









note
文章目录
一、Janus-Pro:解耦视觉编码,实现多模态高效统一
论文标题:Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
论文地址:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf
7B 版本:https://huggingface.co/deepseek-ai/Janus-Pro-7B
1B 版本:https://huggingface.co/deepseek-ai/Janus-Pro-1B
Hugging Face 试用链接:https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
和之前版本的区别
Janus 的前一个版本采用了三阶段训练过程:
- 阶段 I:重点训练适配器和图像头。
- 阶段 II:进行统一预训练。在此过程中,除理解编码器和生成编码器外,所有组件的参数都会被更新。
- 阶段 III:进行监督微调。在阶段 II 的基础上,进一步解锁理解编码器的参数。
然而,这种训练策略存在一些问题。通过进一步的实验,DeepSeek 研究团队发现这一策略并不最优,并导致了显著的计算效率低下。为解决此问题,他们在原有基础上进行了两项修改:
- 在阶段 I 延长训练时间:研究者增加了阶段 I 的训练步数,以确保在 ImageNet 数据集上得到充分的训练。他们经过研究发现,即使固定了大语言模型(LLM)的参数,该模型仍能有效地建模像素间的依赖关系,并根据类别名称生成合理的图像。
- 在阶段 II 进行重点训练:在阶段 II 中,研究者去除了 ImageNet 数据,直接使用标准的文本生成图像数据来训练模型,从而使模型能够基于详细的描述生成图像。这种重新设计的方法使得阶段 II 能够更高效地利用文本生成图像的数据,并显著提高了训练效率和整体性能。
Janus-Pro是一个新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码分离为“理解”和“生成”两条路径,同时仍采用单一的Transformer架构进行处理,解决了以往方法的局限性。这种分离不仅缓解了视觉编码器在理解和生成中的角色冲突,还提升了框架的灵活性。
技术亮点
- 视觉编码解耦:采用独立的路径分别处理多模态理解与生成任务,有效解决视觉编码器在两种任务中的功能冲突。
- 统一 Transformer 架构:使用单一的 Transformer 架构处理多模态任务,既简化了模型设计,又提升了扩展能力。
- 高性能表现
- 多模态理解:模型性能匹配甚至超越任务专用模型。
- 图像生成:高质量图像生成能力,适配 384x384 分辨率,满足多场景需求。

模型细节
- 视觉编码器:采用 SigLIP-L[1],支持 384x384 分辨率输入,捕捉图像细节。
- 生成模块:使用 LlamaGen Tokenizer[2],下采样率为 16,生成更精细的图像。
- 基础架构:基于 DeepSeek-LLM-1.5b-base 和 DeepSeek-LLM-7b-base 打造。
数据扩展
研究团队在 Janus 的训练数据上进行了扩展,涵盖了多模态理解和视觉生成两个方面:
- 多模态理解:对于阶段 II 的预训练数据,参考 DeepSeek-VL2 ,并增加了大约 9000 万条样本。样本包括图像标注数据集,以及表格、图表和文档理解的数据。
- 视觉生成:前一个版本的 Janus 使用的真实世界数据质量较差,且包含大量噪声,导致文本生成图像时不稳定,生成的图像质量较差。在 Janus-Pro 中,研究者加入了大约 7200 万条合成的美学数据样本,在统一预训练阶段,真实数据和合成数据的比例为 1:1。
模型训练参数对比

