







Paper:https://arxiv.org/abs/1801.00881
Code:https://github.com/lingxiao-he/Partial-Person-ReID
前言:这是一篇关于partial行人重识别的方向的论文,收录于2018年的CVPR。全文是基于query是partial图像,而gallery是完整的行人图像。
摘要:Partial行人重识别由于行人图像是局部可见的导致行人匹配具有挑战性。然而对于partial行人重识别的研究也比较少。针对此问题,本文提出了快速、准确的匹配方法。该方法利用全卷积网络(FCN)生成固定大小的空间特征图,保证像素级特征的一致性。为了匹配size不同的两张图像,进一步提出了避免精确对齐的深度空间特征重构(DSR)方法。具体来说,DSR利用当前流行的字典学习模型的重构误差来计算不同空间特征图之间的相似度。由此,期望FCN可以增加相同行人的相似性,减少不同行人的相似性。在partial行人重识别的数据集上结果表明证明了方法的有效性。而且在完整行人重识别上也取得了极具竞争力的结果。
相关工作:滑动窗口匹配(SWM)通过构造一个和query图像size相同的滑动窗口,用它在gallery图像上检索最相似的区域,此方式为partial行人重识别提供了解决思路。然而这样方式需要query图像的size小于gallery图像。更进一步,一些方法采用图像分块的方式来代替以上方法。然后,上述方法耗时较长且需要良好的前景对齐,而且相关区域需要重复的特征提取。
本文提出了一种新颖且快速的partial行人重识别框架可以实现size不同的成对图像的匹配。利用FCN生成一定size的空间特征图,可以将其视为像素级特征矩阵。受启发于字典学习在人脸识别领域的巨大成功,提出了基于深度空间特征重构的端到端模型,可以基于gallery中的图像的空间特征稀疏重构出query图像空间特征图上的每一个像素。基于以上算法,模型不需要严格的图像size一致,自然也避免了对齐的耗时。具体来说,为FCN设计目标函数,使得同一个ID的图像的空间特征图重建误差小于不同ID图像空间特征图的重构误差。

知识点解析:
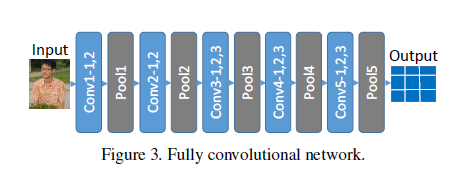
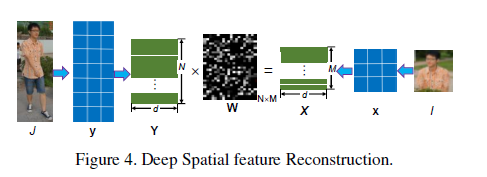
a)FCN:原始的CNN由于全连接层的存在需要特定size的输入,由于partial行人图像有不一的size/scale而无法保证。因此本文将所有的全连接层一出移除而知保留卷积层和池化层,具体结构图如下。
b)Deep Spatial Feature Reconstruction(DSR):主要用来测量不同大小的成对图像的相似性。假设给定一对图像,分别为partial图像
I
I
I和完整图像
J
J
J,经过FCN卷积之后的空间特征图为
x
x
x和
y
y
y,其大小用
w
×
h
×
d
w \times h \times d
w×h×d,将
x
x
x分成
N
N
N个块,
N
=
w
×
h
N = w \times h
N=w×h,因此
x
n
=
1
×
1
×
d
x_n = 1 \times 1 \times d
xn=1×1×d,具体公式如下:
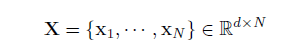
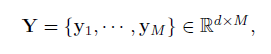
因此,可以将
Y
Y
Y利用线性组合来表示
x
n
x_n
xn,也就是,搜索相似块来重构
x
n
x_n
xn。因此,需求出
x
n
x_n
xn关于
Y
Y
Y的稀疏系数
w
n
w_n
wn,
w
n
=
M
×
1
w_n = M \times 1
wn=M×1。由于重建
x
n
x_n
xn需较少的
Y
Y
Y模块,因此使用
L
1
L_1
L1正则化约束,具体公式如下:
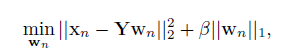
β
\beta
β用来控制编码向量的稀疏性。
∣
∣
x
n
−
Y
w
n
∣
∣
2
2
||x_n - Yw_n||_2^2
∣∣xn−Ywn∣∣22用来表示
x
n
x_n
xn和
Y
Y
Y的相似性,汇总如下:
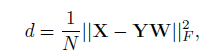
W
W
W表示稀疏系数重构矩阵。以上即为DSR的流程,具体如图和伪代码如下所示:

c)Fine-tuning on Pretrained FCN with DSR:本文采用分类任务来训练FCN,如下图图。为提升模型提取显著特征的能力,使用带有DSR的迁移学习来对卷积层进行更新,如下图。DSR鼓励同一ID的特征映射相似,不同ID的特征映射不同。DSR可以视为验证信号,损失函数定义如下:
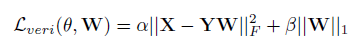
两个特征属于同一ID时
α
=
1
\alpha = 1
α=1,否则
α
=
−
1
\alpha = -1
α=−1。本文采用交替训练来优化参数,1,固定
θ
\theta
θ(FCN),优化
W
W
W(DSR)。
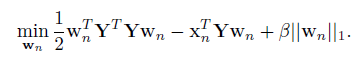
2,固定
w
c
w_c
wc,优化
θ
\theta
θ。
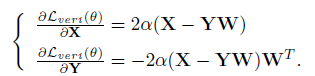
d)Multi-scale Block Representation:提取query图像的尺度无约束特征对于partial行人重识别具有挑战性和重要意义。为了减弱尺度失配的影响,在DSR提出多尺度块表示。

本文具体使用三种尺度块:
1
×
1
1\times 1
1×1,
2
×
2
2\times 2
2×2,
3
×
3
3\times 3
3×3,这些block通过滑动窗口的方式进行提取(stride = 1)。为了保证size一致,通过平均池化将
2
×
2
2\times 2
2×2,
3
×
3
3\times 3
3×3调整为
1
×
1
1\times 1
1×1,多尺度block主要是提升多尺度变化的鲁棒性。与图像级多尺度不同的是,特征级多尺度可以减少计算量和特征共享。
结论:算法实现了当时partial行人重识别的SOTA,而且特征重构可以实现特征共享和减少计算量。但逐步优化的过程总给人不是end-to-end的感觉。















 2045
2045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









