










介绍
这一次主要给大家介绍一篇CCS19的工作,“ABS: Scanning Neural Networks for Back-doors by Artificial Brain Stimulation”。
在深度学习之中,存在着一种后门攻击(backdoor attack),它包括两个部分:
- 被植入后门的深度网络(trojaned model, model with backdoors)
- 触发后门的触发器 (trigger)
一旦我们在输入上添加对应的触发器,就会触发网络的后门,使其决策错误;而当输入为正常输入时,模型的表现同正常的模型无异。
有关后门攻击的更多内容,你可以查看我的这篇文章
我们先前介绍过了一个著名的防御工作 Neural Cleanse(之后简称为NC),对后门进行检测、还原以及后续利用神经元裁剪的手段进行防御。
他们观察到,触发器加到输入上,会使得模型的某些神经元表现异常,利用简单的异常检测方法,就可以找出这些过度激活的神经元并且裁剪掉。
我这次介绍的工作,也是一种对模型内部的神经元进行分析的检测手段,那么他们是如何和NC区别开的呢?
- NC可能不能够对后门的触发器进行逆向
- NC需要大量的输入样本来实现高的性能
- NC对于较大的触发器可能会失效
- NC对于在特征空间上的攻击可能表现不佳(与像素空间不同)
我会对这几个动机做进一步的分析,对此不感兴趣的读者,可以直接跳到下一个部分阅读该工作的细节,但是对于科研工作者而言,还是有必要好好分析这些动机的。
这几个动机,我们需要好好看看,到底是不是核心!
关于第一个点,NC不能够对逆向出来后门触发器,这里文章举了一个例子

如上图所示,图片(a)代表触发器,作者将这个触发器植入到飞机类别(Airplane)。(也就是输入上加入触发器,就是使得分类器分类为飞机)
我们观察到,在对标签为鹿进行触发器逆向的时候,我们还原出来的是类似鹿的特征,如图(b)所示。
而在对飞机类别进行触发器逆向的时候,则表现不稳定,有60%的概率生成(d)触发器,有40%的概率生成(c)特征。
的确,NC在逆向出触发器的时候的确不稳定,但是我们真的需要稳定逆行出触发器吗?NC的假设是,我们生成对应触发器的难度在后门对应的目标上会更小,只要满足这个假设就可以。
我们来看看第二个点,NC需要大量的输入样例来获得高的性能。
文章原文是
