









2. NCSN
NCSN提出一种基于分数的生成模型(Score-based Generative Model),正如前文所述,其本质上与扩散模型是等价的,也是从一个随机噪声中,利用朗之万动力学模型,根据对数概率密度函数的梯度(即分数),逐步还原得到一个图像样本。下面我们将具体介绍下该过程。
所谓的生成式模型,都是希望根据大量的数据样本估计得到一个样本的分布模型
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x),进而可以从
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)中随机采样得到任意的样本。但在实际中,估计一个准确的分布模型
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)是非常困难的。因此,作者转变思路,不去预测
p
d
a
t
a
(
x
)
p_{data}(x)
pdata(x)而是去预测对数概率密度函数的梯度
∇
x
log
p
(
x
)
\nabla_x\log{p(x)}
∇xlogp(x),也就是我们所谓的分数(score)。然后,利用朗之万动力学模型,可以从随机分布
π
(
x
)
\pi(x)
π(x)中采样得到的初始样本
x
~
0
∽
π
(
x
)
\tilde{x}_0\backsim \pi(x)
x~0∽π(x),沿着对数概率密度的梯度方向逐步移动
x
~
t
=
x
~
t
−
1
+
ϵ
2
∇
x
log
p
(
x
~
t
−
1
)
+
ϵ
z
t
(2-1)
\tilde{x}_t=\tilde{x}_{t-1}+\frac{\epsilon}{2}\nabla_x\log{p(\tilde{x}_{t-1})}+\sqrt{\epsilon}z_t\tag{2-1}
x~t=x~t−1+2ϵ∇xlogp(x~t−1)+ϵzt(2-1)其中
z
t
∽
N
(
0
,
I
)
z_t\backsim\mathcal{N}(0,I)
zt∽N(0,I),
ϵ
\epsilon
ϵ表示每次移动的步长。当
ϵ
→
0
,
T
→
∞
\epsilon\rightarrow0,T\rightarrow\infty
ϵ→0,T→∞时,
x
~
T
\tilde{x}_T
x~T就近似为目标分布
p
(
x
)
p(x)
p(x)中的一个样本。可以看出来这个过程与DDPM中的采样过程非常类似,只是将估计噪声改成估计分数
∇
x
log
p
(
x
~
t
−
1
)
\nabla_x\log{p(\tilde{x}_{t-1})}
∇xlogp(x~t−1)了。那么现在需要解决的问题就是,如何准确的估计分数
∇
x
log
p
(
x
~
t
−
1
)
\nabla_x\log{p(\tilde{x}_{t-1})}
∇xlogp(x~t−1),这个过程叫做分数匹配(Score-matching)。
原始的分数匹配方法其目标是训练一个模型
s
θ
(
x
)
s_{\theta}(x)
sθ(x),使其与目标分布的对数概率密度梯度之间的L2距离最小化,即
E
p
d
a
t
a
(
x
)
[
∥
s
θ
(
x
)
−
∇
x
log
p
d
a
t
a
(
x
)
∥
2
2
]
(2-2)
\mathbb{E}_{p_{data}(x)}\left [\left \|s_{\theta}(x)-\nabla_x\log{p_{data}(x)}\right \| _2^2\right]\tag{2-2}
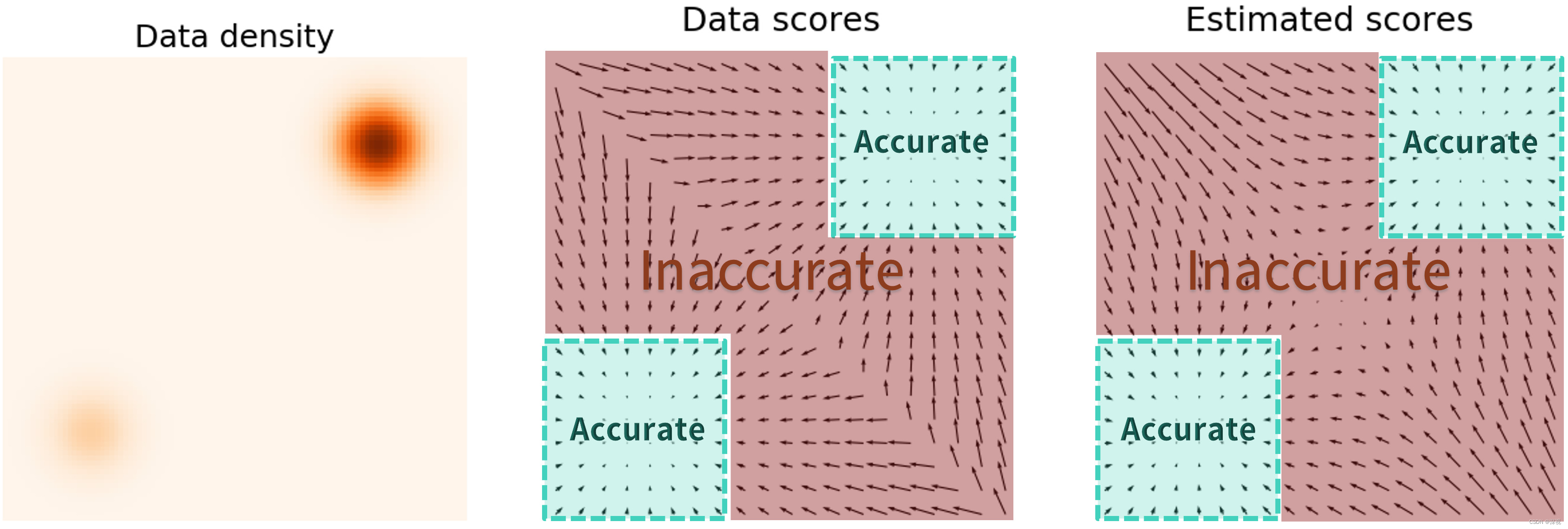
