







论文:CVPR 2019
代码:tensorflow 1.
Google Drive 可以跑通
!pip uninstall tensorflow
!pip install tensorflow-gpu==1.15.0
!pip install munkres
!pip install 'h5py<3.0.0' -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install keras==2.3.1
!python run.py
网络模型

我们可以大致分为两个部分:用于生成潜在特征表示的双自编码器和用于分类的深度谱聚类。
双自编码器由一个编码器一个带噪声的解码器以及一个不带噪声的解码器组成。并且在编码器网络的学习过程中引入了互信息最大化,从而使网络能够获得更鲁棒的表示。
编码器
特征提取是聚类的重要步骤,一个良好的特征可以有效地提高聚类性能。然而,一个单一的重建损失并不能很好地保证潜在表示的质量。我们希望这些表示将帮助我们从输入中识别样本,这意味着它是从输入中提取的最独特的信息。互信息度量两个样本之间的基本相关性,可以有效地估计特征Z和输入X之间的相似性。
互信息的定义定义为: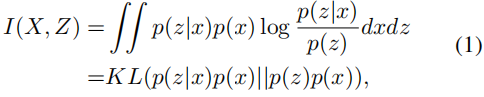
其中,
p
(
x
)
p(x)
p(x)是输入分布,
p
(
z
∣
x
)
p(z|x)
p(z∣x)是隐含表示分布,
p
(
z
)
p(z)
p(z)是隐含空间分布。
互信息希望尽可能大,如下:
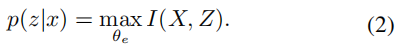
此外,学习到的潜在表示需要服从标准正态分布的先验分布,并通过KL散度进行衡量。这有助于使潜在空间更加规则化。先验分布p(z)与其先验分布q(z)之间的分布差异被定义为:

由于KL散度是无界的而且是不对称的,因此作者采用了JS散度替代,JS散度是利用互信息最大化:
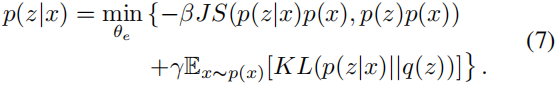
JS散度的变分估计被定义为:

负采样估计是采用一个分类器将真实的和噪声的样本分别开,从而估计真实样本的分布,通常用来解决上述公式(9)中的问题。 σ ( T ( x , z ) ) \sigma (T(x,z)) σ(T(x,z))是一个分类器,其中 x x x及其潜在的表示 z z z构成正样本对。然后根据 x x x从噪声批次中随机选择 z t z_t zt构建负样本对。上述公式9表示的是全局的互信息。
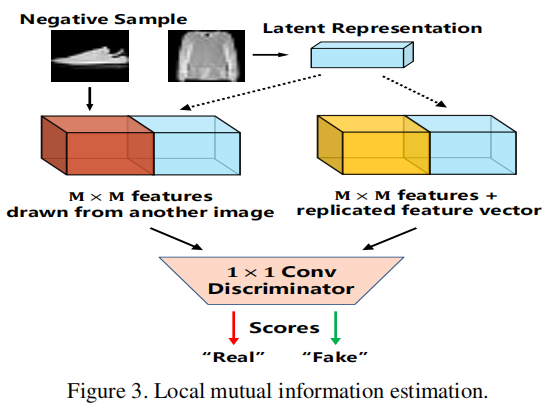
此外,我们从卷积网络的中间层提取特征图,并构建特征图与潜在表示之间的关系,即局部互信息。估计方法与全局互信息起着相同的作用。中间层特征与潜在表示组合以获得新的特征图。然后,一个1×1卷积被视为局部互信息的估计网络,如图3所示。负样本的选择方法与全局互信息估计相同。因此,需要优化的目标函数可以定义为:

其中,
h
h
h和
w
w
w表示特征图的高度和宽度。
C
i
j
C_{ij}
Cij表示中间特征映射在坐标
(
i
,
j
)
(i,j)
(i,j)处的特征向量,
q
(
z
)
q(z)
q(z)为标准正态分布。
解码器
我们真正的目标不是获得最好的重建结果,而是获得更多的聚类鉴别特征。我们直接利用潜在空间中的噪声干扰来剔除潜在表示中已知的干扰因素。以这种方式训练的模型通过排除而不是包含而变得健壮,并且被期望在集群任务上表现得良好,在集群任务中,即使是输入也包含看不见的麻烦。
利用噪声变压器
ψ
ψ
ψ将潜在表示
Z
Z
Z转换为它们的噪声版本
Z
^
\hat Z
Z^,然后解码器从
Z
Z
Z,
Z
^
\hat Z
Z^重构输入得得到
x
^
z
i
\hat x_{z_i}
x^zi和
x
^
z
^
i
\hat x_{\hat z_i}
x^z^i。
相对重建损失可以写为:

我们还利用原始的重构损失来保证解码器网络的性能,并考虑了
ψ
ψ
ψ为乘法高斯噪声。完全重建损失可定义为:
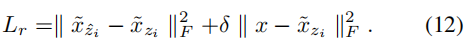
其中,
δ
δ
δ表示不同重建损失的强度。
因此,通过考虑所有的项目,自动编码器网络的总损失可以定义为:

深度谱聚类
将学习到的自编码器参数 θ e θ_e θe 和 θ d θ_d θd 作为聚类阶段的初始条件。光谱聚类可以有效地利用样本之间的关系来减少类内的差异,并产生比K-means更好的聚类结果。在这一步中,我们首先采用自动编码器网络来学习潜在的表示。然后,利用光谱聚类方法将潜在表示嵌入到其相关图拉普拉斯矩阵的特征空间中。所有的样本随后将被聚集在这个空间中。最后,对自动编码器的参数和聚类目标进行了联合优化。
具体来说,我们首先利用潜在表示法Z来构造非负亲和矩阵W:
我们在每次迭代中随机选取一个小批量的m个样本,因此损失函数可以定义为:
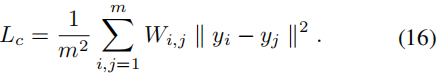
为了防止所有的点在网络映射中被分组到同一个簇中,输出的y在期望中必须是标准正交的。
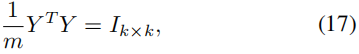
其中,
Y
Y
Y 是一个
m
×
k
m×k
m×k 的矩阵,其中第
i
i
i 行是
y
i
y_i
yi的转置。网络的最后一层用于强制施加正交性[32]约束。该层接收来自K个单元的输入,并作为具有
K
K
K 个输出的线性层,其中权重需要是正交的,从而为一个小批量生成正交化输出
Y
Y
Y。设
Y
~
\widetilde{Y}
Y
为包含该层输入的
m
×
k
m×k
m×k 矩阵,为了使
Y
~
\widetilde{Y}
Y
的列正交化,通过其 QR 分解计算一个线性映射
Z
Z
Z。由于对于任何矩阵
A
A
A,积分
A
⊤
A
A^⊤A
A⊤A 都是满秩的,因此可以通过 Cholesky 分解获得 QR 分解:

其中,
B
B
B 是一个下三角矩阵,而
Q
=
A
(
B
−
1
)
T
Q = A(B^{-1})^T
Q=A(B−1)T。因此,为了使
Y
~
\widetilde{Y}
Y
正交化,最后一层通过从右侧用
m
(
L
−
1
)
T
\sqrt{m}(L^{-1})^T
m(L−1)T 对
Y
~
\widetilde{Y}
Y
进行乘法运算。实际上,
L
~
\widetilde{L}
L
可以通过对
Y
~
\widetilde{Y}
Y
进行Cholesky分解得到,
m
\sqrt{m}
m 的因子是为了满足方程(17)。
我们使用KL散度将潜在表示学习和谱聚类统一起来。在聚类阶段,方程(10)的最后一项可以重写为:
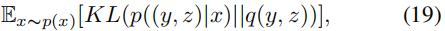
其中,
p
(
(
y
,
z
)
∣
x
)
=
p
(
y
∣
z
)
p
(
z
∣
x
)
,
q
(
y
,
z
)
=
q
(
z
∣
y
)
q
(
y
)
p((y, z)|x) = p(y|z)p(z|x),q(y, z) = q(z|y)q(y)
p((y,z)∣x)=p(y∣z)p(z∣x),q(y,z)=q(z∣y)q(y)。请注意,
q
(
z
∣
y
)
q(z|y)
q(z∣y)是一个均值为
µ
y
µ_y
µy,方差为
1
1
1的正态分布。因此,自编码器和谱聚类网络的总体损失定义为:
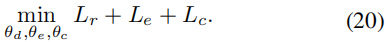
最后,我们同时优化这两个网络,直到收敛,以获得所期望的聚类结果。















 6970
6970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