… , the detection success rate is around 67% for triggers whose size is 6% of an input image. When there is only one input sample per label (10 images in total), the detection accuracy degrades to 20%.
意思就是,一旦我们将可用的输入缩减到10张,正确率就会下降到20%。
乍一看很有道理,但我们翻翻他的实验部分。
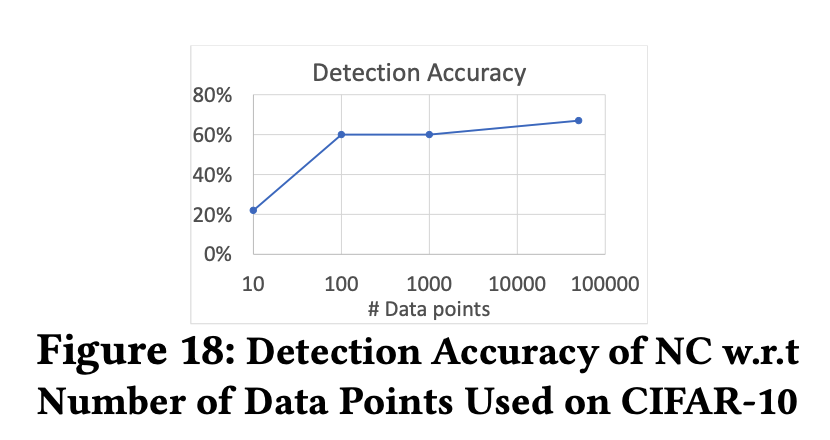
可以看到,我只需要将数据量提升到100张图片,正确率就已经到60%了,100张输入总不算多吧。
不得不说,这个点我觉得比较弱了,属于文章包装的部分
我们再来看看第三点,对于较大触发器失效这件事。
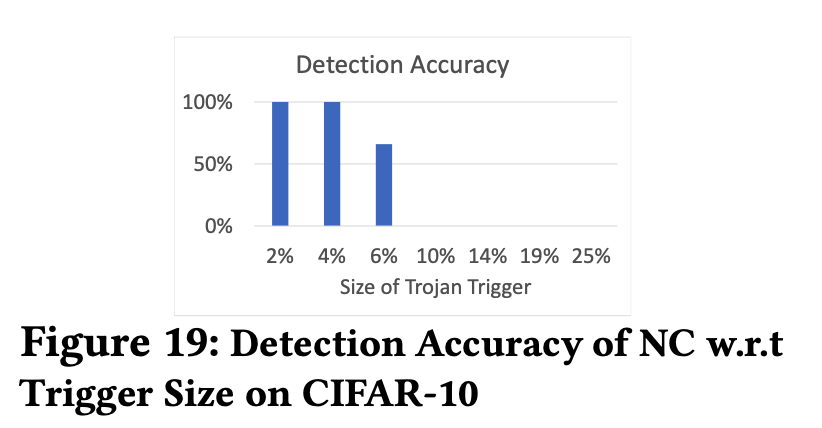
如上图所示,当我们的触发器比较大的时候(超过6%),NC的检测正确率会下降的非常快,这可能是因为触发器的特征已经盖过去原本的特征了。
就相当于你的触发器基本上是一个完整的实体了,那么分类出错有时候也不能认为是网络的问题。
只不过这里到6%就下降很多,可惜的是,我在文中没能看到具体的示例。
于是呢,为了更为具体,我自己在CIFAR-10上构造了不同比例的触发器的样例,大家可以参考
| Clean | 6% |
|---|---|
 |  |
CIFAR-10输入是32x32,所以6%约是8x8的一个区域
这么一个区域其实已经非常明显了,所以检测精度下降应该是正常的事。
最后来看看第四点区别,NC对于特征空间上的攻击可能表现不佳。
先看看这里所说的特征空间的攻击究竟是啥

如上图所示,看上去似乎是色彩风格上的变换,也就是将触发器设置成一种色彩风格。
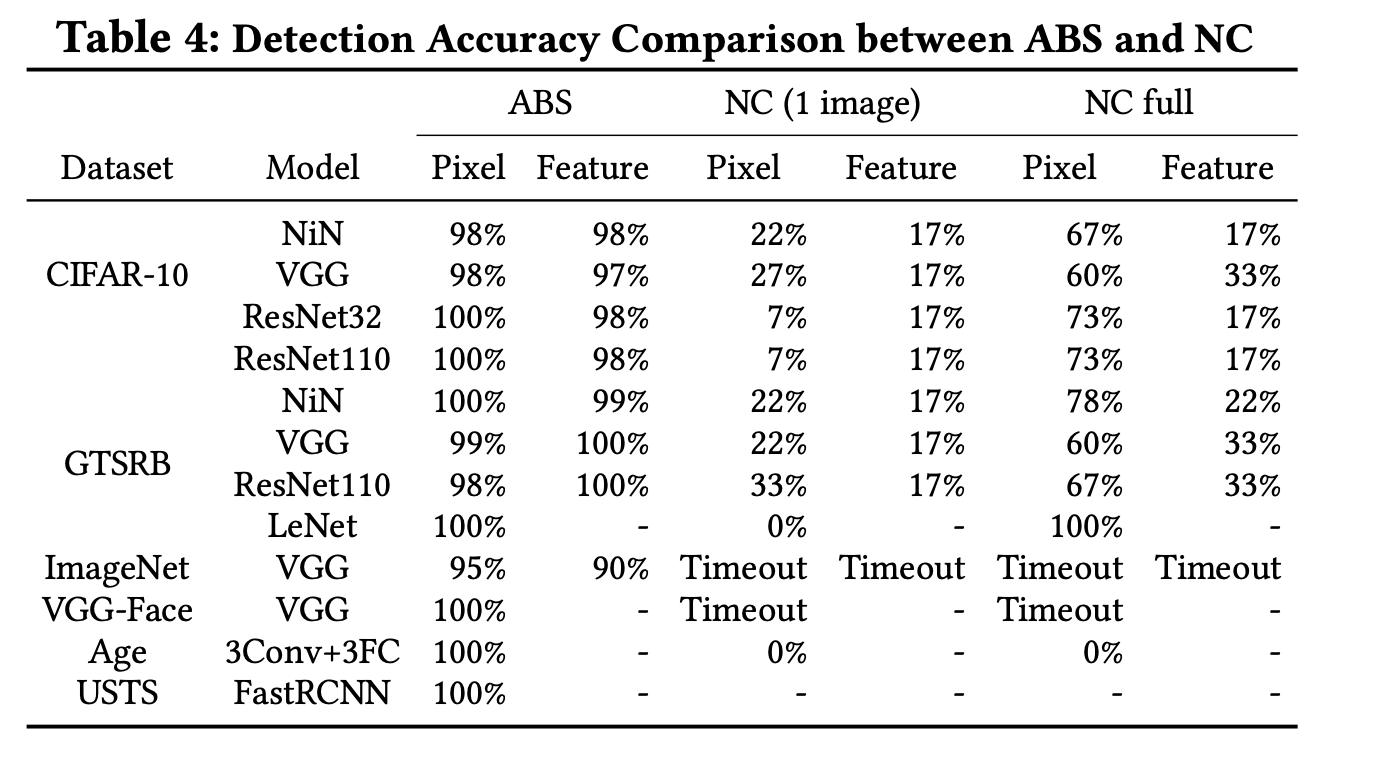
我们来看看这个表格,对于NC我们只需要看最右边的,满状态的NC方法在特征触发器上表现不佳,最多只有33%的检测精度,一个理解是这种风格上的触发器,会使得先前的神经元不会过度激活,攻击更为隐蔽。
我们分析了NC方法的一些“缺陷”之后,我们来看看新的方法吧。
新的方法
首先给出两个观测:
- 成功的后门攻击会产生“被危害的”神经元
- 这些有害神经元表征了一个子空间,该空间割裂了整个空间
第一个观测和NC的基本一致,即触发器会引起一些神经元表现异常。
