










note
- DeepSeek-V3 是一个混合专家(MoE) 语言模型,整体参数规模达到 671B,其中每个 token 激活的参数量为 37B。
评估结果表明,DeepSeek-V3 在性能上超越了其他开源模型,并能够与主流闭源模型相媲美。 - 基于 DeepSeek-V2,团队采用了多头潜在注意力(MLA)和 DeepSeekMoE 架构,以实现高效推理和经济的训练。模型在延续 MLA 和 DeepSeekMoE 架构优势的基础上,创新性地提出了无辅助损失负载均衡策略,并引入多 token 预测训练目标以提升性能。完整训练过程(包括预训练、上下文长度扩展和后训练)仅需 2.788M H800 GPU 小时。
- 通过采用 FP8 训练技术和精细的工程优化,模型实现了高效的训练过程。在后训练阶段,成功将 DeepSeek-R1 系列模型的推理能力迁移至新模型。
文章目录
一、deepseek v3模型
https://github.com/deepseek-ai/DeepSeek-V3
对应的论文为:[2412.19437] DeepSeek-V3 Technical Report [1]
对应的代码库为:GitHub - deepseek-ai/DeepSeek-V3 [2]
基于提升性能和降低成本的双重目标,在架构设计方面,DeepSeek-V3 采用了MLA来确保推理效率,并使用 DeepSeekMoE来实现经济高效的训练。这两种架构在 DeepSeek-V2 中已经得到验证,证实了它们能够在保持模型性能的同时实现高效的训练和推理。
二、基本架构
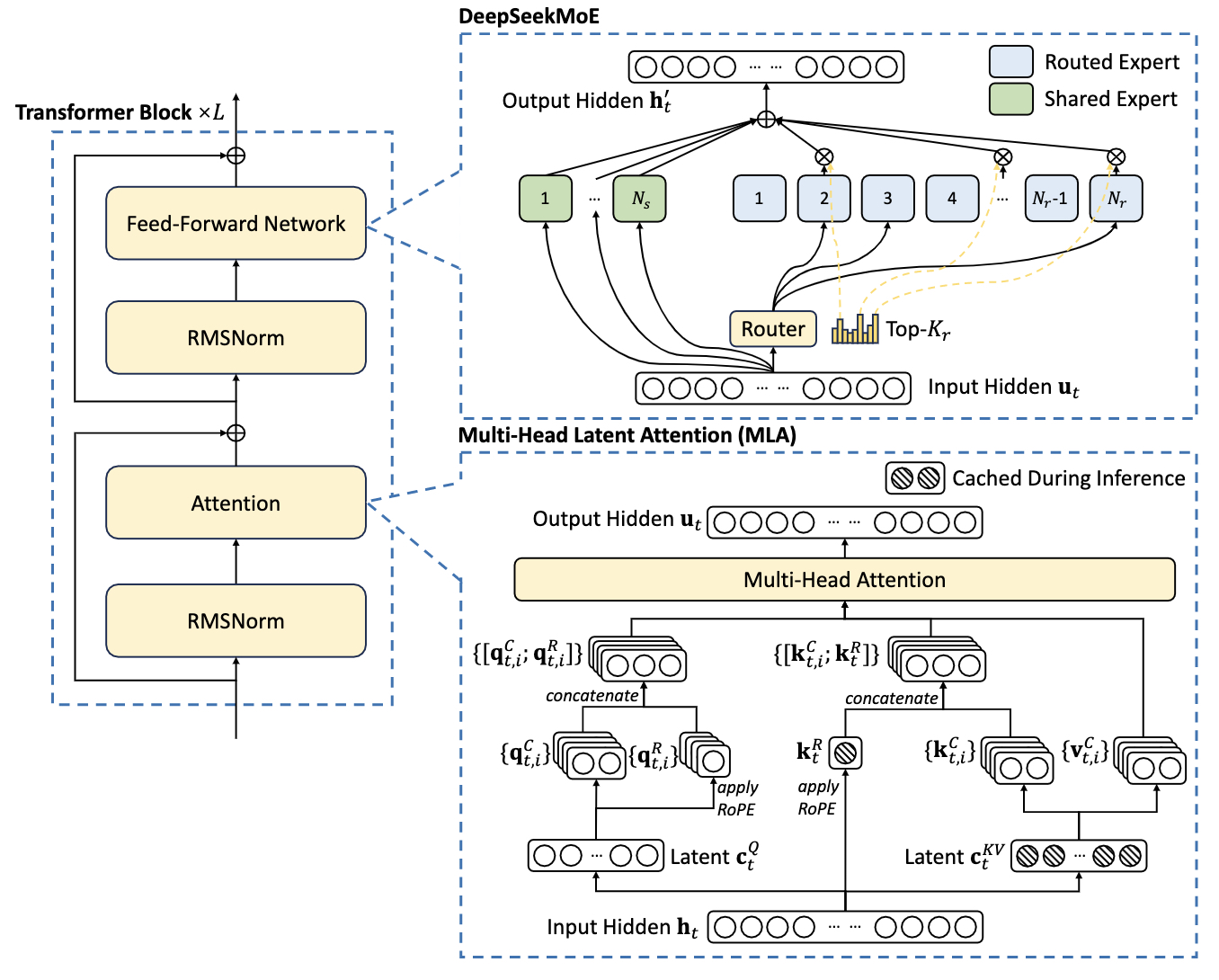
1. 模型架构
DeepSeek-V3 的基础架构建立在 Transformer 框架之上。为实现高效推理和降低训练成本,该模型采用了经 DeepSeek-V2 验证的 MLA 和 DeepSeekMoE 技术。相比 DeepSeek-V2,本研究在 DeepSeekMoE 中创新性地引入了无辅助损失负载均衡策略,有效降低了负载均衡过程对模型性能的影响。
2. MTP提升响应速度
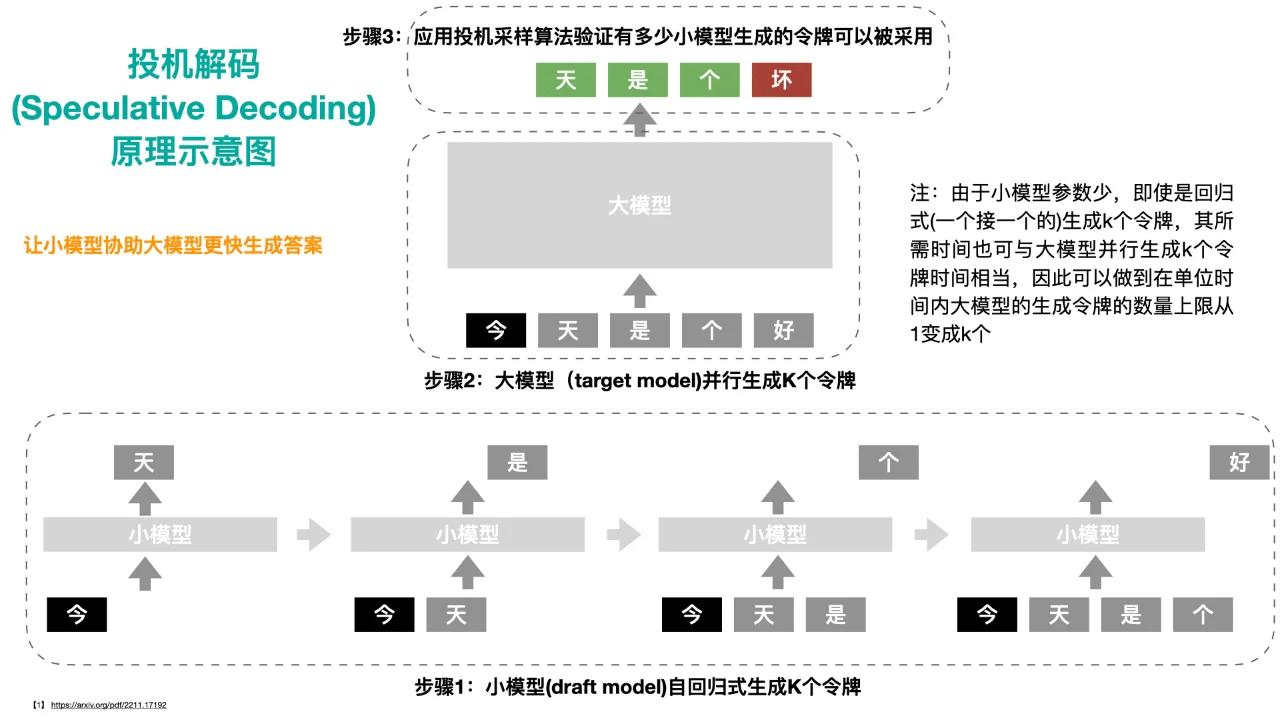
(1)什么是投机解码?
