







基于监督学习和远程监督的神经关系抽取
作者:王嘉宁 QQ:851019059 Email:lygwjn@126.com
最新:博主发表在华东师范大学学报(自然科学版)的《基于远程监督的关系抽取技术》综述论文今日(2020年9月27日)正式出刊,欢迎下载与引用。
- PDF下载链接:http://xblk.ecnu.edu.cn/CN/10.3969/j.issn.1000-5641.202091006
- 引用: 王嘉宁, 何怡, 朱仁煜, 刘婷婷, 高明. 基于远程监督的关系抽取技术[J]. 华东师范大学学报(自然科学版), 2020, 2020(5): 113-130.
关系抽取作为自然语言处理重要的研究领域之一,一直以来受到国内外诸多高校、科研机构的高度关注。近些年来的ACL、EMNLP、AAAI、IEEE、ICDE、IJCAI等顶会,以“Relation Extraction”或“Relation Classification”为关键字的论文逐年增加。另外作为知识图谱构建流程中的主要步骤,关系抽取也是其重要的部分。
- 一、神经关系抽取介绍
- 二、基于监督学习的神经关系抽取
- 三、基于多示例学习的远程监督关系抽取
一、神经关系抽取介绍
关系抽取旨在通过语义理解的基础上,对目标的实体对的关系进行标注。过去的关系抽取通常采用传统的机器学习分类(贝叶斯网络、决策树、支持向量机等)和聚类(k近邻)的方法对目标实体对在文本中的关系进行标注,这一类被称为统计关系抽取(Statistics Relation Extration)。随着深度学习的推广,以神经网络为主的深度模型能够够好的避免特征工程带来的缺点,自动学习更深层次的语义特征,在一定程度上提高了关系抽取的效果,这一来则被称为神经关系抽取(Neural Relation Extraction)。
另外,关系抽取在传统方法上,通常是根据语法树来捕捉句子中可能存在的关系词,例如对于句子“江苏省会是南京”,可以通过语法依存关系来直接提取出句子中的关系标签“省会”。然而对于一部分句子来说,并没有客观存在的词汇能够描述实体对关系,例如“南京市长江大桥今日全面封闭维修”,其中“长江大桥”和“南京市”应有“位于(location)”的关系,然而句子中并没有显示的词汇表现。因此避免这种问题,通常将关系抽取采用监督学习的方法来解决,通常也被认为是一种关系分类,亦即事先预定义一部分关系标签,在对实体对进行分类。
神经关系抽取目前主要包括四种方法,分别是监督学习、远程监督学习、对抗学习和强化学习,四种不同的方法在关系抽取任务上均解决了相应的问题。本文先重点讲解前两种方法是如何解决关系抽取问题,并分别给出相应的论文详解。
二、基于监督学习的神经关系抽取
2.1 任务描述
形式化描述:给定一个目标实体对
h
e
a
d
(
j
)
,
t
a
i
l
(
j
)
head^{(j)},tail^{(j)}
head(j),tail(j) 和对应的句子
s
(
j
)
=
{
x
1
,
x
2
,
.
.
.
,
x
n
}
s^{(j)}=\{x_1,x_2,...,x_n\}
s(j)={x1,x2,...,xn} ,目标是学习一个监督模型
y
=
f
(
s
)
y=f(s)
y=f(s) 预测目标实体对的关系。其中
y
∈
{
Y
1
,
Y
2
,
.
.
.