割裂原本的空间这回事,作者只给出了朴素情况下的示例。
存在着这些假设,下一步就是如何找到这些“有害”的神经元。
这里给出大致的步骤(参考于其github实现),来找到候选的有害神经元:
- 首先对于某一个固定的层,随机选取一个通道
- 然后对于一堆可信的图片,计算出该通道下最大的激活值
- 将该通道下所有的激活值替换为最大激活值
- 将这个中间输出继续输入给下一个层
- 如果,最后的结果导致分类错误,并且对于超过90%的图片,都导致同一错误分类结果
- 则将该层的该通道记为“候选的有害神经元”
在代码的实现上,这里都用的整个通道来表示一个神经元
找到这些候选的有害的神经元之后,便需要确定是否的确是有害的神经元,于是,作者通过反向构造触发器,通过验证该构造的触发器的有效性,来判别是否是有害的神经元。
那么如何构造触发器呢?该工作使用的是梯度下降的策略
损失函数为
L
=
w
1
f
2
−
w
2
f
1
+
w
3
⋅
s
u
m
(
m
a
s
k
)
−
w
4
⋅
S
S
I
M
(
x
,
x
′
)
x
′
=
x
∘
(
1
−
m
a
s
k
)
+
t
r
i
g
g
e
r
∘
m
a
s
k
\mathcal{L} = w_1f_2-w_2f_1 +w_3\cdot sum(mask) - w_4\cdot SSIM(x,x')\\ x' = x\circ (1-mask) + trigger\circ mask
L=w1f2−w2f1+w3⋅sum(mask)−w4⋅SSIM(x,x′)x′=x∘(1−mask)+trigger∘mask
其中所有的权重
w
i
>
0
w_i > 0
wi>0 ,
f
1
f_1
f1 是该候选神经元的激活值,
f
2
f_2
f2 是候选神经元激活值和其他神经元激活值的差异,
m
a
s
k
mask
mask 是触发器的区域,
S
S
I
M
SSIM
SSIM 刻画原图和加触发之后的相似程度。
故,优化目标为,最大化该候选神经元激活值, 但最小化和其他神经元的激活值差异,最小化触发器的面积,同时最大化和原图的相似程度。
REASR分数
在前面我们说到,本文使用候选的有害神经元生成的触发器,再根据该触发器的有效性来判别是否有后门。
这里便引入了一个REASR分数,REASR即 Attack Success Rate of Reverse Engineered trojan triggers.