简单来说,这就像是“小助手先写,老板批量审核”。让小模型先快速生成多个token(令牌/字),然后让大模型一次性并行验证这些令牌。由于小模型参数少,写草稿速度快,可以在大模型验证一次的时间内写好几个字(令牌)。而大模型可以并行的去验证小模型写好的几个字,从而降低反应时间。
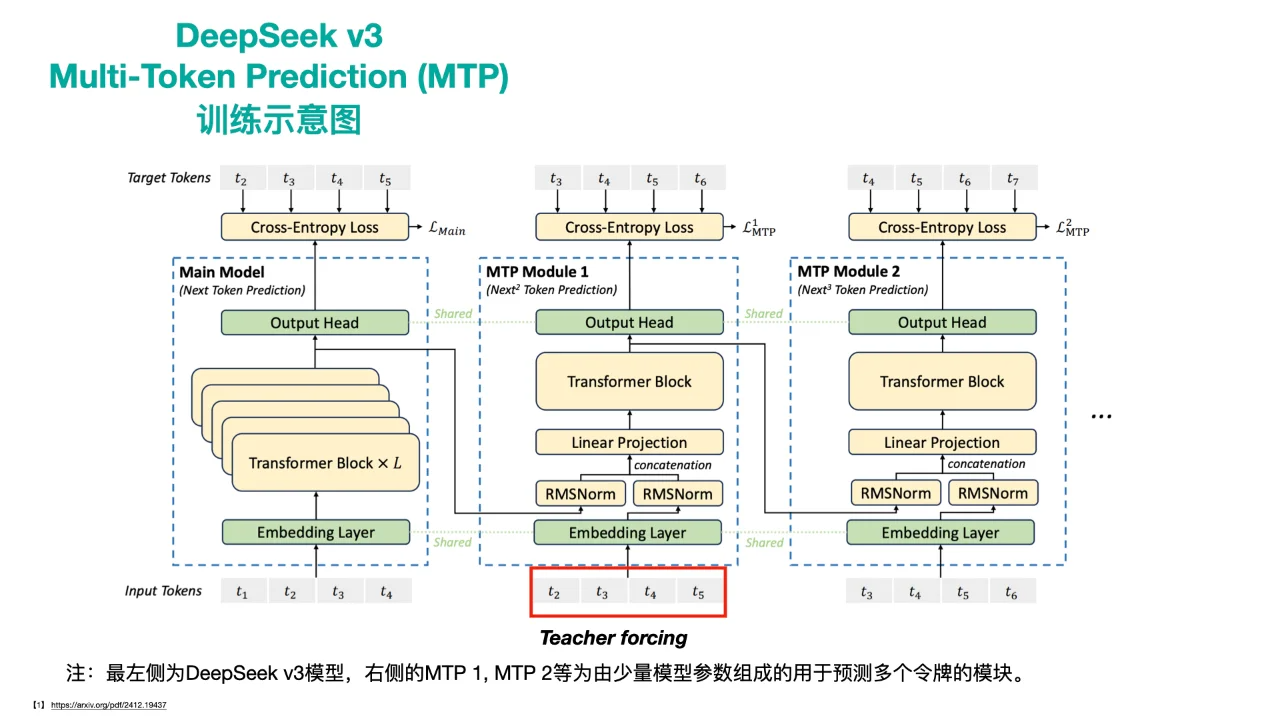
(2)MTP + 投机解码 = 极速 AI 体验!
