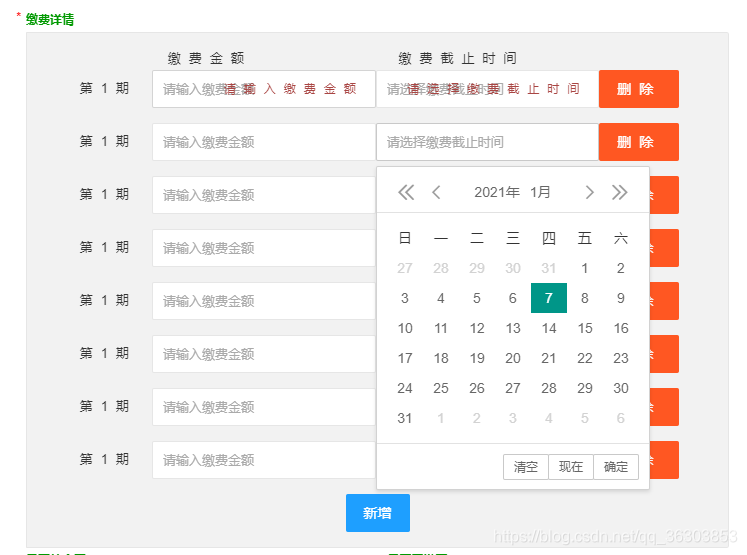
问题 想做一个动态新增表但功能,但是你会发现原先定义好的时间控件没有效果了,变成了普通的input框,于是就需要重新渲染了 1.页面效果 1.html代码 <div id="pay_content" > &l









 超级会员免费看
超级会员免费看

 本文介绍了在使用layui时遇到动态新增表格时时间控件失效的问题。通过分享一种无需修改ID的便捷方法,实现了按class循环渲染时间控件,帮助读者解决此类问题。
本文介绍了在使用layui时遇到动态新增表格时时间控件失效的问题。通过分享一种无需修改ID的便捷方法,实现了按class循环渲染时间控件,帮助读者解决此类问题。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