Epdata(x)[∥sθ(x)−∇xlogpdata(x)∥22](2-2)直接求解上式对于高维数据分布而言是十分困难的,现有的求解方法有两种:去噪分数匹配和切片分数匹配。其中切片分数匹配方法得到的结果更加接近原始数据分布的分数,但计算时间较长。而且在分数估计过程中存在一个问题,就是在概率密度较高的位置估计的准确性较高,而在概率密度较低的区域,分数估计的准确性很难保证。如下图所示,图中黑色的小箭头就表示对数密度函数的梯度,只有绿色区域内的估计结果才可靠,而在占据数据分布的绝大部分区域(红色区域)则是不可靠的,这将导致随机采样的初始样本很难移动到目标分布中。(图源:宋飏博士的博客)
去噪分数匹配法通过对原始数据分布增加随机噪声,增加整个分布中的概率密度,使其能够计算得到更加准确的分数。如下图所示,经过扰乱后的数据分布,在整个分布上都能很好的估计分数。但这同时也带来一个新的问题,就是如果增加的噪声太强,将会破坏原始的目标数据分布。因此,需要制定一个更加合理的噪声添加策略,使其既能够保证分数计算的准确性,又能够不干扰最终的目标分布。

作者提出了一种噪声条件分数网络(Noise Conditional Score Networks,NCSN),通过由强到弱给原始分布添加不同程度的噪声
σ
\sigma
σ,并训练一个网络根据输入噪声
σ
\sigma
σ和干扰后的数据
x
~
\tilde{x}
x~,预测分数
s
θ
(
x
~
,
σ
)
s_{\theta}(\tilde{x},\sigma)
sθ(x~,σ),使其逼近干扰后分布的对数概率密度梯度
∇
x
~
log
p
σ
(
x
~
∣
x
)
\nabla_{\tilde{x}}\log{p_{\sigma}(\tilde{x}|x)}
∇x~logpσ(x~∣x)。首先,定义一组随机噪声
{
σ
i
}
i
=
1
L
\{\sigma_i\}_{i=1}^L
{σi}i=1L,
σ
i
>
0
\sigma_i>0
σi>0且随
i
i
i增长成几何倍数下降,直至
σ
L
→
0
\sigma_L\rightarrow0
σL→0。使用这组随机噪声扰乱原始数据分布,得到
q
σ
(
x
)
:
=
∫
p
d
a
t
a
(
t
)
N
(
x
∣
t
,
σ
2
I
)
d
t
q_{\sigma}(x):=\int p_{data}(t)\mathcal{N}(x|t,\sigma^2I)dt
qσ(x):=∫pdata(t)N(x∣t,σ2I)dt。然后,设计一个噪声条件分数网络
s
θ
(
x
,
σ
)
s_{\theta}(x,\sigma)
sθ(x,σ),其采用带有注意力机制的UNet结构,并将噪声
σ
\sigma
σ通过条件实例规范化(conditional instance normalization)引入到网络中。给定一个噪声
σ
\sigma
σ,可以得到一个干扰后的分布
q
σ
(
x
~
∣
x
)
=
N
(
x
~
∣
x
,
σ
2
I
)
q_{\sigma}(\tilde{x}|x)=\mathcal{N}(\tilde{x}|x,\sigma^2I)
qσ(x~∣x)=N(x~∣x,σ2I),其对数梯度为
∇
x
~
log
p
σ
(
x
~
∣
x
)
=
−
x
~
−
x
σ
2
\nabla_{\tilde{x}}\log{p_{\sigma}(\tilde{x}|x)}=-\frac{\tilde{x}-x}{\sigma^2}
∇x~logpσ(x~∣x)=−σ2x~−x,将其代入目标函数(2-2)中可得
l
(
θ
;
σ
)
:
=
1
2
E
p
d
a
t
a
(
x
)
E
x
~
∽
N
(
x
~
∣
x
,
σ
2
I
)
[
∥
s
θ
(
x
~
,
σ
)
+
x
~
−
x
σ
2
∥
2
2
]
(2-3)