训练阶段(图三): 仍然保持自回归的生成方式,确保生成序列的正确性。同时采用 Teacher-Forcing 进行学习,增强模型对多 token 预测的能力。
DeepSeek V3 在主模型的最后一层增加了一个 MTP 模块,仅由一个 Transformer Block 组成。
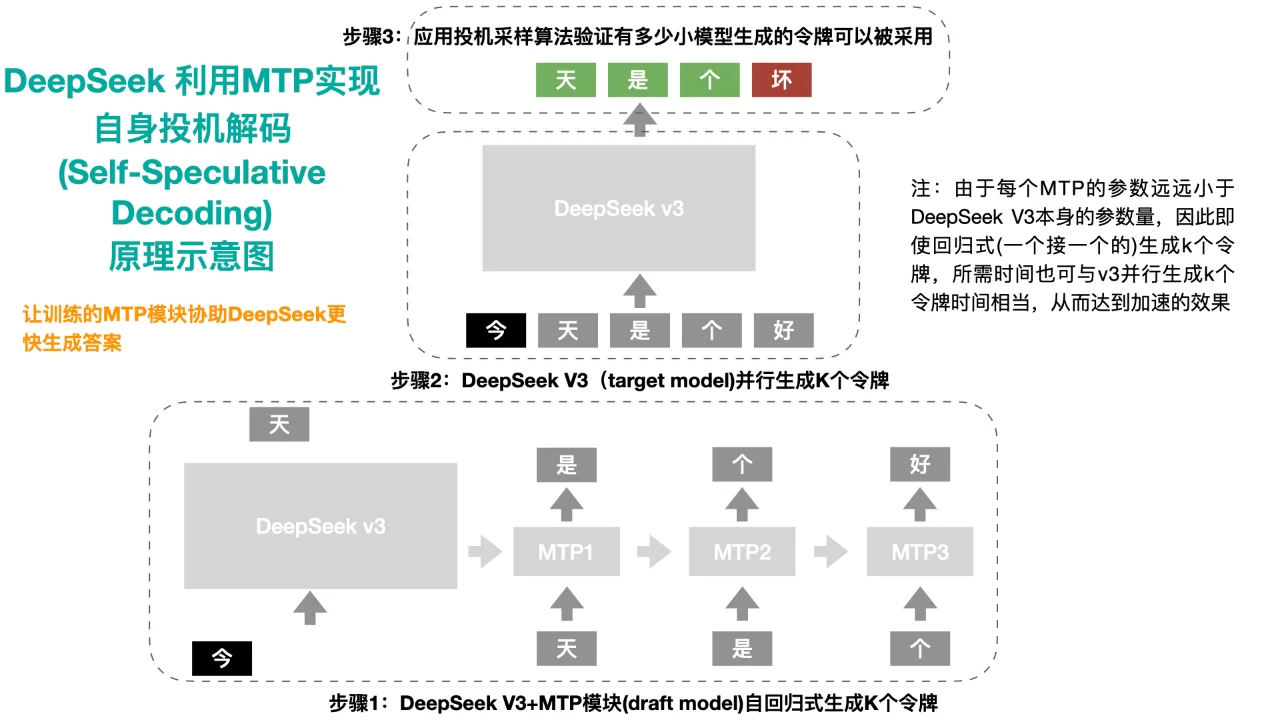
(3)推理阶段(下图):采用了Self-Speculative Decoding的思路,让一个模型,两种用途。首先,使用 DeepSeek V3 + MTP 作为 Draft Model 生成多个 token。由于 MTP 模块仅由一个 Transformer Block 组成,比主模型轻量级,因此生成速度远超直接调用主模型🔥。然后,将生成的 token 传入主模型进行验证,确保文本质量。
三、Infra架构
计算集群架构
DeepSeek-V3 的训练环境是一个配备 2048 个 NVIDIA H800 GPU 的大规模计算集群。
该集群中的每个计算节点包含 8 个 GPU,这些 GPU 通过节点内的 NVLink 和 NVSwitch 实现高速互连。节点之间则采用 InfiniBand (IB) 技术进行高效通信。
训练框架设计
模型训练基于自主研发的 HAI-LLM 框架, 这是一个经过优化的高效轻量级训练系统。DeepSeek-V3 的并行策略包含三个层面:16 路流水线并行(Pipeline Parallelism, PP)、跨 8 个节点的 64 路专家并行(Expert Parallelism, EP),以及 ZeRO-1 数据并行(Data Parallelism, DP)。
为实现高效训练,该框架进行了多方面的工程优化:
1.开发了DualPipe 流水线并行算法,相比现有 PP 方法,该算法显著减少了流水线停滞现象。更重要的是,它实现了前向和后向过程中计算与通信阶段的重叠,有效解决了跨节点专家并行带来的通信负载问题。
2.优化了跨节点全对全通信内核,充分利用 IB 和 NVLink 带宽,同时减少了通信所需的流式多处理器(SMs)资源占用。
3.通过精细的内存管理优化,使得模型训练无需依赖开销较大的张量并行(Tensor Parallelism, TP)技术。
在已有低精度训练技术的基础上,设计了专门的 FP8 训练混合精度框架。在这一框架中,大部分计算密集型操作采用 FP8 执行,而关键操作则保持原有数据格式,以实现训练效率和数值稳定性的最优平衡。

四、训练方法
1、pre-training
数据构建
相比 DeepSeek-V2,本次预训练语料库在提升数学和编程样本占比的同时,扩大了英语和中文之外的多语言覆盖范围。
数据处理流程也经过改进,在保持语料多样性的同时降低了数据冗余。系统采用文档打包方法维持数据完整性,但训练过程中不使用跨样本注意力掩码。最终训练语料库包含 14.8T 经 tokenizer 处理的高质量多样化 token。
在 DeepSeekCoder-V2 的训练中发现,填充中间(FIM) 策略在保持下一个 token 预测能力的同时,还能让模型基于上下文准确预测中间文本。因此 DeepSeek-V3 的预训练也采用了这一策略。具体实现上,使用前缀-后缀-中间(PSM) 框架构建如下数据结构:
<|fim_begin|> pre<|fim_hole|> suf<|fim_end|> middle<|eos_token|>。
该结构在预打包阶段应用于文档级别,FIM 策略的应用比率为 0.1,与 PSM 框架保持一致。
DeepSeek-V3 采用词表大小为 128K 的字节级 BPE tokenizer 。为提高多语言压缩效率,对预分词器和训练数据进行了相应调整。与 DeepSeek-V2 相比,新的预分词器引入了标点符号和换行符的组合 token。然而这种设计在处理无终端换行符的多行提示词时可能产生 token 边界偏差,尤其是在少样本评估场景。为此,训练时对一定比例的组合 token 进行随机分割,使模型接触更多特殊情况来减轻这种偏差。
