







 本文深入探讨了正向前视断言(?=...)在正则表达式中的应用,通过实例展示了如何精确匹配特定模式。同时,对比了Python RE模块中sub和subn函数的区别,subn不仅进行替换还返回替换次数,更适用于需要了解替换详情的场景。
本文深入探讨了正向前视断言(?=...)在正则表达式中的应用,通过实例展示了如何精确匹配特定模式。同时,对比了Python RE模块中sub和subn函数的区别,subn不仅进行替换还返回替换次数,更适用于需要了解替换详情的场景。
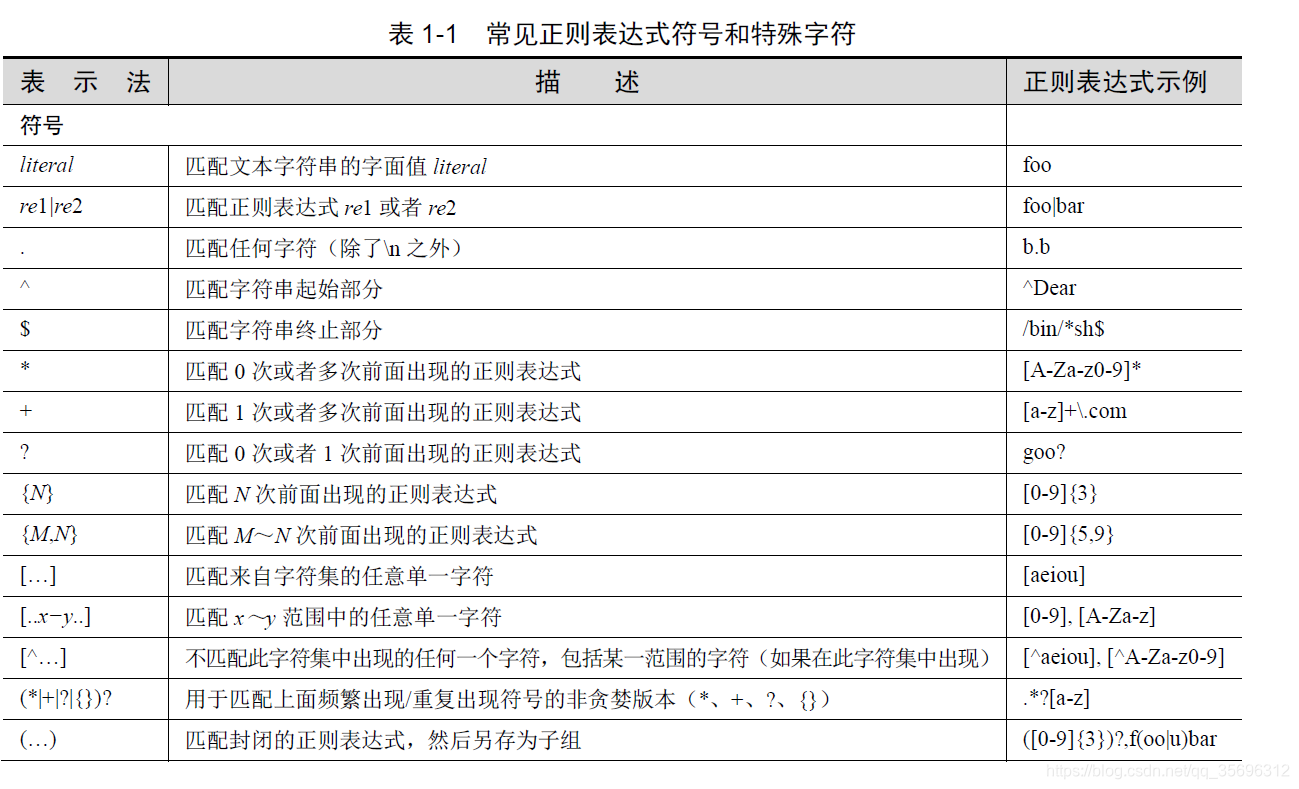
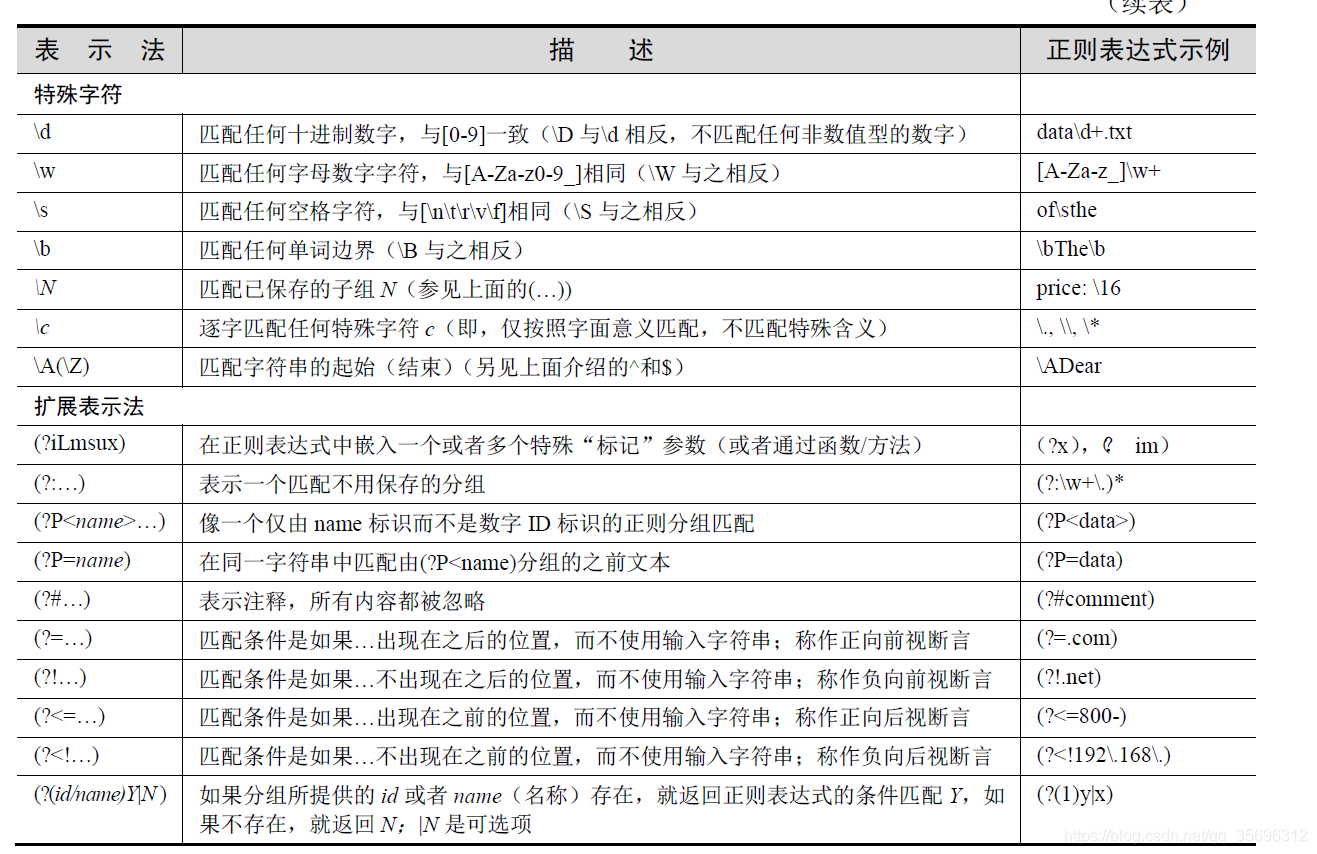
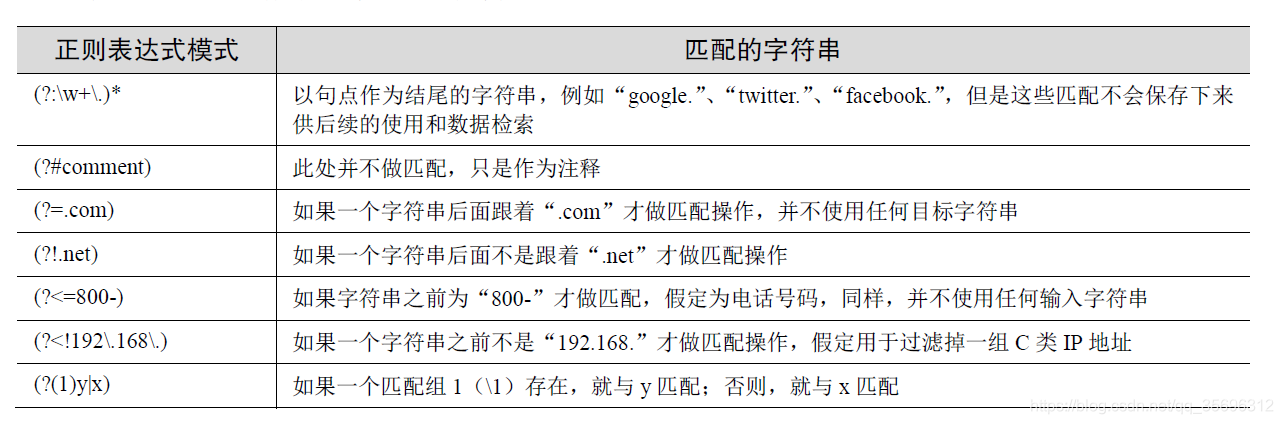 正向前视断言(?=...)的用法
正向前视断言(?=...)的用法
import re
#(?=.com)只有在后面是.com的时候才做匹配,以下代码仅返回第二行的cm
print(re.findall(r'(?m)(cm)(?=.com)','''
cm
cm.com
cmcm
'''))sub和subn的区别,subn返回一个元组,包含替换的次数
>>> re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
'attn: Mr. Smith\012\012Dear Mr. Smith,\012'
>>>
>>> re.subn('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
('attn: Mr. Smith\012\012Dear Mr. Smith,\012', 2)
>>>
>>> print re.sub('X', 'Mr. Smith', 'attn: X\n\nDear X,\n')
attn: Mr. Smith
Dear Mr. Smith,
>>> re.sub('[ae]', 'X', 'abcdef')
'XbcdXf'
>>> re.subn('[ae]', 'X', 'abcdef')
(' XbcdXf', 2)贪婪匹配,默认情况下.*(xxx)是贪婪匹配,要改成非贪婪模式需要修改为.*?(xxx)

















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









