuser: Diffusion models as adaptive self-evolving planners);Ajay 等人,2023(Is conditional generative modeling all you need for decision making?)),如 Diffusion Policy(Chi 等人,2023(Diffusion policy: Visuomotor policy learning via action diffusion)),作为动作头,通过迭代去噪生成未来动作序列,而非逐步生成动作。
尽管这些模型结构各异,但它们始终通过行为克隆在成功的轨迹上进行监督训练,这使得它们难以推广到未见的操作任务。然而,我们的 GRAPE 首先通过试错在轨迹层面上对齐 VLA 策略,有效提升了泛化能力和定制能力。
4.2. 强化学习与偏好优化
强化学习(RL)(Christiano 等人,2017(Deep reinforcement learning from human preferences);Ziegler 等人,2019(Fine-tuning language models from human preferences);Schulman 等人,2017(Proximal policy optimization algorithms))在基础模型的后训练中发挥着关键作用(Dubey 等人,2024(The LLaMA 3 herd of models);Achiam 等人,2023(GPT-4 technical report);Chen 等人,2024d(AutoPRM: Automating procedural supervision for multi-step reasoning via controllable question decomposition);a(MjBench: Is your multimodal reward model really a good judge for text-to-image generation?);Fan 等人,2024(Reinforcement learning for fine-tuning text-to-image diffusion models);Yang 等人,2024(CogVideoX: Text-to-video diffusion models with an expert transformer);Chen 等人,2024b(SafeWatch: An efficient safety-policy following video guardrail model with transparent explanations);Wang 等人,2025(Beyond reward hacking: Causal rewards for large language model alignment)),已被广泛用于使预训练基础模型符合通过偏好数据嵌入的人类价值观。同时,RL 在训练机器人任务策略方面也取得了巨大成功(Chen 等人,2024c(Safe reinforcement learning via hierarchical adaptive chance-constraint safeguards);Wang 等人,2024b(EscIRL: Evolving self-contrastive IRL for trajectory prediction in autonomous driving);Chen 等人,2021(Decision Transformer: Reinforcement learning via sequence modeling);2022(Towards human-level bimanual dexterous manipulation with reinforcement learning);Zhu 等人,2019(Dexterous manipulation with deep reinforcement learning: Efficient, general, and low-cost);Wu 等人,2024(UniDexFPM: Universal dexterous functional pregrasp manipulation via diffusion policy))。