模型参数细节
系统采用 61 层 Transformer 结构,隐藏维度为 7168 。所有可学习参数采用标准差 0.006 的随机初始化。
在 MLA 结构中,注意力头数量 n h n_h nh 设为 128 ,每个头的维度 d h d_h dh 为 128 。 KV 压缩维度 d c d_c dc为 512 ,查询压缩维度 d c ′ d_c^{\prime} dc′ 为 1536 。解耦的查询和键部分,每个头的维度 d h R d_h^R dhR 设为 64 。
除前三层外,所有 FFN 层都替换为 MoE 层,每个 MoE 层配置1 个共享专家和 256 个路由专家,专家的中间隐藏维度为 2048 。
在路由专家中,每个 token 激活 8 个专家,且最多分配到 4 个节点。多 token 预测深度 D 设为 1 ,即每个 token 除预测下一个精确 token 外,还需预测一个额外 token。
与 DeepSeek-V2 类似,DeepSeek-V3 在压缩潜在向量后添加了 RMSNorm 层,并在宽度瓶颈处引入额外缩放因子。在此配置下,模型总参数量达到 671 B ,其中每个 token 激活 37 B 37 B 37B 参数。
超参数设置
模型采用 AdamW 优化器,参数设置为: β 1 = 0.9 , β 2 = 0.95 \beta_1=0.9, \beta_2=0.95 β1=0.9,β2=0.95 ,权重衰减为 0.1 。预训练阶段最大序列长度为 4 K ,在 14.8 T token 上进行训练。
学习率调度采用以下策略:首先在前 2 K 步内从 0 线性增加至
2.2
×
1
0
−
4
2.2 \times 10^{-4}
2.2×10−4 ;保持该学习率直至处理完 10T 训练 token;随后在 4.3T token 区间内按余弦衰减曲线降至
2.2
×
1
0
−
5
2.2 \times 10^{-5}
2.2×10−5
。在最后 500 B token 的训练中,先用
2.2
×
1
0
−
5
2.2 \times 10^{-5}
2.2×10−5 的固定学习率训练 333 B token,再以
7.3
×
1
0
−
6
7.3 \times 10^{-6}
7.3×10−6 的学习率完成剩余
167
B
167 B
167B token。
梯度裁剪范数设为 1.0 。批量大小采用动态调整策略,在前 469B token 训练过程中从 3072 逐步增加至 15360 ,此后保持不变。模型采用流水线并行将不同层分配到不同 GPU,每层的路由专家均匀分布在 8 个节点的 64 个 GPU 上。节点限制路由中,每个 token 最多分配至 4 个节点( M = 4 M=4 M=4 )。
在无辅助损失负载均衡方面,前 14.3 T 14.3 T 14.3T token 的偏置更新速度 γ \gamma γ 设为 0.001 ,剩余 500 B token 设为 0 。平衡损失参数 α \alpha α 设为 0.0001 ,仅用于防止单个序列内出现极端不平衡。 MTP 损失权重 λ \lambda λ 在前 10T token 中为 0.3 ,剩余 4.8 T 4.8 T 4.8T token 中降至 0.1 。
长上下文扩展
DeepSeek-V3 采用与 DeepSeek-V2 相似的方法实现长上下文处理能力。预训练完成后,系统使用 YaRN 进行上下文扩展,通过两个各包含 1000 步的额外训练阶段,将上下文窗口从 4 K 依次扩展至 32 K 和 128 K 。系统沿用了 DeepSeek-V2 的 YaRN 配置,仅将其应用于解耦的共享键 k t R k_t^R ktR 。两个阶段采用相同的超参数设置:尺度 s = 40 , α = 1 \mathrm{s}=40, ~ \alpha=1 s=40, α=1 , β = 32 \beta=32 β=32 ,缩放因子 t = 0.1 ln s + 1 \sqrt{t}=0.1 \ln s+1 t=0.1lns+1 。
