










应对长尾分布的目标检测 – Balanced Group Softmax
这次给大家介绍一篇CVPR2020的文章,题为“Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax”,主要解决目标检测中的长尾数据分布问题,解决方案也十分简洁。
长尾分布的数据
首先,长尾分布的数据广泛存在,这里以COCO和LVIS两个数据集为例,如下图所示:

横坐标是类别的索引,纵坐标是对应类别的样本数量。
可以看到,在这两个数据集当中,存在着明显的长尾分布。
以往应对长尾分布的方法
这里给出一些相关的工作,按类别给出:
- 基于数据重采样(data re-sampling)
- 对尾部数据进行过采样:Borderline-smote: a new over-sampling method in im- balanced data sets learning
- 对头部数据进行删减:class imbalance, and cost sensitivity: why under-sampling beats over sampling
- 基于类别平衡的采样:Exploring the limits of weakly supervised pretraining.
- 代价敏感学习(cost- sensitive learning)
- 通过对loss进行调整,对不同类别给予不同的权重
这些方法通常都对超参数敏感,并且迁移到检测框架的时候表现不佳(分类任务和检测任务的不同)
Balanced Group Softmax
这里直接给出算法的具体框架:

如上图所示,在训练阶段,我们会对类别进行分组,不同组内部分别计算Softmax,然后计算出各自的交叉熵误差。
对于分组,论文给的是按0,10,100,1000,+inf作为切分点进行切分
这里我们需要为每一个组分别添加一个other类别,使得,当目标类别不在某一个组的时候,groundtruth设置为other。
最终的误差形式为:
L
k
=
−
∑
n
=
0
N
∑
i
∈
G
n
y
i
n
log
(
p
i
n
)
\mathcal{L}_k=-\sum_{n=0}^{N}\sum_{i\in \mathcal{G}_n}y_i^n\log (p_i^n)
Lk=−n=0∑Ni∈Gn∑yinlog(pin)
其中,
N
N
N 是组的数量,
G
n
\mathcal{G}_n
Gn 是第
n
n
n 个组的类别集合,
p
i
n
p_i^n
pin 是模型输出的概率,
y
i
n
y_i^n
yin 是标签。
效果评估
这里给出一张全面对比的精度表
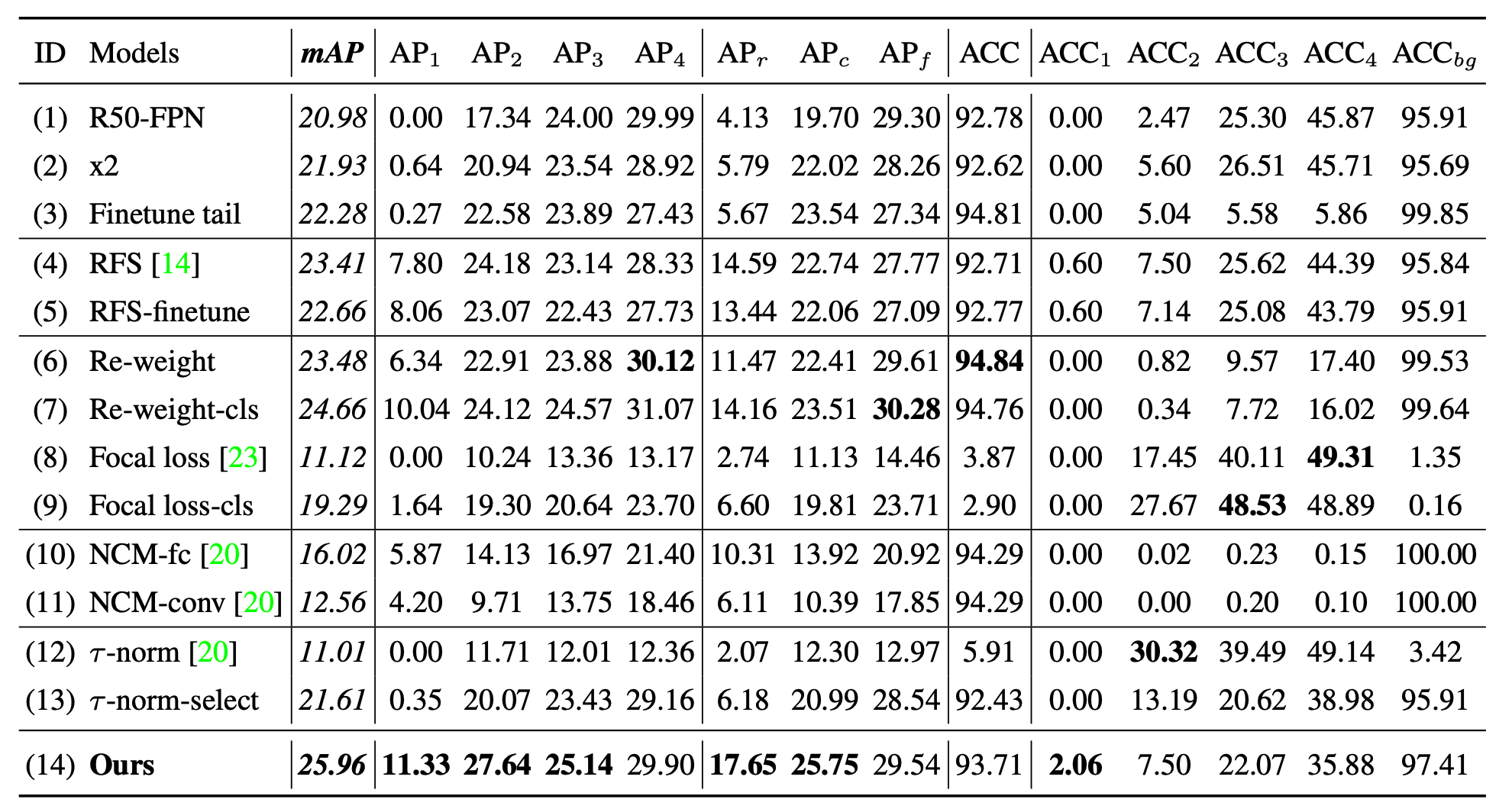
AP的下标对应着划分的组的索引,可以看到,在尾部的精度,也就是 A P 1 AP_1 AP1 和 A C C 1 ACC_1 ACC1 上都达到了SOTA的性能。














 935
935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