Y
m
}
y \in \{Y_1,Y_2,...Y_m\}
y∈{Y1,Y2,...Ym} 。
现如今有诸多数据集是以监督学习为主,如下所示:
| 序号 | 名称 | 下载地址 |
|---|---|---|
| 1 | SemEval 2010 Task 8 | 下载 |
| 2 | TACRED | 详情信息 |
| 2 | FewRel | 详情信息 |
| 3 | BioNLP-ST 2016 Task BB3 | 下载 |
最为常用的是SemEval 2010 Task 8数据集,其主要是由人工标注而成,其中8000个句子用于训练,2717个句子用于测试,一共包含9个关系,18个类和1个无关类。每个类相对均匀。通常评价指标是F1值。
2.2 实现策略
监督学习方法是关系抽取任务中最常用的方法,论文成果也主要集中在2014年至2017年。以监督学习的关系抽取基本为单标签分类,任务通常是给定一段文本及目标实体对,通过训练一个神经模型来预测这个实体对的关系。因此监督学习的关系抽取主要包括如下几步:
(1)句子语义表征:句子的语义表征通常使用词向量作为输入,词向量可以是word2vec、glove、fasttext,也可以是可微调的语言模型Transformer-X、BERT、XLNet、GPT-2。对句子的语义表征模型也通常包括卷积神经网络(CNN)、循环神经网络(RNN),以及以注意力机制为核心的Transformer、BERT等。通过这些神经模型均可以实现将句子序列表征为指定维度的向量。
(2)实体增强:与传统文本分类相区别的是,关系抽取需要由对应实体对的语义信息进行辅助增强。通常一个实体对在句子中的相对位置是不同的,其次实体的类型(包括词性、含义等)也存在差异,这些均会对关系产生影响,因此需要对实体对进行语义表征。通常实体增强部分常用注意力机制(Attention)来完成。
(3)关系表征:这一部分是可选的,关系表征一般是对关系进行语义表征。其相对于传统的分类区别在于关系标签在一定程度上受到实体对的影响,同时不同的关系标签可能存在层级相关性,因此对关系的表征可以让神经模型辅助理解。这一部分通常是预训练关系标签。
(4)分类器与优化器:分类器可以是前馈网络加上softmax层,优化器则可以是梯度下降以及对应的几个变种。