第一阶段将序列长度设为 32 K ,批量大小为 1920 。第二阶段将序列长度提升至 128 K ,相应地将批量大小调整为 480 。两个阶段均采用与预训练末期相同的学习率 7.3 × 1 0 − 6 7.3 \times 10^{-6} 7.3×10−6 。
经过这两阶段的扩展训练,DeepSeek-V3 成功实现了对最长 128 K 输入序列的高效处理。如图8所示,在完成监督微调后,模型在"大海捞针"(NIAH)测试中表现出色,在整个 128 K 的上下文范围内均保持稳定的性能表现。

2、post training
研究构建了包含 150 万个多领域实例的指令调优数据集,针对不同领域特点采用了相应的数据创建方法。
推理数据处理:在数学、代码竞赛和逻辑谜题等推理类任务中,系统采用内部 DeepSeek-R1 模型生成数据。虽然 R1 生成的数据具有较高的准确性,但同时存在推理冗长、格式不规范和输出过长等问题。因此,研究的核心目标是在保持 R1 模型高准确性的同时,实现输出的清晰简洁。
具体实施方法如下:首先针对特定领域(如代码、数学或通用推理)开发专家模型,采用 SFT 和 RL 相结合的训练流程。该专家模型随后作为最终模型的数据生成器。
对每个训练实例,系统生成两类 SFT 样本:一类是问题与原始答案的直接配对,另一类则引入系统提示词,将其与问题和 R1 答案组合。系统提示经过优化设计,包含了引导模型生成具有自我反思和验证机制响应的指令。
在RL阶段,模型通过高温采样生成响应,即使在没有明确系统提示的情况下,也能有效融合 R1 生成数据和原始数据的特征。经过数百轮RL迭代,中间模型成功整合了 R1 的响应模式,显著提升了整体性能。随后,研究采用拒绝采样方法,利用专家模型作为数据源,为最终模型筛选高质量的 SFT 数据。这种方法既保持了 DeepSeek-R1 的高准确性,又确保了输出的简洁性和有效性。
非推理数据处理:对于创意写作、角色扮演和基础问答等非推理任务,系统利用 DeepSeek-V2.5 生成响应,并通过人工标注确保数据质量。
SFT 训练配置:研究对 DeepSeek-V3-Base 进行了两轮 SFT 数据集训练,采用余弦衰减的学习率调度策略,初始学习率为 5 × 1 0 − 6 5 \times 10^{-6} 5×10−6 ,逐步降低至 1 × 1 0 − 6 1 \times 10^{-6} 1×10−6。训练过程中采用多样本序列打包技术,同时通过样本掩码机制确保各样本间的独立性。
3、RL
在强化学习过程中,系统同时采用规则型和模型型两种奖励模型(Reward Model, RM)。
规则型奖励模型:对于可通过明确规则验证的任务,系统采用规则型奖励机制进行反馈评估。例如,在处理具有确定性答案的数学问题时,要求模型在特定格式(如方框内)给出最终答案,从而可以通过规则进行自动验证。同样,在处理 LeetCode 编程题时,系统可通过编译器执行测试用例生成客观反馈。这种基于规则的验证方法具有较高的可靠性,能有效防止模型的投机行为。
模型型奖励模型:对于具有标准答案但形式灵活的问题,系统使用奖励模型评估输出与标准答案的匹配程度。而对于创意写作等缺乏标准答案的任务,奖励模型则基于问题和回答的整体性给出评估反馈。该奖励模型基于 DeepSeek-V3 的 SFT checkpoint 进行训练。为增强模型可靠性,系统构建的偏好数据不仅包含最终评分,还包含推导评分的完整推理过程,这种设计有效降低了特定任务中的奖励扭曲风险。
群组相对策略优化(Group Relative Policy Optimization, GRPO)
v3采用与 DeepSeek-V2 相似的GRPO方法。这种方法不需要与策略模型规模相当的评论家模型,而是通过群组评分估计基线。具体实现中,对每个问题 q,GRPO 从原策略模
