







首先,笔者通过与SD的对比来介绍SDXL。如果对SD没有了解,强烈建议看看这篇:初探StableDiffusion
其次,SDXL的论文为:《SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis》(2023)
一、SDXL
#1. 网络结构的两项改进:
1️⃣SDXL将「U-Net主干部分」扩大了三倍,并添加了更多的注意力。
2️⃣SDXL引入了一个细化模型Refiner,以进一步提高生成图像的视觉逼真度。
具体见下图所示(该图来自SDXL论文):
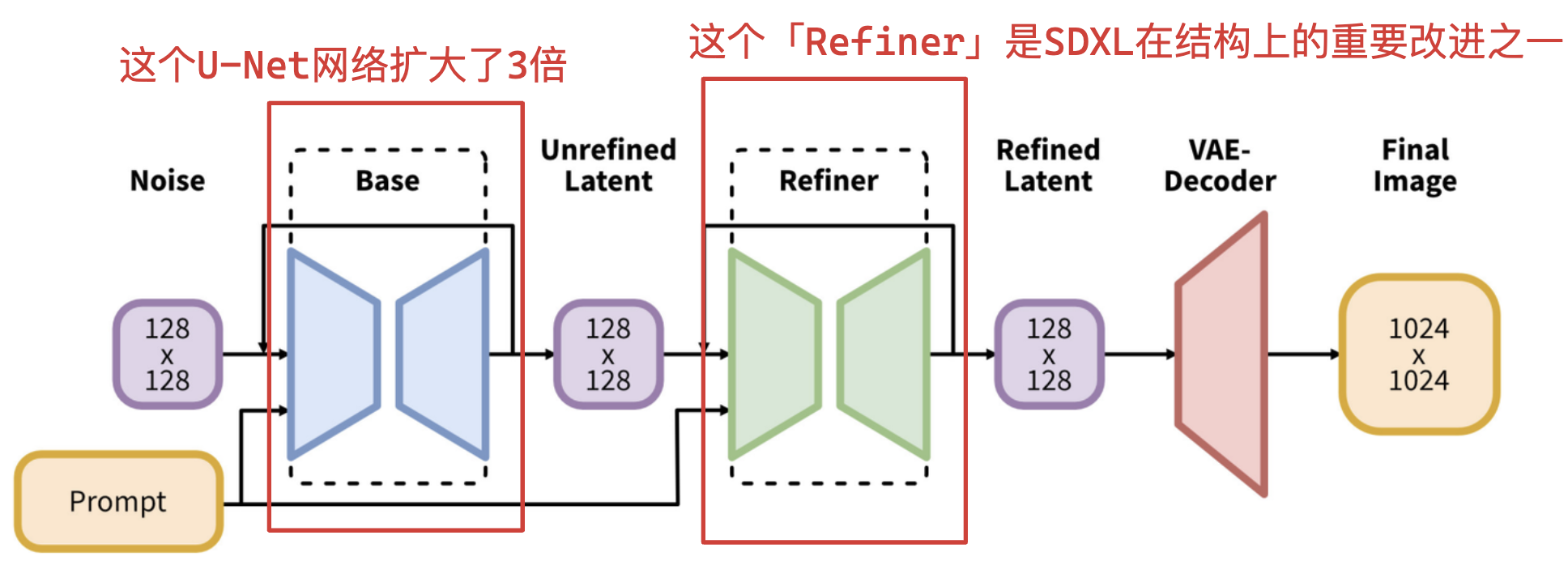
#2. SD与SDXL的对比
1️⃣整体情况
| SD1.5 / 2.1 | SDXL | |
|---|---|---|
| 定位 | 基础“txt2img”生成模型 | SD的升级版(更高分辨率、更好的语义理解和生成) |
| 发布时间 | 2022.8、2022.12 | 2023.7 |
| 模型参数量 | ~860M(Unet部分) | ~2.6B(Unet部分)+ ~6.6B(Refiner) |
| 分辨率支持 | 512×512(SD1.5)、768×768(SD2.1) | 1024×1024 |
| 模型架构 | 单一U-Net | 两阶段生成(Base + Refiner) |
| 生成质量 | 细节较差、易出现畸形 | 更真实的细节、光影 |
| 文本理解 | 对Prompt支持较差 | 更准确的语义理解 |
2️⃣U-Net(Base Model)
| SD1.5 的 U-Net | SDXL 的 U-Net | |
|---|---|---|
| 结构改进 | 基础 U-Net + Cross-Attention | 更大 U-Net + 多尺度注意力 |
| 文本编码器 | CLIP ViT-L/14 | OpenCLIP ViT-bigG + DINOv2 |
| 训练数据 | LAION-5B 子集(~20亿图像) | 更优质筛选的数据集 |
#3. SDXL中的细化模型Refiner是个啥?
1️⃣Refiner的作用
Refiner负责对「Base Model」生成的粗糙图像进行细节增强、噪声去除和局部修正。
Refiner的输入:Base Model 生成的潜变量(Latent)或低分辨率图像。
Refiner的输出:更高清、更细腻的最终图像。
2️⃣Refiner的局限性
- 显存占用:比单独使用 Base Model 增加约 20%~30% 显存消耗。
- 速度代价:生成时间延长 1.5~2 倍。
- 过度处理风险:若 Refiner 权重过高,可能导致图像失去自然感(如塑料质感)。
#4. 笔者的建议:什么时候应该用SDXL,什么时候应该用SD
1️⃣推荐用SDXL的情景:
情况一:Refiner能够提高生成图像的视觉逼真度 ➡️ 生成写实风格人像、复杂纹理(如森林、建筑)
情况二:需要印刷或大屏展示的高分辨率输出
2️⃣推荐用SD的情景:
情况一:显存不够运行SDXL的,因为SDXL网络结构大了三倍以上
情况二:快速草图测试、动漫风格生成(SD1.5就够啦)
#5. 最后,根据笔者的实际部署
SD1.5能够在显存12GB的显卡上进行简易的微调训练(即Dreambooth),就是要使用一些降低显存的方法,比如:xformer、梯度检查点和梯度累加部署等。
但SDXL真得16GB及以上了,毕竟输入图片大小突然变成了1024*1024。
二、SDXL-Turbo
总的来说,SDXL-Turbo在模型上没有什么修改,它就是SDXL的蒸馏版本。
即小幅度降低生成效果,大幅度提高生成速度。下表展示了它们的大致区别:
| 维度 | SD 1.5/2.1 | SDXL | SDXL-Turbo |
|---|---|---|---|
| 分辨率 | 512×512 | 1024×1024 (+Refiner) | 1024×1024 |
| 参数量 | ~860M | ~2.6B | ~2.6B(蒸馏后) |
| 文本理解 | 中等 | 优秀(双编码器) | 优秀但更敏感 |
| 适用场景 | 快速原型、艺术创作 | 商业级高清输出 | 实时应用、交互设计 |


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