也就是基于逆向工程的触发器的攻击成功率,这个逆向工程就是我们先前说到的,基于梯度下降的触发器生成方法。
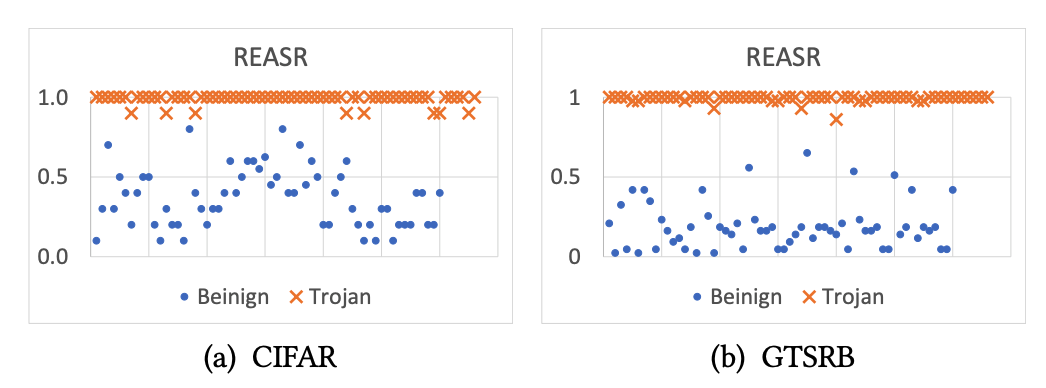
如上图所示,该分数对于后门模型有着较强的刻画能力。
实验评估
我们先来看看后门检测的成功率,和NC进行对比,如下图所示,在多个数据集上针对两种攻击形式表现出色。
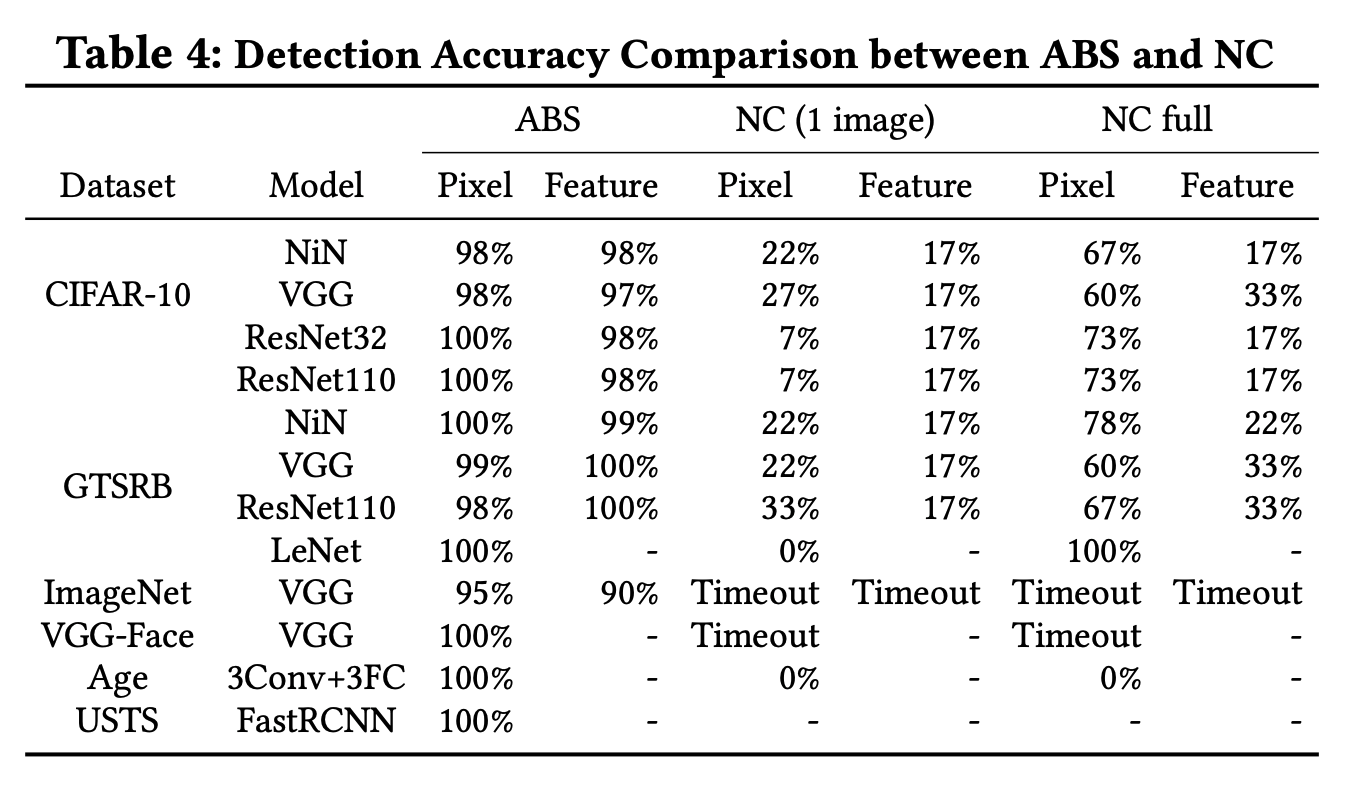
然后我们来看看计算的时间代价
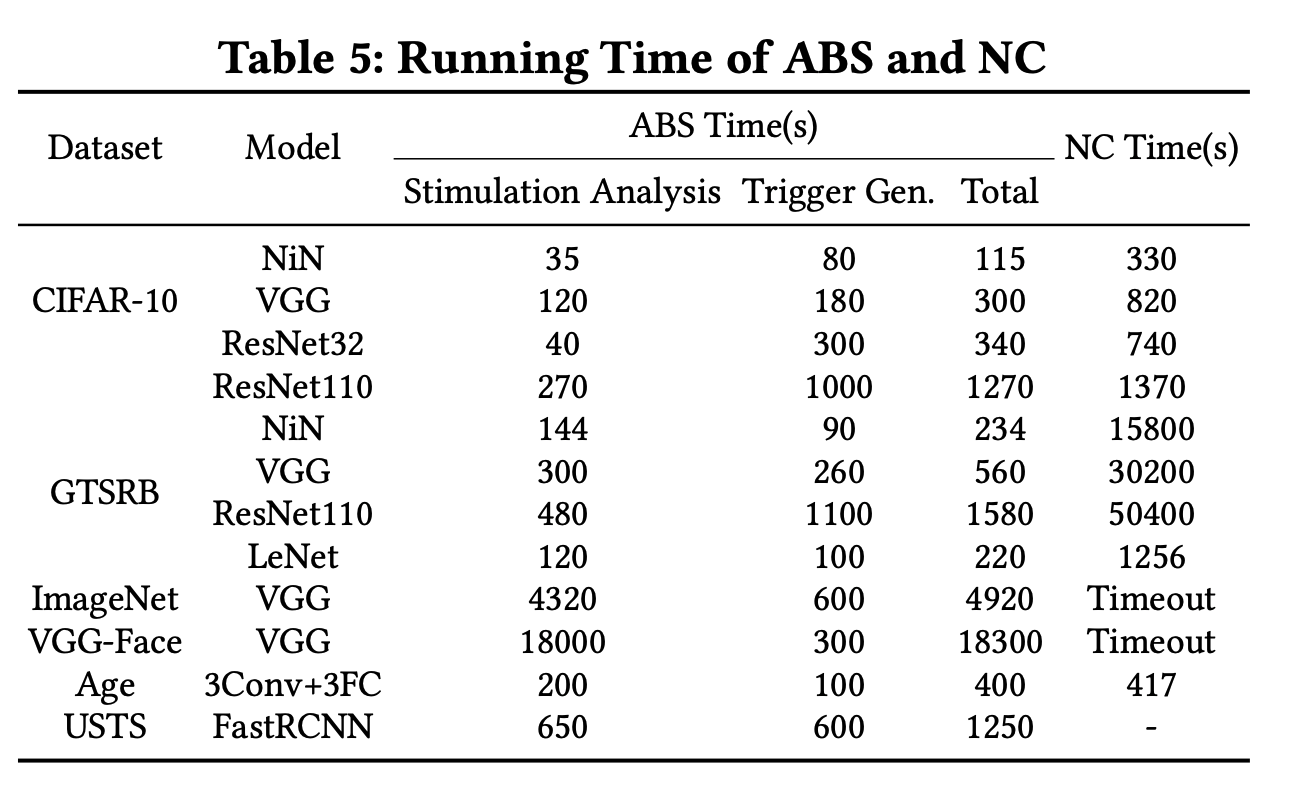
如上图所示,NC需要计算较多时间,ABS由于基于采样,缩减了许多计算耗时。
结论
ABS相比较于NC,从计算速度和准确性上都获得了较大的提升,不过可惜的是,文章并没有针对一些新的后门攻击做出实验。
整体上看,该工作的包装性是比较高的,比如用神经元来进行分析,但是实现上却是整个通道。
并且,该工作还是依赖于“触发器会引发异常的激活值”这一假设,那么,在进一步更为隐蔽的后门攻击下,该方法的有效性仍需要验证。

















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