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ old ( O ∣ q ) ] 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q ) π θ odd ( o i ∣ q ) A i , clip ( π θ ( o i ∣ q ) π θ o l d ( o i ∣ q ) , 1 − ε , 1 + ε ) A i ) − β D K L ( π θ ∣ ∣ π r e f ) ) , D K L ( π θ ∣ ∣ π r e f ) = π r e f ( o i ∣ q ) π θ ( o i ∣ q ) − log π r e f ( o i ∣ q ) π θ ( o i ∣ q ) − 1 , \begin{gathered} \mathcal{J}_{G R P O}(\theta)=\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{\text {old }}}(O \mid q)\right] \\ \frac{1}{G} \sum_{i=1}^G\left(\min \left(\frac{\pi_\theta\left(o_i \mid q\right)}{\pi_{\theta_{\text {odd }}}\left(o_i \mid q\right)} A_i, \operatorname{clip}\left(\frac{\pi_\theta\left(o_i \mid q\right)}{\pi_{\theta_{o l d}}\left(o_i \mid q\right)}, 1-\varepsilon, 1+\varepsilon\right) A_i\right)-\beta \mathbb{D}_{K L}\left(\pi_\theta| | \pi_{r e f}\right)\right), \\ \mathbb{D}_{K L}\left(\pi_\theta| | \pi_{r e f}\right)=\frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-\log \frac{\pi_{r e f}\left(o_i \mid q\right)}{\pi_\theta\left(o_i \mid q\right)}-1, \end{gathered} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold (O∣q)]G1i=1∑G(min(πθodd (oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),DKL(πθ∣∣πref)=πθ(oi∣q)πref(oi∣q)−logπθ(oi∣q)πref(oi∣q)−1,
其中 ε \varepsilon ε 和 β \beta β 表示超参数; π r e f \pi_{r e f} πref 代表参考模型; A i A_i Ai 表示优势函数,其计算基于每组内输出所对应的奖励序列 r 1 , r 2 , … , r G r_1, r_2, \ldots, r_G r1,r2,…,rG 。
A i = r i − mean ( { r 1 , r 2 , ⋯ , r G } ) std ( { r 1 , r 2 , ⋯ , r G } ) A_i=\frac{r_i-\operatorname{mean}\left(\left\{r_1, r_2, \cdots, r_G\right\}\right)}{\operatorname{std}\left(\left\{r_1, r_2, \cdots, r_G\right\}\right)} Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG})
