







1.文章说的重点是啥
文章就是对与FPN金字塔的模型提出了三点改进。而FPN金字塔特征图是引用一篇论文
论文:feature pyramid networks for object detection
论文链接:link=https://arxiv.org/abs/1612.03144
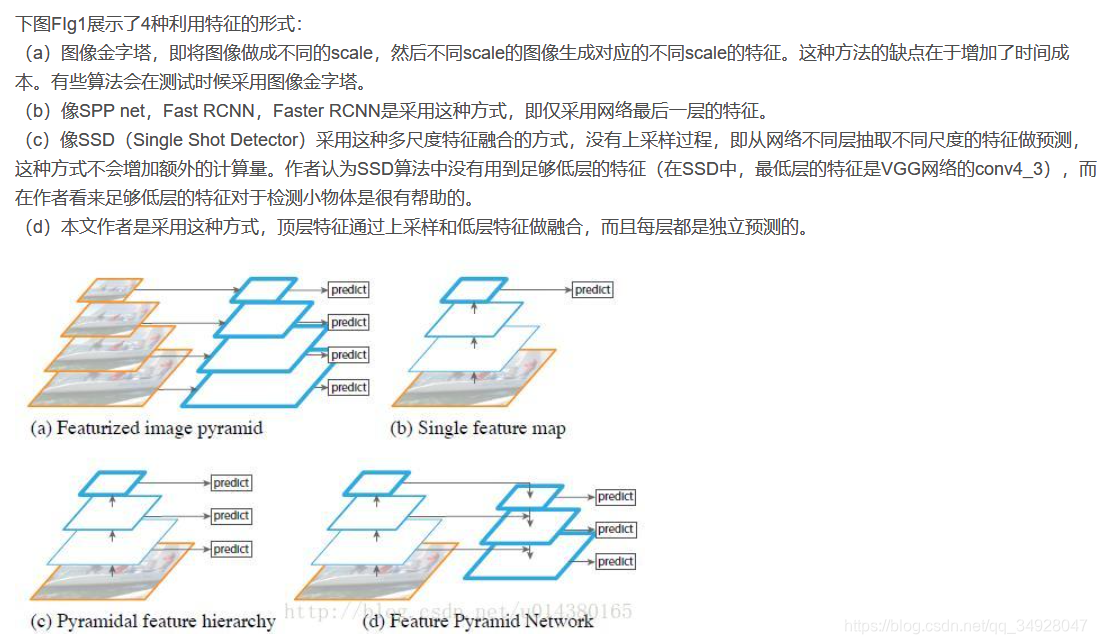
转载与YYAILearner
在这里简单介绍一下就行。
2.针对的三个问题如歌应答
全文是列举了FPN模型三个不足之处然后对它进行改进。
2.1 第一个问题是啥,如何解答
1.第一个问题是特征提取前
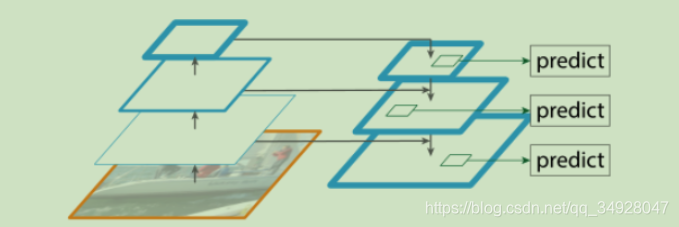
有这个图看出来特征提取之前,FPN前提取特征是将原始图片缩放到原来一般大小,但是这样最高层容易特征信息丢失,因为被压缩了。虽然可以联系模型的上下图片进行特征提取来减少误差,但是终究还是有误差,所以本文对这一步就行改善。
解决方法: 针对不同层特征存在语义差异问题,在不同层使用RPN生成大量ROIs,将每一个ROIs分别映射至相关层进行ROI-Align pooling得到相应的特征然后目标预测,这些层的分类和回归参数是共享然后使用损失进行参数更新,以此来使不同层的特征具有相似性。在测试时,这个辅助分支是不需要的,因此没有提升计算量。
2.2 第二个问题是啥,如何解决
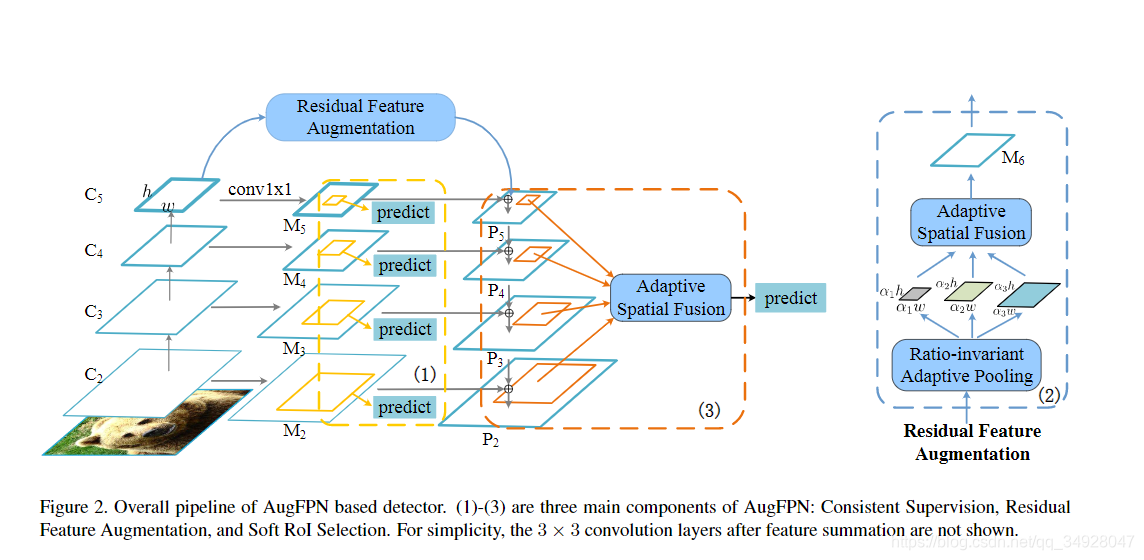