2.3 典型论文
以监督学习为主的关系抽取研究成果众多,本文主要关注神经关系抽取模型。
(1)TextCNN(2014):使用卷积神经网络对文本进行特征提取,开辟了卷积神经网络在自然语言处理中的应用。关系分类自然被视为一种文本分类任务,相对于传统的机器学习模型效果提升许多。

主要思路: 使用预训练词向量对一组batch句子进行向量化表示为一个张量,其次对该张量进行一维度卷积(Conv1d)。对多个不同的过滤器进行拼接后,进行最大池化,最后喂入前馈神经网络进行分类。
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| TextCNN | 下载 | 下载 | F1=82.7% |
(2)Attention-BiLSTM(2016):长短期记忆神经网络因其很好的处理长序列一直以来作为句子表征的首选。常规的应用RNN做文本分类的方法是将最终时刻的RNN输出值喂入全连接层,然而这种方法容易导致大多数的信息没有参与到分类中。此注意力机制解决这个问题,其可以很好的对每个时刻单词对分类贡献程度进行有选择的依赖,一定程度上可以提升关系抽取的效果。
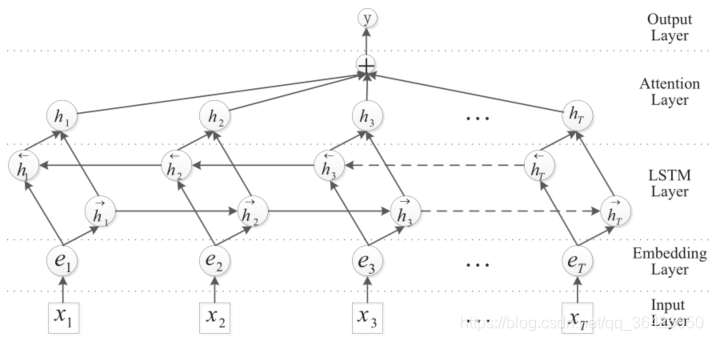
主要思路: 使用预训练词向量作为句子的输入,应用一层RNN,其中cell选择LSTM,其次RNN输出层维度则为[batch_size, max_length,hidden_size],通过一层注意力进行加权求和最终得到输出向量为[batch_size,hidden_size],并喂入全连接层中进行分类。
参考解析: 论文解读:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| Att-BiLSTM | 下载 | 下载 | F1=84.0% |
(3)BiLSTM-RNN(2016):这是另一种使用长短期记忆神经网络实现关系抽取的方法,其相比之前的策略不同在于它将句子根据实体在文中的位置进行了划分,包括before、former、middle、latter和after。其中former和latter表示头实体和尾实体,另外三个部分则是三个片段。作者通过实验发现对目标实体对关系抽取大多数依赖于former+middle+latter的片段部分。