尽管通过 RL 对 VLA 进行后对齐在直觉上是有益的,但此前很少有工作报道这种成功,主要原因是:(1)操作目标通常多样且复杂,使得奖励难以解析定义(Finn 等人,2016(Guided cost learning: Deep inverse optimal control via policy optimization));(2)虽然可以从人类偏好中建模奖励,但在机器人操作任务中标注此类偏好通常耗时(Walke 等人,2023(Bridgedata v2: A dataset for robot learning at scale));(3)奖励的不完美数值微分通常导致 PPO(Schulman 等人,2017(Proximal policy optimization algorithms))等 RL 算法崩溃(Busoniu 等人,2018(Reinforcement learning for control: Performance, stability, and deep approximators))。然而,最近的多项工作(Rafailov 等人,2024(Direct preference optimization: Your language model is secretly a reward model);Wang 等人,2024a(Preference optimization with multi-sample comparisons))成功通过 RL 对齐策略,而无需显式的奖励建模。受此启发,GRAPE 通过对比轨迹来对齐策略,避免了奖励建模中的问题。此外,我们引入了一个自动偏好合成管道,能够轻松扩展到多样化的操作任务,并适应不同的对齐目标。
5. 结论
在这项工作中,我们解决了视觉 - 语言 - 行动(VLA)模型面临的关键挑战,包括有限的泛化能力和对多样化操作目标的适应性。我们提出了 GRAPE,它在轨迹层面上对齐 VLA 策略。GRAPE 通过从成功和失败的试验中学习,增强了泛化能力,并通过定制的时空约束提供了与安全性、效率和任务成功等目标对齐的灵活性。实验结果表明,GRAPE 显著提高了域内和未见任务的成功率,同时支持不同目标的灵活对齐。此外,我们证明了 GRAPE 能够有效降低碰撞率和平均步长,实现与定制目标的对齐。
A. Additional Description of GRAPE and Hyperparameter Settings
定制化成本生成
在真实世界实验中,我们首先将包含提示词和初始状态的图文对输入至视觉-语言模型(VLM)Hamster(Li等人,2024b(HAMSTER: Hierarchical action models for open-world robot manipulation))。利用Hamster生成的阶段信息和阶段点,我们对收集的轨迹进行分割,从而更精确地分析复杂任务序列,对每个阶段给予细致关注。我们采用Grounded-SAM(Ravi等人,2024(Grounded-SAM: Segment anything meets grounded language models))或结合SAM(Ravi等人,2024(Segment Anything))与DinoV2(Oquab等人,2024(DINOv2: Learning robust visual features without supervision))的方法从图像中提取关键点信息。这些关键点结合我们自行收集的轨迹数据,使我们能够基于Hamster模型生成的阶段信息优化任务的执行步骤和路径规划。例如,对于简单的拾取放置任务,我们可将其分解为多个显式阶段:抓取葡萄、将葡萄移至盘子上方、将葡萄放置在盘子上。为生成各阶段的详细操作信息和成本函数,我们使用定制化提示词驱动的GPT-4o(Achiam等人,2023(GPT-4 technical report))。这种方法使阶段规划更精确高效,能够满足特定任务需求与约束。此外,我们通过融入多种任务特定约束增强方法:碰撞约束:确保机器人避开障碍物;路径约束:优化机器人运动路径的效率与安全性。通过该策略,我们在任务规划中实现了更高的灵活性和针对性,能更好适应不同任务场景。