二、JanusFlow-1.3B:融合生成流与语言模型,重新定义多模态
论文标题:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
论文地址:https://arxiv.org/pdf/2411.07975
技术亮点
- 架构简约且创新:无需复杂改造,直接将生成流融入大语言模型框架,简化了多模态建模流程。
- 图像生成能力优越:结合 Rectified Flow 与 SDXL-VAE[3],实现高质量 384x384 图像生成,广泛适配不同应用场景。
- 高灵活性与可扩展性:支持多任务扩展,成为统一多模态框架的优秀选择。
模型细节
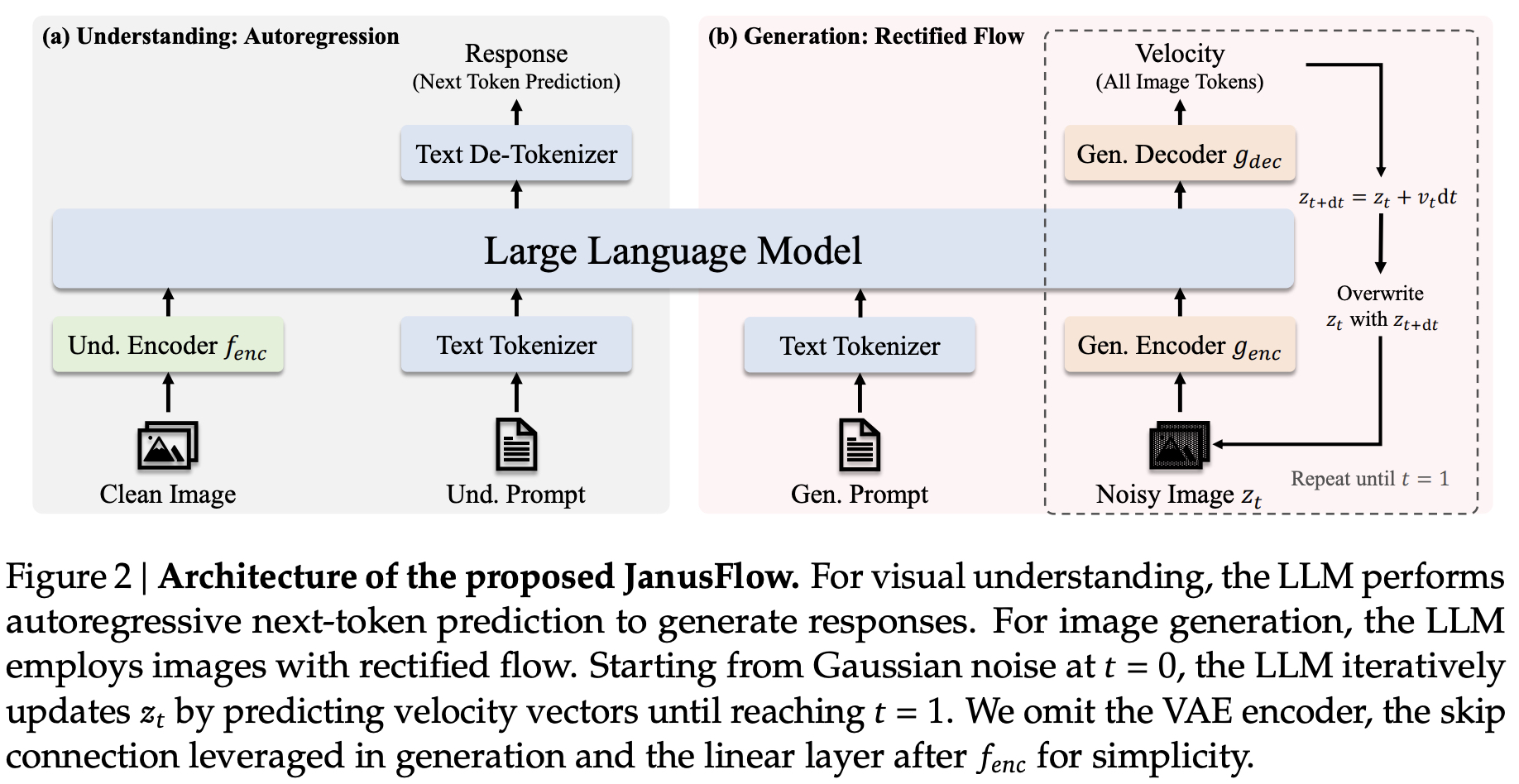
- 视觉编码器:同样采用 SigLIP-L[4],确保图像细节捕捉能力。
- 生成模块:基于 Rectified Flow 与 SDXL-VAE,生成精细度更高的图像。
- 基础架构:构建于 DeepSeek-LLM-1.3b-base,结合预训练与监督微调后的 EMA 检查点,性能表现卓越。
Reference
[1] SigLIP-L: https://huggingface.co/timm/ViT-L-16-SigLIP-384
[2] LlamaGen Tokenizer: https://github.com/FoundationVision/LlamaGen
[3] SDXL-VAE: https://huggingface.co/stabilityai/sdxl-vae
[4] SigLIP-L: https://huggingface.co/timm/ViT-L-16-SigLIP-384
[5] Janus-Pro Github 仓库: https://github.com/deepseek-ai/Janus
[6] JanusFlow Github 仓库: https://github.com/deepseek-ai/Janus
[7] MIT License: https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-CODE
[8] DeepSeek 模型协议: https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-MODEL
[9] https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
[10] 实测 | 比较Qwen2.5-VL与Janus-Pro-7B在视觉理解上效果


















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