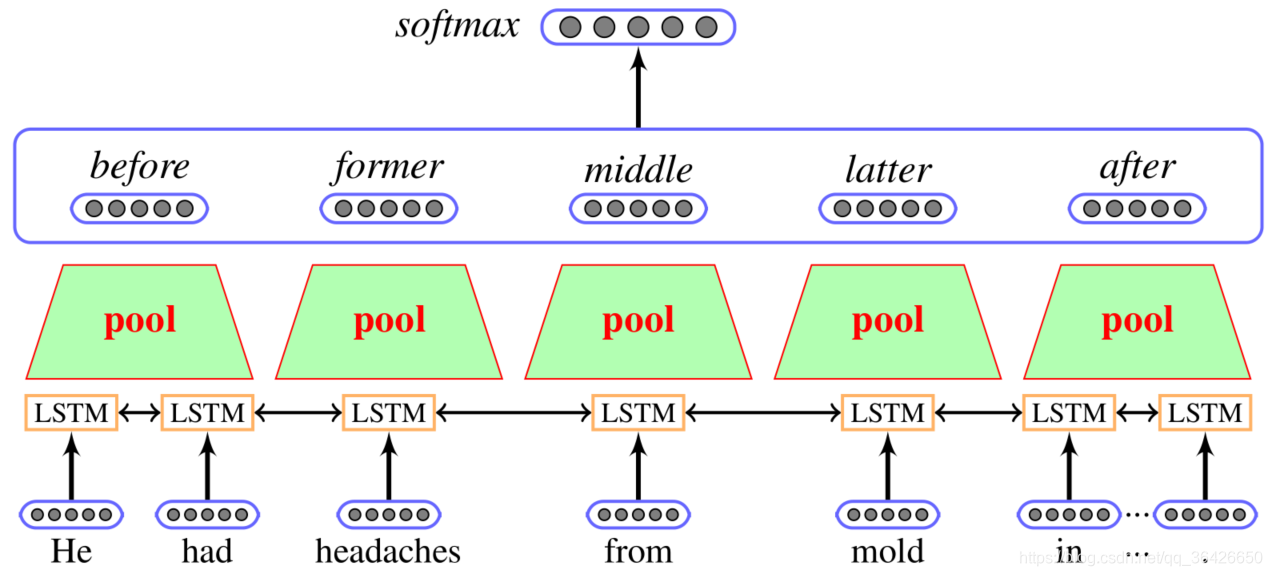
主要思路: 同样使用预训练词向量,在此基础上对每个单词的每个字符又通过RNN进行预训练,其次使用位置表征(PE)、词性标注(POS)和词网(WordNet)并直接拼接起来作为模型的输入。第一层为一层BlLSTM,其次对五个片段分别进行池化,池化包括四种池化方式(最大池化、最小池化、平均池化和平方和开根池化)并全部拼接起来。最后喂入全连接层中。
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| BiLSTM-RNN | 下载 | F1=83.1% |
(4)BiLSTM+EntityAttention(2019):这也是基于RNN和Attention的模型,其应用了最新提出的自注意力机制,类似机器翻译模型中的自注意力机制一样,通过对句子本身进行注意力加权学习句子内在语义特征。另外考虑到实体对关系抽取的影响,通过其在句子中的位置、实体本身及语义相关性,应用注意力学习潜在实体类型。
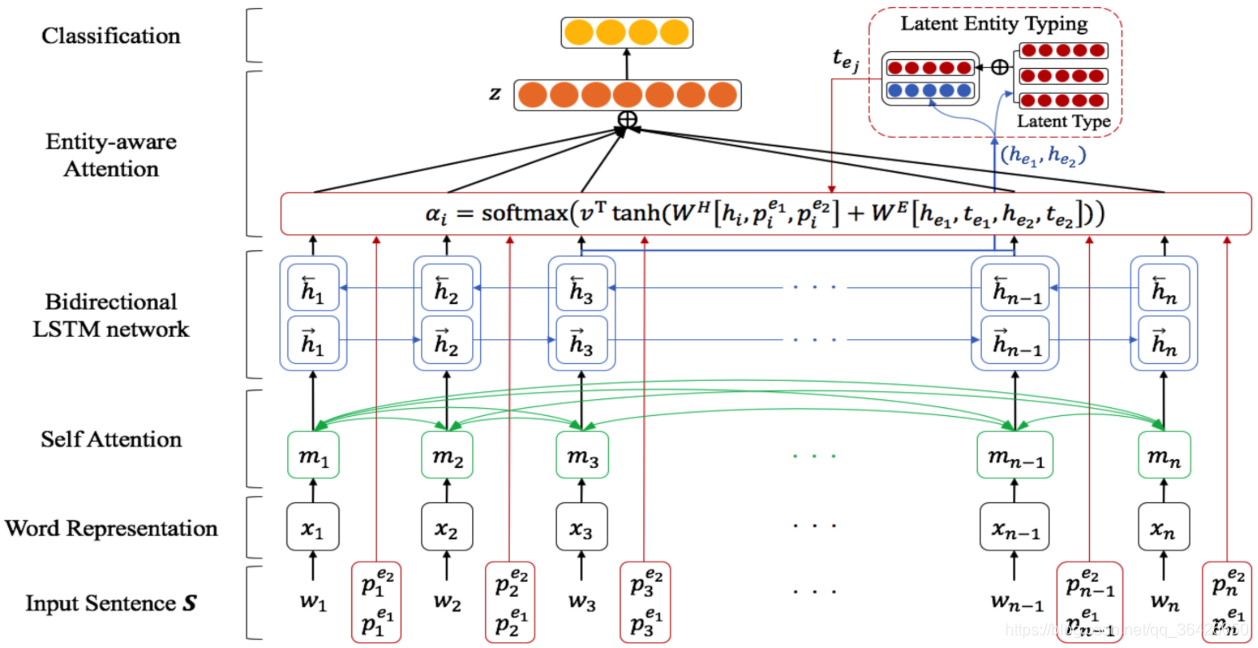
主要思路: 输入层只包括预训练词向量和随机初始化的位置表征向量。词向量作为模型输入部分首先进行自注意力编码,其次喂入BiLSTM中,得到句子语义向量;对于位置表征直接与前面的语义向量进行拼接并学习注意力(主要是两个实体的语义向量和其位置向量进行注意力学习)。最后根据这个注意力机制对所有时刻的单词进行加权求和,这一部分与Attention BiLSTM一样。
(5)BERT(2019):BERT模型是利用Transformer模型基础上进行大规模预训练的语言模型,其通过海量文本的学习和上亿参数的训练,使得模型能够成为超强的“语言专家”。通过对BERT微调后可以直接将输出向量喂入分类器中,实验表明其效果达到最好。
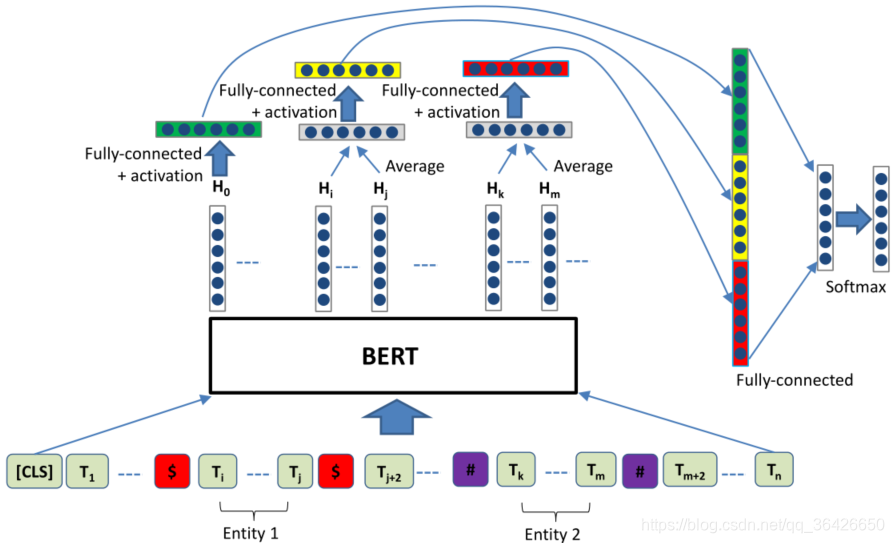
另外基于该模型基础上做出的改进,在诸多任务上成为最优模型。
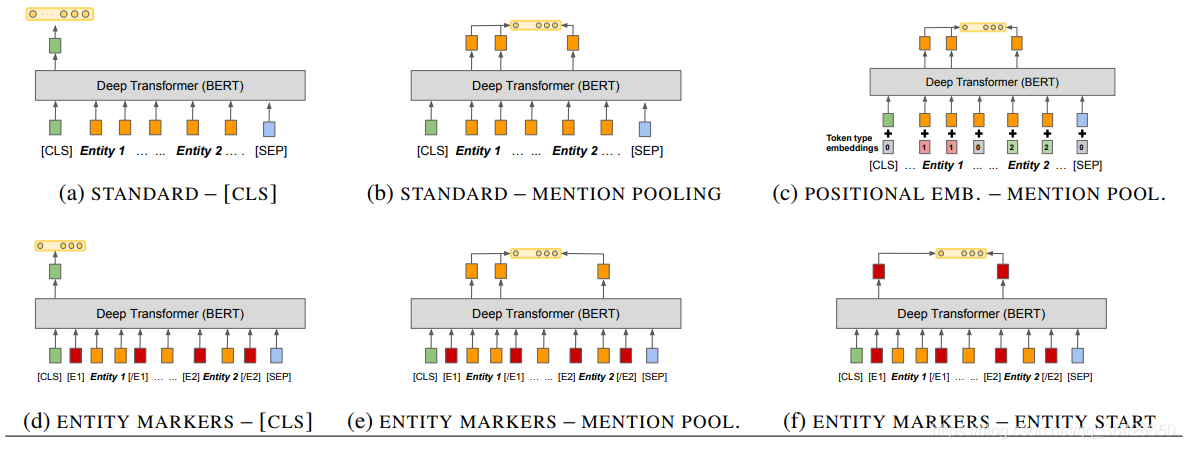