迭代偏好优化
对于迭代偏好优化,我们首先利用微调后的VLA模型进行在线数据采样。对于每个任务,我们采样\(N_{t}\)条轨迹以方便后续筛选。为简化实验设置,我们将每个任务的\(N_{t}\)设为5,实践表明该值效果良好。
采样完成后,每条轨迹都会使用公式(9)中定义的GCPG奖励进行自动标记。根据在初步实验中观察到的\(R_{self}\)、\(R_{ext}\)和\(I_{success}\)的分布情况,我们将\(\lambda_{1}\)设为\(0.01\),\(\lambda_{2}\)设为\(0.01\),\(\lambda_{3}\)设为\(2\)。这些取值确保了\(R_{self}\)、\(R_{ext}\)和\(I_{success}\)对最终奖励值的贡献程度相当。后续实验验证了这些参数选择的合理性。利用分配给每条轨迹的GCPG奖励,对于每个任务,我们将奖励最高的轨迹确定为\(yaw\),将奖励最低的轨迹确定为\(y_{l}\)(推测应该是\(\zeta_{l}\) )。这一选择过程使得我们能够构建用于TPO训练的TPO数据集\(D_{traj}\)。
对于轨迹级偏好优化(TPO)的训练过程,我们采用了低秩适应(LoRA)技术(Hu等人,2022(Lora: Low-rank adaptation of large language models))以及AdamW优化器,将学习率设置为\(2×10^{-5}\),批量大小设置为16。在将模型用于迭代在线采样之前,先对其进行一个 epoch(轮次)的训练。在迭代在线采样过程中,实验设置与上述描述保持一致。
B. Detail Experiment Datasets
在本节中,我们将介绍为监督微调(称为SFT数据集)和偏好对齐(称为TPO数据集)所收集的数据集。
B.1. Real-World Dataset
监督微调(SFT)数据集。
在我们的真实世界机器人实验中,我们使用由一个弗兰克(Franka)机械臂和一个罗博蒂克(Robotiq)夹爪组成的机器人平台来收集数据。为了确保数据收集和评估的一致性,所有操作都在相同的实验环境中进行。
在数据收集过程中,我们收集了一个包含220个实例的数据集,这些实例是涉及香蕉、玉米、牛奶和盐等常见物品的抓取和放置任务。此外,我们还收集了50个涉及按下不同颜色按钮任务实例的数据。由于用于按钮按下任务的物体数量有限,我们在测试阶段引入了背景干扰和干扰物体,以创造一些未见过的场景。
为了进一步增强OpenVLA处理不同动作的能力,我们还收集了50个推倒任务实例的数据。这些多样化的任务数据集有助于提高模型在处理不同类型动作时的泛化能力。
轨迹级偏好优化(TPO)数据集。
在真实世界实验中,我们使用了一个通过OpenVLA在真实世界监督微调(SFT)数据集上进行微调的模型来进行轨迹采样。每个任务执行了五次。在TPO数据集中,我们对15种不同的任务进行了实验,其中包括10个抓取和放置任务、3个按钮按压任务以及2个推倒任务,总共积累了75条数据记录。经过筛选过程后,我们得到了一个由30条轨迹组成的偏好数据集。
B.2. Simulation Datasets
监督微调(SFT)数据集:对于简易环境(Simpler-Env),SFT数据集包含100条轨迹,大约有2900次状态转换。这些轨迹是按照Ye等人(2024(此处需你补充具体文章标题))所述的方法,使用Octo从简易环境中生成的。对于LIBERO环境,值得注意的是,我们既没有收集新数据,也没有对OpenVLA模型进行微调。相反,我们直接使用了由OpenVLA团队提供的OpenVLA-SFT模型,这大大简化了流程。
轨迹级偏好优化(TPO)数据集。在简易环境(Simpler-Env)的情况下,使用OpenVLA-SFT模型为每个任务采样轨迹,每个任务进行五次尝试。这一过程产生了一个由80条轨迹组成的TPO数据集。对于LIBERO环境,使用OpenVLA-SFT模型(每个任务对应一个模型)对LIBERO中的四个任务进行数据采样。对于每个任务,为每个子任务采样五条轨迹,从而得到一个总共由20条轨迹组成的TPO数据集。
C. Detailed Experiment Settings and Additional Result
C.1. Real-World