在 RL过程中,v3融合了编程,数学,写作,角色扮演和问答等多领域的提示词任务。这种多样化的训练策略不仅提高了模型对人类偏好的适应性,还在基准测试中取得了显著提升,特别是在监督微调数据有限的场景下表现出色。
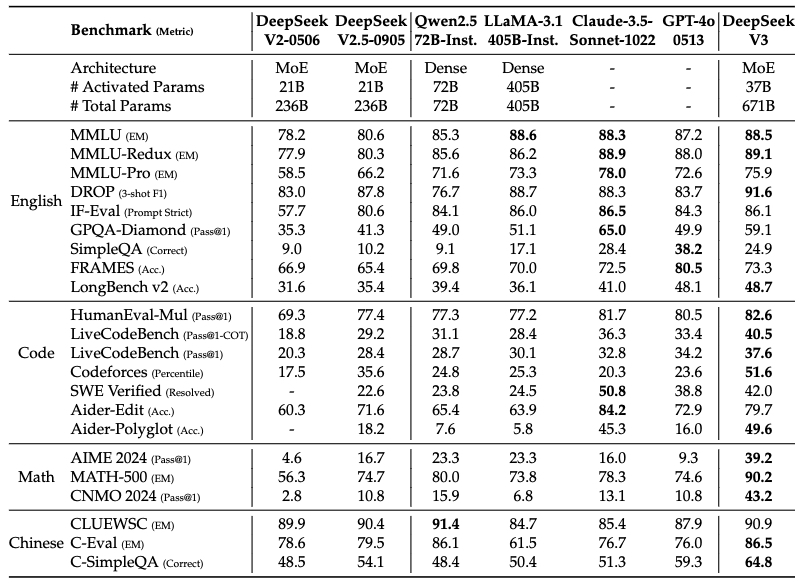
五、评估结果
六、MiniMax-01 与 DeepSeek-V3 对比
MiniMax-01 和 DeepSeek-V3 都是致力于突破现有 LLM 性能瓶颈的创新模型,各有侧重:
- MiniMax-01 更注重长上下文处理能力,其线性注意力机制和混合架构使其在处理超长序列时更具优势。
- DeepSeek-V3 则在保持高效训练和推理的同时,在数学和编码任务上表现出色,并且在长上下文理解方面也展现出强大的能力。
两者都采用了 MoE 架构和先进的训练策略,在提升模型性能的同时,也考虑了训练成本和效率。未来,随着硬件和算法的不断发展,MiniMax-01 和 DeepSeek-V3 都有望在各自的领域取得更大的突破,推动 LLM 的发展。
| 方面 | MiniMax-01 | DeepSeek-V3 |
|---|---|---|
| 模型架构 | 基于线性注意力机制,采用混合架构(Hybrid-Lightning),并集成了MoE架构。 | 基于Transformer架构,采用MLA和DeepSeekMc,并引入了辅助损失无关的负载均衡策略。 |
| 参数规模 | 4560亿总参数,459亿激活参数。 | 6710亿总参数,370亿激活参数。 |
| 训练数据 | 14.8万亿token,涵盖学术文献、书籍、网络内容和编程代码等。 | 14.8万亿token,涵盖高质量、多样化的文本数据,并优化了数学和编程样本的比例。 |
| 训练策略 | 采用三阶段训练方法,将上下文窗口扩展到100万token,并最终外推到400万token。 | 采用两阶段上下文扩展训练,将上下文窗口从4K扩展到最大16K。 |
| 训练成本 | 未明确说明,但强调其训练效率高。 | 278.8万个H800 GPU小时,总成本约为557.6万美元。 |
| 多模态能力 | MiniMax-VL-01通过集成图像编码器和图像适配器,扩展了模型的多模态理解能力。 | 未提及多模态能力。 |
| 性能表现 | 在长上下文处理方面表现出色,在Ruler和LongBench-V2等长上下文基准测试中表现优异。 | 在大多数基准测试中表现优异尤其是在数学和编码任务上DeepSeek-V3也展现出强大的能力,例如在FRAMES和LongBench v2上 |
| 优势 | - 线性注意力机制和混合架构使其在处理超长上下文时更具优势。 - MoE架构和全局路由策略提高了训练效率。 - 变长环注意力和改进的LASP算法进一步提升了长上下文处理能力。 | - MLA和DeepSeekMoE架构在保证高效训练和推理的同时,实现了强大的性能。 - 辅助损失无关的负载均衡策略和多token预测训练模型性能。 - FP8混合精度训练框架降低了训练成本。 |
| 局限性 | - 混合架构中仍保留部分softmax注意力层。可能影响长上下文处理效率。 - 复杂编程任务的性能有待提升。 - 缺乏对长上下文检索和推理能力的更深入评估。 | - 推荐的部署单元较大,可能对小型团队造成负担。 - 推理速度仍有提升空间。 |
Reference
[1] DeepSeek-V3技术报告解读
[2] DeepSeek V3 详细解读:模型&Infra 建设
[3] 深挖DeepSeek的MTP为何秒提响应速度-贝贝和乖乖爸爸


















 6411
6411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











