







物理信息神经网络(PINNs)代表了一种令人兴奋的新建模范式,这种范式正在各行各业迅速崭露头角。
PINNs 最有前景的应用之一是复杂物理系统中的异常检测Anomaly Detection。这一应用尤其值得关注,因为它解决了传统机器学习方法在实践中一直难以克服的几个关键痛点。
在这篇博客中,让我们通过回答实践者在采用基于 PINN 的方法进行异常检测Anomaly Detection时最常遇到的一些问题,深入探讨这个热门话题。
具体来说,我们将回顾:
- 为什么:传统异常检测方法的痛点
- 是什么:PINNs 在异常检测中的优势
- 怎么做:基于 PINN 的异常检测解决方案的常见实现模式以及真实世界的成功案例
- 注意点:PINNs 在实践中存在的局限性
- 适配性检查:一个定量的决策框架,用于判断 PINNs 与手头问题的契合度。
读完这篇博客后,你将获得实用的见解,以评估 PINNs 是否以及如何能够有效解决你独特的挑战。
好了,话不多说,让我们开始吧!
1. 好啦,那我们到底面临什么问题呢?
1.1 理解异常
异常(或离群点)是指与预期正常行为显著偏离的数据点或模式。在工业环境中,这些异常通常代表着设备故障、流程偏差、材料缺陷,甚至是恶意攻击,这些都可能导致巨大的成本、安全隐患或安全漏洞。因此,及时检测这些异常在各个行业中都起着至关重要的作用,有助于防止代价高昂的故障,减少停机时间,并保持工业运营的安全性和效率。
图 1. 异常检测的实际应用场景涵盖了众多行业。(图片由作者提供)
异常本身可以以不同的形式表现出来。我们可以大致将它们分为三类:(1)点异常,即单个离群点,例如突然的峰值;(2)上下文异常,当数据点因为周围的环境或上下文而变得异常时,即使它们的值本身并不极端;(3)集体异常,即一组数据点的组合模式是异常的。
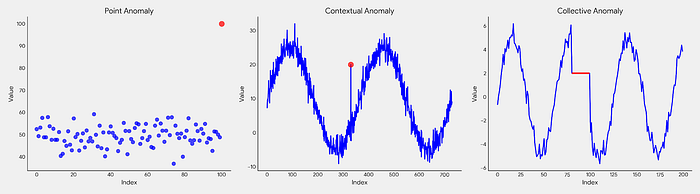
图 2. 三种不同类型的异常示意图。(图片由郭帅博士提供)
好吧,既然有了这些异常,那我们该如何以自动化和可扩展的方式检测它们呢?
机器学习登场了。
1.2 传统机器学习方法
机器学习技术在异常检测领域有着悠久的应用历史。事实上,异常检测是工业人工智能最基础的用例之一。
主要根据训练阶段可用数据的性质,这些传统的机器学习方法通常可以分为以下几种范式:
- 监督学习:当在训练时既有标记为正常的样本,又有标记为异常的样本时,我们就可以简单地训练一个模型,直接学习区分这两个类别。这本质上就是一个标准的分类问题,任何现成的分类算法(例如 SVM、随机森林、XGBoost 等)都能胜任。
- 半监督学习:当在训练时只有“正常”数据的干净样本可用时,我们可以训练一个模型来学习正常性的边界。在推理过程中,任何落在正常性边界之外的新样本都会被标记为异常。单类 SVM 是这一类别的典型例子。深度学习方法,如支持向量数据描述(SSVD)和生成模型(例如 GANs),在工业应用中也很受欢迎。
- 无监督学习:当我们在训练时只有原始的、未标记的数据时,我们就得依靠无监督机器学习方法来寻找数据中的结构或模式。异常通常被识别为那些不太符合所学习结构的点。这一类别的常见方法包括概率方法(例如基于直方图的方法、高斯混合模型等)、基于密度的方法(例如局部异常因子)、基于距离的方法(例如 KNN)、基于聚类的方法(例如 DBSCAN)、基于重构的方法(例如 PCA、自编码器等)以及基于划分的方法(例如孤立森林)。
- 集成学习:与其依赖单一算法,我们不如聚合多个候选异常检测模型的预测结果,以提高整体的鲁棒性和准确性。这些候选模型可以是同质的(例如,相同的算法但具有不同的超参数或在不同的数据子集上训练),也可以是异质的(例如,不同的算法)。通过利用“众人智慧”,这种方法通常能够比单个候选模型取得更优越的性能。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