C.1.1. REAL-WORLD EXPERIMENT SETUP
在真实世界的实验中,我们使用了以高精度和灵活性著称的弗兰克(Franka)机械臂。然而,我们发现原装的弗兰克夹爪存在一个问题,其长度不够,这限制了我们处理某些任务的能力,导致任务完成效率低下且失败率很高。为了解决这个问题,我们决定将原装的弗兰克夹爪更换为罗博蒂克(Robotiq)夹爪。罗博蒂克夹爪不仅长度更长,而且能提供更强的抓握力和更高的灵活性,这极大地提高了任务执行的效率和成功率。
本实验的目的是评估在GRAPE框架下OpenVLA的跨任务泛化能力,并将其性能与几个基线模型进行比较。考虑到大多数视觉语言动作(VLA)模型的零样本泛化性能普遍较差,我们使用从真实场景中收集的全面轨迹数据集\(D_{r}\)进行了监督微调,以构建一个经过微调的模型。基线模型的选择包括那些使用特定领域数据进行调整的模型,以及Octo模型、RVT-2模型和OpenVLA-SFT模型。
C.1.2. REAL-WORLD TASKS
如图5所示,我们针对几项任务在真实机器上进行了全面评估。这些任务涵盖了五种不同的泛化场景:视觉泛化、对象主体泛化、动作泛化、语义泛化以及语言基础关联。具体而言,对于每种泛化场景,我们设置了以下任务:

我们总共对30项不同的任务进行了实验,每项任务尝试十次,总计进行了300次操作。为了确保评估的公平性,在每次模型测试中,我们都让机器人保持相同的起始位置。此外,在训练所有模型时,我们统一了图像分辨率,并且在所有评估中使用了完全相同的初始物体位置。我们为每个任务设定了具体的成功标准。例如,在抓取放置任务中,成功抓取被定义为成功抓住目标物体。在按按钮和推倒任务中,成功抓取被定义为正确靠近并操作目标物体。整体任务的成功则被定义为物体被准确放置在目标位置、成功被推倒,或者目标按钮被成功按下。由于这些标准较为严格,一些模型在特定任务中很难取得成功。
C.2. Simulation Experiments
C.2.1. SIMPLER-ENV
我们在研究中采用Simpler-Env(Li等人,2024a)作为实验环境。SIMPLER(Li等人,2024a)全称为"真实机器人设置的模拟操作策略评估环境"(Simulated Manipulation Policy Evaluation for Real Robot Setups),是一组模拟环境的集合,旨在以紧密反映真实场景的方式评估机器人操作策略。通过利用模拟环境,SIMPLER有效替代了真实世界测试——后者往往成本高昂、耗时且难以复现。
简易环境(Simpler-Env)任务。在我们的论文中,我们使用了简易环境中来自威达(WidowX)机器人的四项领域内任务。我们还在简易环境中设计了三种泛化任务。以下是对这些任务的描述:

C.2.2. LIBERO
我们在研究中进一步采用了LIBERO(刘等人,2023)作为实验环境。LIBERO(机器人操作任务的终身学习基准测试,英文全称为LIfelong learning BEnchmark on RObot manipulation tasks)包含一组受人类活动启发的130个以语言为条件的机器人操作任务,这些任务被划分为四个不同的任务组。每个任务组旨在研究物体类型、物体的空间排列、任务目标或这些因素组合的分布变化。LIBERO的设计具有可扩展性,能够进行扩展,并且是专门为推动机器人操作终身学习领域的研究而定制的。
LIBERO任务 在我们的论文中,我们使用了来自LIBERO的四项领域内任务,这些任务如图4所示。以下是对这些任务的描述:

E. Case Study
E.1. Case Study of Real-World Generation Tasks
E.2. Case Study of Multi-stage Cost Functions
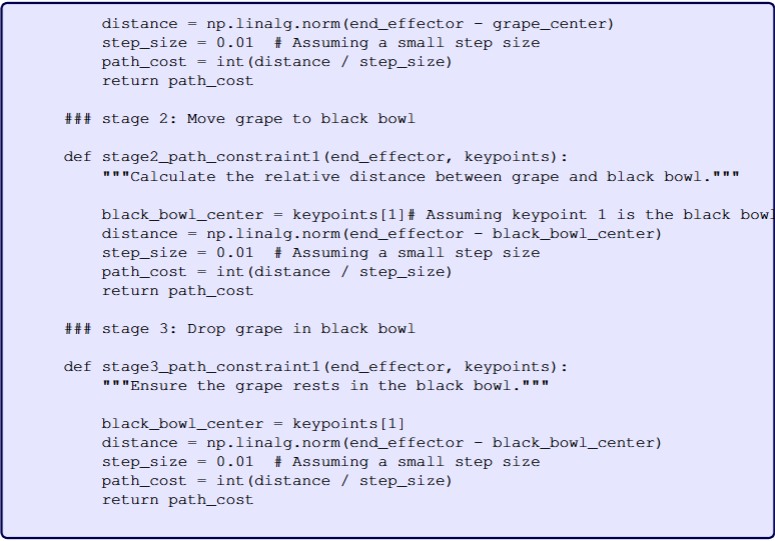
我们展示了一些案例研究,内容是使用我们所提出的流程针对不同的对齐目标生成的多阶段成本函数。
E.2.1. TASK COMPLETION

E.2.2. SAFETY


E.2.3. COST-EFFICIENCY





















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









