







问题
在数据中心中,内存资源通常存在低利用率和缺乏动态性的问题。内存分离通过解耦CPU和内存来解决这些问题,目前的方法包括基于RDMA或Compute Express Link(CXL)等互连协议。然而,基于RDMA的方法涉及代码重构和更高的延迟。基于CXL的方法支持本机内存语义,克服了RDMA的缺点,但在机架级别内受到限制。此外,基于CXL产品的内存池和共享目前仍在早期探索阶段,未来还需要时间才能实现。
背景
分离式内存是为了缓解内存利用率低,其主要原因为:内存分配和内存搁浅。内存分配指应用申请内存后,没有使用的部分。内存搁浅指当服务器的所有CPU核心都分给虚拟机时,仍有部分内存没有分配,并且将长期无法使用。
构建分离式内存通常有两种方式:第一,构建分布式内存系统,通过在单个服务器上运行的分布式应用程序提供全局内存管理[6-10]。通常提供细粒度的内存共享。第二,使用由原始内存设备组成的内存池[11-13]。内存池可以为各个计算节点(CN)提供扩展内存,CN彼此独立,通常不共享数据。
现有方法局限性
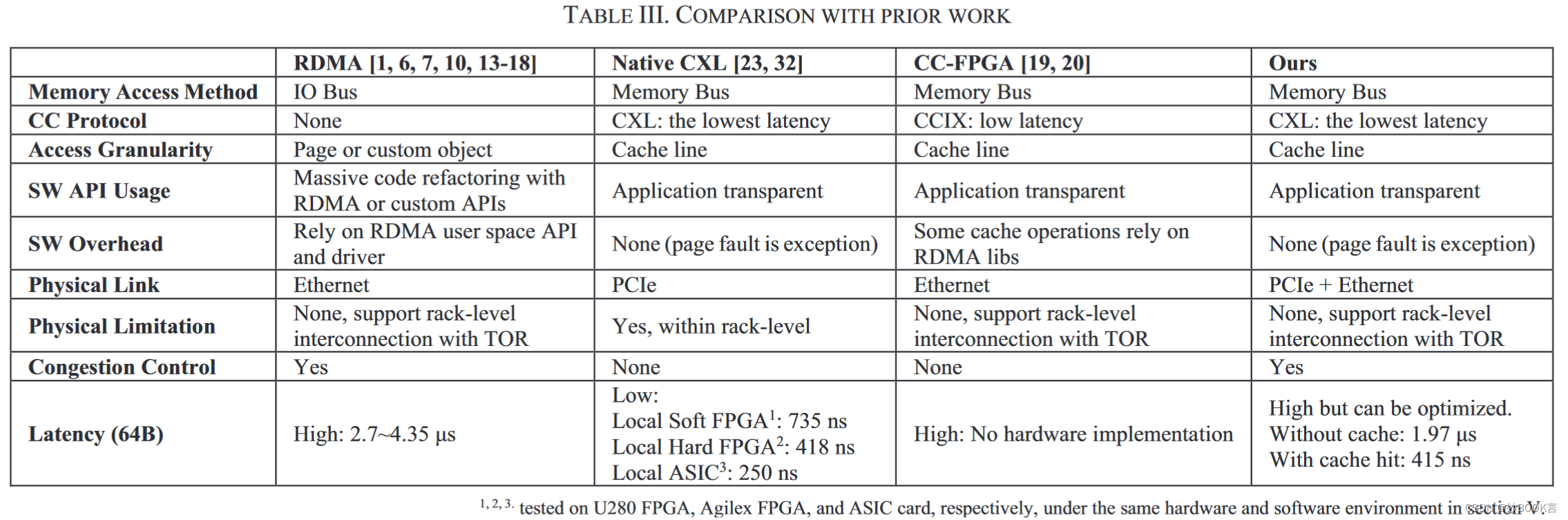
内存分离系统根据从计算节点(CN)到内存节点(MN)的物理传输方式,分为基于RDMA的[1, 6, 7, 10, 13-18]和基于缓存一致性的CXL等互连协议的系统[19-23]。
基于RDMA的系统继承了RDMA的缺点[24],即不本地支持内存语义,应用程序需要显式调用相关的API[25],并在运行时管理内存区域和队列对[26]。RDMA方法需要RDMA网络接口卡(RNIC)驱动程序,用来执行内存区域与物理内存之间的地址转换,以及内存与网络接口卡之间的DMA复制,这会增加延迟和中断开销。与使用本机内存语义相比,RDMA内存访问增加了侵入式代码修改和系统调用开销,从而增加了延迟。根据CN和MN之间的数据交换粒度,基于RDMA的设计可以进一步分为基于页面的[1, 14-16]或基于对象的[6, 7, 10, 13, 17, 18]。基于页面的系统涉及额外的页面故障和读/写数据放大。基于对象的系统需要定制API,牺牲了透明度。
基于缓存一致性的互连协议(例如CXL)、支持内存语义的系统,克服了RDMA的缺点。通常使用支持缓存一致性协议,并支持CPU和FPGA之间内存共享的接口,可以连接到CPU的CC-FPGAs(缓存一致性FPGAs)实现。已经提出了各种平台,例如IBM的OpenCAPI [27],AMD/ARM的CCIX [28],Intel的CXL [29]。通过这些协议,CPU可以使用加载/存储语义访问连接到FPGA的内存,它们之间的数据通信以缓存行为粒度,访问延迟类似于NUMA节点,并且应用程序无需进行代码更改。然而,即使是最新的CXL 3.0规范,这种方法在机架级别内受到限制,而RDMA可以在跨机架的服务器之间访问内存。一些研究[19, 20]尝试扩展互连协议的距离,但它们仍然需要额外的RDMA操作。