最高层特征的信息损失:在FPN中,特征融合通常是最高层特征自上而下进行融合,然而,由于通道减少,位于金字塔最高层的特征反而丢失了信息。通过结合全局上下文特性,可以减少信息丢失。但是这种将特征图融合成一个向量的策略可能会丢失空间关系和细节,因为在一张图像中可能会出现多个对象。
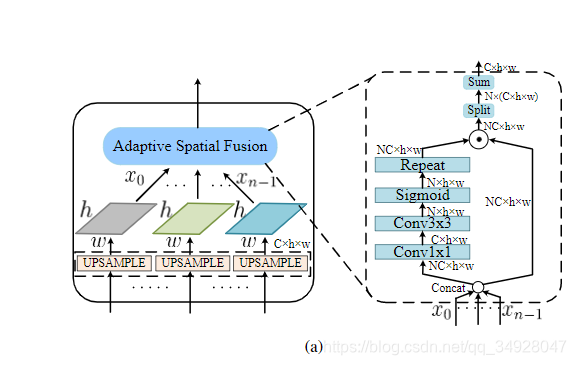
解决办法 由于降维操作,C5至P5的信息部分丢失,为解决此问题文中提出Adaptive Spatial
Fusion (ASF) 模块,其结构如图三,将C5特征图进行与图像比例有关的自适应池化,实验中选择0.1,0.2,0.3(池化后和原特征图的比例),池化后的特征图上采样回与C5一致后进行自适应的空间融合,类似于学习空间权重(空间注意力机制)然后加权相加,融合后的特征作为M6,与M5相加作为P5,以此解决信息丢失;
2.3第三个问题是啥,文章如何解决
在目标框预测时,每个目标只对应一层特征图,忽略了其它层的帮助。
解决办法
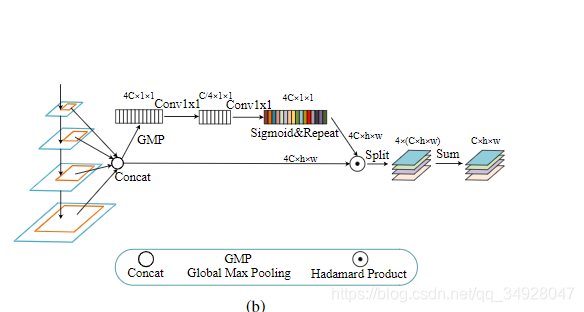
将RPN部分预测的每一个ROI映射到P2-P5,然后进行参数化的ROI_Pooling,其结构如图四,即为ROI对应每一层的特征块学习一个参数,进而将多层特征块加权求和,得到最终的特征块再进行目标检测。

















 6141
6141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