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| R-BERT | 下载 | F1=89.25% | |
| BERT+MTB | 下载 | F1=89.5% |
三、基于多示例学习的远程监督关系抽取
3.1 任务描述
我们知道在监督学习任务中,我们需要大量的人工标注数据供模型进行训练。而在大多数应用中(知识图谱、社交网络)中数据的需求量往往非常大,人工和时间成本过高。因此在2009年由Mintz首次提出“远程监督”概念。远程监督是一种增强的监督学习,其主要依赖于远程知识库(KB),例如现如今比较常用的FreeBase、YaGo、DBPedia等知识库作为基础,根据这些知识库中现有的实体和对应关系,对获取的语料进行快速标注。例如对于一个实体对三元组
(
h
,
r
,
t
)
(h,r,t)
(h,r,t) ,标注的规则则是只要目标实体对
(
h
,
r
)
(h,r)
(h,r) 在给定的文本中存在,则认定该文本描述的实体对关系即为
r
r
r 。因此远程监督方法极大地较少由于人工成本导致的语料不足的问题,但是这带来一个新的问题,由于实体对关系本是已知的,而所在的文本不一定是描述这种关系,因此这存在一定的噪声。
远程监督关系抽取的主要任务则主要有两个:(1)利用远程知识库辅助文本语义理解实现关系预测,(2)降低由于错误标注的噪声数据对关系抽取的影响。
现如今对远程监督关系抽取主要采用的方法是多示例学习。多示例学习是一种监督学习,其目标是将若干样本(示例)以包为单位组合在一起让模型进行学习,如果包中存在一个正例样本,则认为该包为正例,反之若全部为负例,则该包为负例。关系抽取的多示例则是将相同实体对及关系(亦即相同的三元组)对应的所有样本组合为一个包,因此包的数量即为三元组的数量。
形式化语言:给定一个远程知识库
K
B
KB
KB ,且
(
h
i
,
r
j
,
t
i
)
∈
K
B
(h_i, r_j, t_i)\in KB
(hi,rj,ti)∈KB,其中
h
i
h_i
hi 为头实体,
t
i
t_i
ti 为尾实体,
r
j
r_j
rj 为关系类。给定一堆样本
X
=
{
B
1
,
B
2
,
.