本文方法
现有的内存分离系统无法在低延迟、细粒度内存管理、可扩展性和应用透明性等方面达到全面的要求。我们提出了CXL over Ethernet的方法。
-
使用支持CXL的CC-FPGA,并充分利用CXL支持的内存语义来访问远程内存,就像访问NUMA节点一样,从而避免了与RDMA相关的增加的延迟和系统开销。我们的方法对应用程序透明,不需要额外的驱动程序,并实现了缓存行粒度的数据交换。
-
考虑到可扩展性,我们使用以太网传输CXL远程内存访问请求,克服了本机CXL受到机架范围限制的缺点。主机发出的CXL内存请求可以直接发送到FPGA,而FPGA通过其网络接口与远程内存进行交互。我们在FPGA上封装以太网帧,这对内核是透明的,不经过传统的网络堆栈,从而避免了使用RDMA方法进行DMA复制和地址转换。
-
还需要考虑带宽和延迟的问题。当前以太网带宽逐渐向800 Gbps甚至1.6 Tbps [30]发展,足以满足传输带宽的需求。主机端的CXL延迟已经小于RDMA。我们在计算节点(CN)端的FPGA上进一步添加缓存以缓存远程内存数据,这降低了使用以太网和网络路径的延迟频率。我们设计了一个与交换机无关的拥塞控制算法,以减少由于网络拥塞导致的延迟增加。
我们使用一台服务器和两块带有100 Gbps网络的FPGA板对我们的方法进行了原型设计,并测量了内存访问延迟。评估结果显示,服务器访问远程内存的平均延迟为1.97微秒,比行业基准延迟低约37%。当内存访问命中FPGA缓存时,延迟可以降低到415纳秒。
实验
实验环境:由CN和MN(Xilinx U280板)组成,CN FPGA通过PCIe Gen4 x8链路连接到配备Intel Sapphire Rapids CPU的服务器。服务器上运行的操作系统是Fedora,内核版本为5.16.15。MN和CN通过FPGA上的100 Gbps QSFP28端口互连。
实验对比:延迟、传输速度
总结
优化分离式内存的访问。利用CXL和RDMA结合的方法,用CXL支持本机内存加载/存储访问;利用RDMA进行跨机架的访问,并通过封装以太网帧减少DMA复制和地址转换;通过缓存远程内存数据和拥塞控制算法减少延迟。


















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











