







在 AI 模型不断迭代的浪潮中,5月29日 深度求索(DeepSeek)再次带来惊喜!DeepSeek R1 模型已完成小版本升级,摇身一变成为 DeepSeek - R1 - 0528,为广大用户开启全新智能体验。如今,用户只需通过官方网站、APP 或小程序进入对话界面,轻松开启 “深度思考” 功能,就能感受新版模型的独特魅力,并且 API 也已同步更新,调用方式一如既往,操作毫无负担。
深度思考能力大跃升
DeepSeek - R1 - 0528 依旧依托 2024 年 12 月发布的 DeepSeek V3 Base 模型作为基座,不过在后训练阶段,团队投入海量算力精心雕琢,使得模型思维深度与推理能力实现质的飞跃。在数学难题攻克、复杂编程任务执行以及通用逻辑分析等多个基准测评里,更新后的 R1 模型一骑绝尘,成绩在国内所有模型中独占鳌头,整体表现更是直逼国际顶尖模型,像 OpenAI 的 o3 与谷歌的 Gemini - 2.5 - Pro,已然达到同一梯队水平。
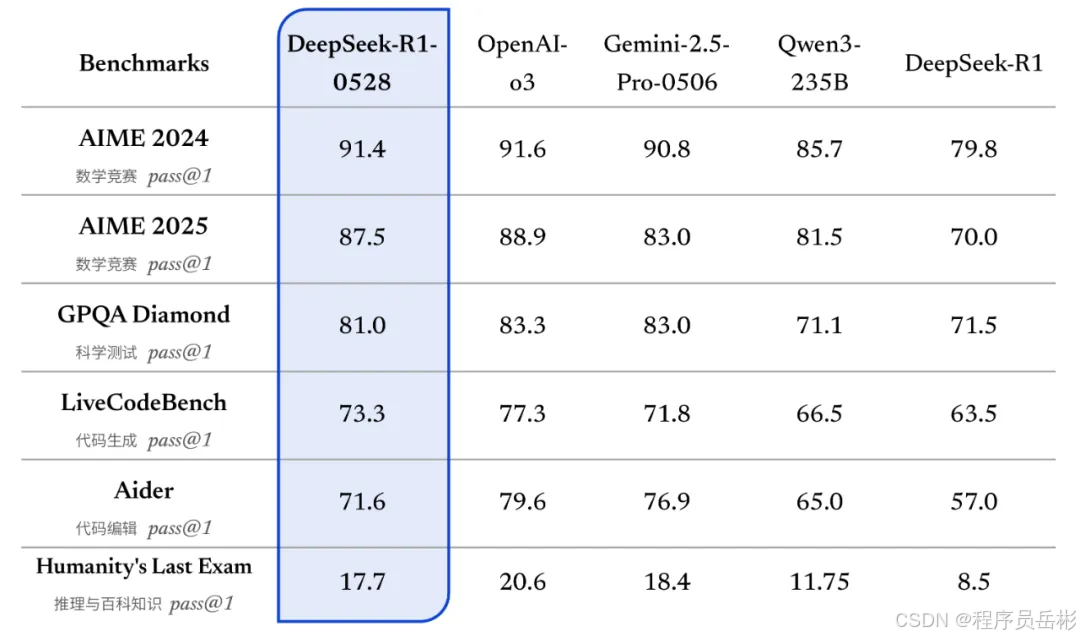
相较于旧版 R1,DeepSeek - R1 - 0528 在复杂推理任务上的进步堪称惊艳。以 AIME 2025 测试为例,旧版模型准确率仅为 70%,而新版模型强势攀升至 87.5%。从思维深度层面剖析,在 AIME 2025 测试集里,旧版模型平均每题消耗 12K tokens,新版则高达 23K tokens,这意味着新版模型在解题时思考更加详尽、深入,不放过任何一个逻辑细节,推理过程宛如一位资深专家抽丝剥茧。
不仅如此,团队将 DeepSeek - R1 - 0528 的思维链进行蒸馏,用于训练 Qwen3 - 8B Base,从而诞生了 DeepSeek - R1 - 0528 - Qwen3 - 8B。别看它是 8B 模型,在数学测试 AIME 2024 中,实力仅次于 DeepSeek - R1 - 0528,成绩超越 Qwen3 - 8B 达 10.0%,与 Qwen3 - 235B 不相上下。这一成果无论对于学术界推理模型研究,还是工业界小模型开发,都犹如一座指明灯塔,蕴含着巨大价值,为后续模型优化提供全新思路与方向。
多领域能力全面进化
攻克 “幻觉” 难题
一直以来,“幻觉” 问题困扰着 AI 模型,而新版 DeepSeek R1 针对这一顽疾精准施策,取得显著成效。在改写润色、总结摘要、阅读理解等常见应用场景中,与旧版相比,幻觉率大幅降低 45 - 50% 左右。如今模型输出内容更加真实可靠,无论是帮用户提炼文章核心要点,还是改写文案,都能有效避免无中生有,让用户收获精准信息。
创意写作再升级
基于旧版 R1 良好基础,DeepSeek - R1 - 0528 对议论文、小说、散文等各类文体创作进行深度优化。它不再局限于简短表述,能够洋洋洒洒输出篇幅更长、结构严谨、内容丰富完整的长篇作品,而且写作风格愈发贴合人类偏好,或犀利深刻,或温情细腻,为用户带来如同人类创作者般的写作体验,满足多样化创作需求。
工具调用新支持