.
.
,
B
k
}
X=\{B_1,B_2,...,B_k\}
X={B1,B2,...,Bk},其中
B
i
=
{
x
i
1
,
x
i
2
,
.
.
.
,
x
i
m
∣
(
h
i
,
r
j
,
t
i
)
}
B_i=\{x_i1,x_i2,...,x_im|(h_i, r_j, t_i)\}
Bi={xi1,xi2,...,xim∣(hi,rj,ti)},学习一个模型
y
=
f
(
X
)
y=f(X)
y=f(X) 预测给定包
B
i
B_i
Bi 的关系类。
| 序号 | 名称 | 下载地址 |
|---|---|---|
| 1 | NYT | 下载(需翻墙) |
| 2 | GDS | 下载 |
3.2 实现策略
基于多示例的远程监督关系抽取策略包括:
(1)打包:模型的输入部分为一组使用预训练词向量的包,输入张量为
[
N
,
d
s
,
d
w
]
[N,d^{s},d^{w}]
[N,ds,dw] ,其中
N
N
N为一个batch中所有包中的样本数(batch大小为包的数量,超参数,需要确定,而每个包内的示例则数量不一),
d
s
,
d
w
d^{s},d^{w}
ds,dw 分别为句子最大长度和词向量维度。另外还有的策略是直接预定义包的大小,对于超过该值的则分为多个包;
(2)句子表征:对每一个句子进行语义表征,转化为张量
(
N
,
d
h
)
(N,d^{h})
(N,dh),这部分通常选择CNN或Attention;
(3)知识库增强:由于远程知识库作为辅助关系抽取,因此可以使用图网络表征方法或知识表示对实体对和关系进行语义表征。通常认为对于一个实体对
(
h
,
r
,
t
)
(h,r,t)
(h,r,t) 有
h
+
r
/
/
t
h+r//t
h+r//t,因此可通过学习得到的实体表征做差运算
h
−
t
h-t
h−t 增强实体对关系。
(4)降噪:由于一个包中存在未知数量的噪声,先后有两种策略,一种是认为包中有一个是非噪声数据,则直接将该包判断为这个类;另一种则是引入包注意力,对包内所有示例的语义表征进行加权求和,由“一言堂”到“众言堂”,实验表明降噪效果明显提升。事实上,远程关系抽取的实际目标并不是为了构建图谱(因为已经有了远程知识库),而是学习一个已知的关系抽取模型提高语料的质量。
2.3 典型论文
远程监督神经关系抽取主要选择如下几篇代表作品:
(1)PCNN(2015):自受到2014年TextCNN在文本分类任务上的显著提高的启发,CNN也被引用至远程监督的关系抽取中。PCNN(Piecewise CNN)指分段卷积神经网络,其改进了TextCNN,如下图所示:
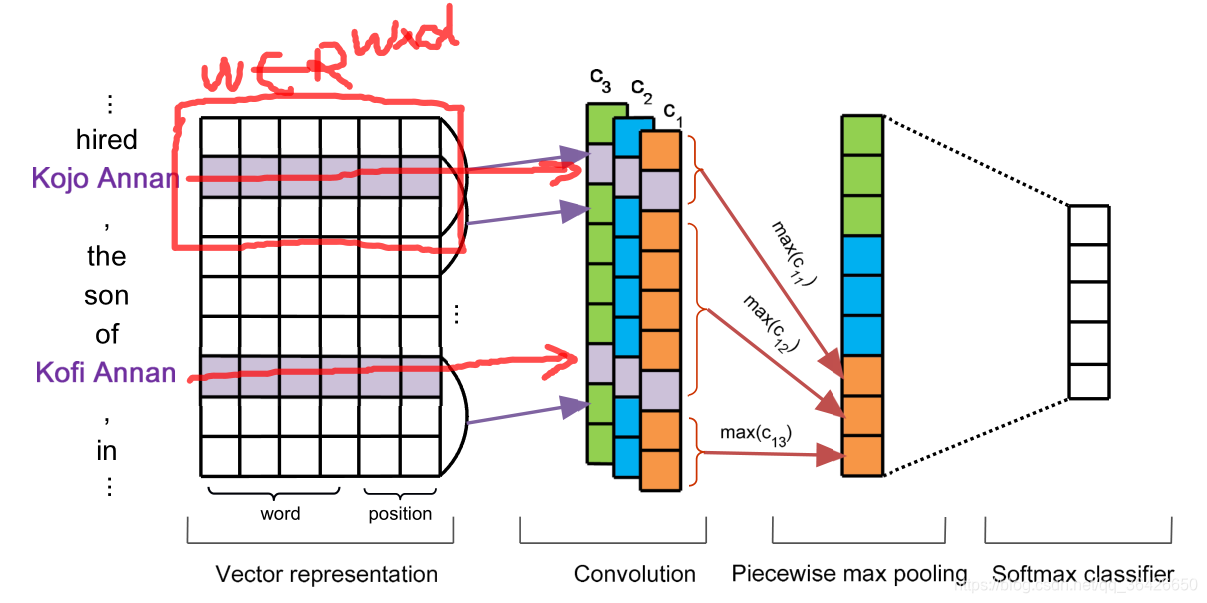
相比于TextCNN,其在池化层作出改进:由于实体对在文本中可将句子划分为三个部分,因此在池化层分别对三段进行最大池化,因此不论句子有多长,池化后总是由三个元素组成的向量。根据过滤器的数量将对应的所有池化后的三维向量拼接起来作为这个句子的语义表征。
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| PCNN | 下载 | 下载 | P@100=86.0% |
(2)PCNN+ATT(2016):自PCNN提出以来,以CNN为表征模型的多示例的远程监督学习方法成为关系抽取的主流方法之一。但PCNN有明显的问题:(1)模型认为当一个包(实体对)中只要存在一个正例,则判断当前的包(实体对)为正例,即当前的关系类是正确的;(2)句子表征只是单纯的对每一个窗口内的单词进行卷积,并未考虑到每个词对整个句子的重要性。基于这两个问题,PCNN-ATT提出。
作者分别在句子表征和包表征进行改进。对于句子表征部分,首先将句子根据两个实体划分三个序列片段,其次根据每个片段进行最大池化操作,形成一些数量的三维向量,其次根据每个片段进行拼接,最后进行分类。如下图所示:
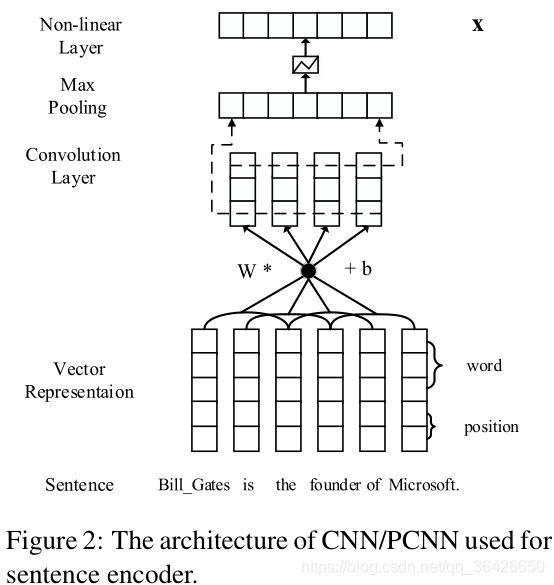
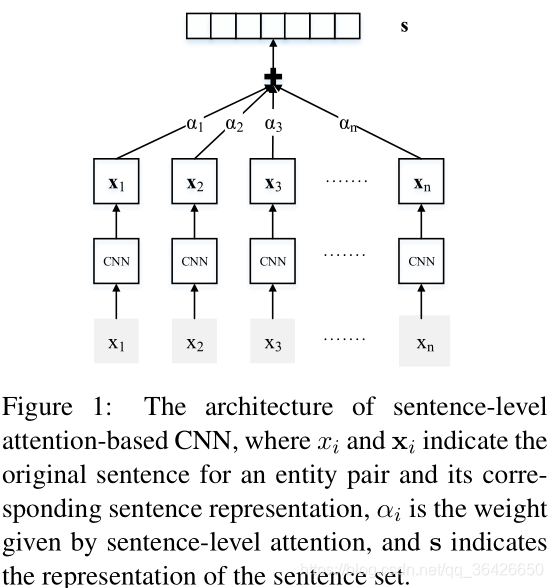
其次对于每个句子,替换原来的“一言堂”,而是接收所有句子的“发言”。亦即训练一个注意力机制,对相同实体对中所有的示例的句子表征进行加权平均求和后,作为整个包的表征。这么做的好处是使得对实体对关系决策变得平滑,对包中关系类正确的句子加大关注,对噪声减少关注。
| 模型名称 | 论文地址 | GitHub | 效果 |
|---|---|---|---|
| PCNN+ATT | 下载 | 下载 | P@100=76.2% |
3.3 评价指标
根据前面所述,远程监督方法的关系抽取的目标是为了训练含有噪声的训练集,尽可能充分利用其中有效的样本,减少噪声对决策的影响进行关系抽取(分类)。现如今包括如下评价指标:
(1)precision&recall:由于关系抽取属于多类分类问题,因此常需要对每个类计算相关的precision和recall。以NYT数据集为例,有90%以上的样本对应的实体对关系类为“无关”,因此通常进行比对的为去除“无关”关系类的其他所有类的微平均precision和微平均recall;
(2)AUC面积:通过多类分类转化为对每个类进行二分类,可以形成一组二分类的P-R值对。例如假设一个样本的五类分类为