\mathscr{l}(\theta;\sigma):=\frac{1}{2}\mathbb{E}_{p_{data}(x)}\mathbb{E}_{\tilde{x}\backsim\mathcal{N}(\tilde{x}|x,\sigma^2I)}\left [\left \|s_{\theta}(\tilde{x},\sigma)+\frac{\tilde{x}-x}{\sigma^2 }\right \|^2_2\right]\tag{2-3}
l(θ;σ):=21Epdata(x)Ex~∽N(x~∣x,σ2I)[
sθ(x~,σ)+σ2x~−x
22](2-3)对于所有的噪声
σ
∈
{
σ
i
}
i
=
1
L
\sigma\in\{\sigma_i\}_{i=1}^L
σ∈{σi}i=1L可以得到一个统一的目标函数
L
(
θ
;
{
σ
i
}
i
=
1
L
)
:
=
1
L
∑
i
=
1
L
λ
(
σ
i
)
l
(
θ
;
σ
i
)
(2-4)
\mathcal{L}(\theta;\{\sigma_i\}_{i=1}^L):=\frac{1}{L}\sum^{L}_{i=1}\lambda(\sigma_i)\mathscr{l}(\theta;\sigma_i)\tag{2-4}
L(θ;{σi}i=1L):=L1i=1∑Lλ(σi)l(θ;σi)(2-4)其中
λ
(
σ
i
)
=
σ
i
2
\lambda(\sigma_i)=\sigma_i^2
λ(σi)=σi2。完成NCSN模型的训练后,作者提出一种退火朗之万动力学模型来生成样本,与原始的朗之万动力学模型相比,作者将固定的步长
ϵ
\epsilon
ϵ改为了随着移动步数逐渐减小的可变步长
α
i
\alpha_i
αi,且用NCSN模型估计的分数取代了对数概率密度梯度,如下式所示
x
~
t
=
x
~
t
−
1
+
α
i
2
s
θ
(
x
~
t
−
1
,
σ
i
)
+
α
i
z
t
(2-5)
\tilde{x}_t=\tilde{x}_{t-1}+\frac{\alpha_i}{2}s_{\theta}(\tilde{x}_{t-1},\sigma_i)+\sqrt{\alpha_i}z_t\tag{2-5}
x~t=x~t−1+2αisθ(x~t−1,σi)+αizt(2-5)其中
α
i
=
ϵ
⋅
σ
i
2
/
σ
L
2
\alpha_i=\epsilon\cdot{\sigma_i^2}/{\sigma_L^2}
αi=ϵ⋅σi2/σL2,由于
σ
L
≈
0
\sigma_L\approx 0
σL≈0,所以在开始阶段步长
α
i
\alpha_i
αi较大,而且此时的噪声
σ
i
\sigma_i
σi也比较大,因此可以较为准确的估计分数,快速地从随机分布区域移动到目标分布区域内。随着步数的增加,噪声也越来越小,以减少对目标分布的干扰,且每次移动的步长也越来越小,最终得到一个目标分布内的样本
x
~
T
\tilde{x}_T
x~T。具体的算法流程如下图所示

可以看到算法中有两个循环嵌套,这是表示一共有
L
L
L个噪声级别,对应
L
L
L个步长,在每个步长条件下会移动
T
T
T步。回顾整个过程我们可以感受到,他与DDPM有非常多的相似之处(NCSN是更早发表的,只不过没有使用扩散模型来描述)。使用不同级别的噪声对原始分布进行干扰对应了DDPM中的扩散过程,训练一个NCSN模型来估计分数对应了DDPM中的噪声估计网络,使用退火朗之万动力学模型来生成目标分布内的样本对应了DDPM的采样过程。在下一篇文章中,我们将证明二者是等价的,而且可以用统一的形式来表示。


















 9468
9468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