DeepSeek - R1 - 0528 新增工具调用功能(虽说在 thinking 模式下暂不支持),为模型应用拓展新边界。在 Tau - Bench 测评中,airline 领域成绩达到 53.5%,retail 领域为 63.9%,与 OpenAI o1 - high 表现相当。虽说和 o3 - High 以及 Claude 4 Sonnet 相比尚有差距,但已然展现出强大潜力。例如借助 LobeChat 使用该模型工具调用能力,能够快速实现网页文章总结,大大提高信息处理效率。此外,模型在前端代码生成、角色扮演等领域能力也迎来更新提升,如在网页端能轻松调用它开发出具有现代简约风格的单词卡片应用,HTML/CSS/JavaScript 代码一气呵成,界面美观且功能完备。

API 同步焕新,使用指南奉上
随着模型升级,API 也完成同步更新,好消息是接口与调用方式保持不变,用户无需重新学习复杂操作。新版 R1 API 不仅延续查看模型思考过程的实用功能,还新增 Function Calling 和 JsonOutput 支持,为开发者提供更多灵活操作空间。不过需要注意,新版 R1 API 对 max_tokens 参数含义做出调整,现在它用于限制模型单次输出总长度(包含思考过程),默认值为 32K,最大值可达 64K。API 用户务必及时调整该参数设置,防止输出内容被意外截断,影响使用效果。若想详细了解 R1 模型使用方法,可前往 API 指南:https://api-docs.deepseek.com/zh - cn/guides/reasoning_model 查阅。本次 R1 更新后,官方网站、小程序、App 端和 API 中的模型上下文长度维持在 64K。若用户对上下文长度有更高要求,可通过第三方平台调用上下文长度为 128K 的开源版本 R1 - 0528 模型。
开源助力,共享创新成果
DeepSeek - R1 - 0528 与之前的 DeepSeek - R1 一脉相承,采用相同 base 模型,只是在后续训练方法上推陈出新。对于私有化部署用户而言,操作极为简便,仅需更新 checkpoint 和 tokenizer_config.json(涉及 tool calls 相关变动)即可。该模型参数规模达 685B(其中 14B 为 MTP 层),开源版本上下文长度拓展至 128K(网页端、App 和 API 提供 64K 上下文)。若想下载 DeepSeek - R1 - 0528 模型权重,可通过以下渠道:
Model Scope: https://modelscope.cn/models/deepseek-ai/DeepSeek-R1-0528
Huggingface: https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
和旧版本 DeepSeek - R1 一样,此次开源仓库(包含模型权重)统一遵循 MIT License 协议,充分给予用户自由,允许利用模型输出、通过模型蒸馏等方式训练其他模型,旨在促进 AI 领域技术交流与创新,让更多开发者在其基础上进行二次开发,共同推动 AI 技术蓬勃发展。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