[
0
,
1
,
0
,
0
,
0
]
[0,1,0,0,0]
[0,1,0,0,0] ,则可以转化为5个二分类,分别为
[
[
1
,
0
]
,
[
0
,
1
]
,
[
1
,
0
]
,
[
1
,
0
]
,
[
1
,
0
]
]
[[1,0],[0,1],[1,0],[1,0],[1,0]]
[[1,0],[0,1],[1,0],[1,0],[1,0]]。因此可以得到对应所有样本的P-R曲线以及对应的已排序的P-R值对,则其与坐标轴所围成的面积即为AUC面积;
(3)P@N:针对(2)得到的已排序的P-R值对,取第N对(或第N%)对应的precision值。例如得到一组排序的P-R值对为
[
(
1.0
,
1.0
)
1
,
(
1.0
,
0.9
)
2
,
.
.
.
,
(
0.6
,
0.4
)
100
,
.
.
.
]
[(1.0,1.0)_{1},(1.0,0.9)_{2},...,(0.6,0.4)_{100},...]
[(1.0,1.0)1,(1.0,0.9)2,...,(0.6,0.4)100,...],则P@100=0.6。
(4)F1值:F1值由(1)计算的微平均precision和微平均recall,由
F
1
=
2
∗
p
r
e
c
i
s
i
o
n
∗
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F1=\frac{2*precision*recall}{precision+recall}
F1=precision+recall2∗precision∗recall 求得。
现如今对于NYT数据集来说,效果较好的神经模型AUC值在0.38-0.42之间,P@100在0.78-0.85之间。
四、其他
最近,关于关系抽取一些最新的研究反向包括:使用强化学习、对抗学习实现远程监督关系抽取降噪;使用图网络、知识表示实现关系抽取;在具体领域内实现关系抽取等。更多详细关于远程监督关系抽取的最新研究问题以及相关方法请见:
- PDF下载链接:http://xblk.ecnu.edu.cn/CN/10.3969/j.issn.1000-5641.202091006
- 引用: 王嘉宁, 何怡, 朱仁煜, 刘婷婷, 高明. 基于远程监督的关系抽取技术[J]. 华东师范大学学报(自然科学版), 2020, 2020(5): 113-130.
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











