









今天的LLM通过利用外部工具变得越来越强大——无论是计算器、网络搜索还是数据库。但随着工具数量的增加,头痛也随之而来。提示变得臃肿,选择适合特定任务的正确工具变得更加难以管理。RAG-MCP框架,用于解决LLMs在外部工具选择中的提示膨胀和决策复杂性问题。具体来说,
-
检索增强生成(RAG):RAG-MCP结合了检索增强生成(RAG)原则和MCP框架。RAG的核心思想是在推理时动态检索相关的知识片段,而不是一次性提供全部知识。
-
语义检索模块:开发了一个语义工具检索模块,将每个可用工具的元数据表示在向量空间中,并高效地将用户查询与最相关的工具匹配。这显著减少了提示的大小和复杂性,并提高了决策的准确性。
-
MCP压力测试:为了量化LLMs在选择工具时的性能下降,设计了一个MCP压力测试。在该测试中,模型被呈现N个MCP模式(一个真实值和N-1个干扰项),并要求其选择和调用正确的WebSearch MCP。通过变化N的值(从1到11100),测量选择准确性、任务成功率、提示令牌使用和延迟。
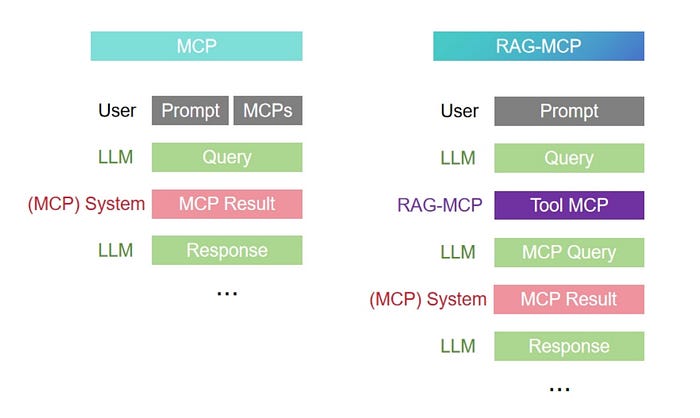
图1:MCP与RAG-MCP在推理过程中的比较。
":来源。
如图1右侧所示,RAG-MCP方法通过首先使用语义检索器从整个工具集中筛选出最相关的工具来改善推理——通常只选择最顶尖的一个。然后,它仅将所选工具的描述注入模型的提示中。这显著减少了标记的数量,并增加了模型选择正确工具的机会。
相比之下,传统的MCP方法(图1,左)在提示中一次性包含了_所有_可用工具的描述。这导致了严重的提示臃肿,迫使模型在大量无关信息中筛选。因此,它难以做出准确的决策,常常无法选择正确的工具。
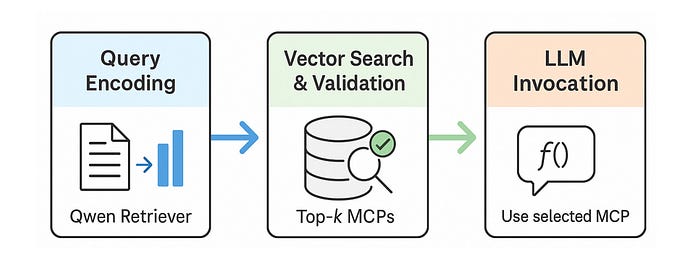
图2:RAG-MCP管道。
":来源。
如图2所示,RAG-MCP首先使用Qwen-max对用户查询进行编码,然后检索和验证前k个MCP,最后调用最合适的一个。
优点与创新
- RAG-MCP框架:首次将检索机制与LLM功能调用集成在MCP设置中,允许LLM通过查询工具库来选择相关选项,而不是一次性提示所有工具。
- 可扩展的工具检索:开发了语义工具检索模块,将每个可用工具的描述表示为向量空间中的点,并高效地将用户查询与最相关的工具匹配,显著减少了提示的大小和复杂性。
- 改进的工具使用性能:通过实验证明,RAG-MCP有效应对了简单扩展工具集带来的性能下降,在大规模工具集中仍能保持高选择准确性和可靠性。
- 减少提示膨胀:通过仅提供相关的MCP元数据,RAG-MCP避免了上下文窗口过载,即使在完整的工具注册表很大的情况下也能保持高准确性。
- 降低认知负荷:LLM不再需要筛选数百个干扰项,提高了选择准确性并减少了幻觉现象。
- 资源效率:与传统MCP客户端不同,RAG-MCP仅在选择时激活选定的MCP,降低了启动成本,并支持任意大规模的工具集而不受基础设施瓶颈的限制。
- 多轮对话的鲁棒性:在跨越多个回合的对话中,LLM无需重新包含所有MCP提示,RAG-MCP的检索器动态处理工具回忆,为任务特定的推理释放了上下文空间。
关键问题及回答
问题1:RAG-MCP框架中的语义检索模块是如何工作的?它如何提高工具选择的准确性?
RAG-MCP框架中的语义检索模块通过将每个可用工具的元数据(如MCP功能模式、使用示例等)表示在向量空间中,并利用向量空间搜索引擎(如Qwen)对MCP索引进行语义搜索,从而高效地将用户查询与最相关的工具匹配。具体步骤如下:
- 编码任务描述:首先,用户的任务描述会被编码并提交给检索器。
- 语义搜索:检索器对MCP索引进行语义搜索,返回与任务描述最相似的top-k个候选MCP。
- 验证和选择:对于每个检索到的MCP,RAG-MCP可以生成几个示例查询并测试其响应,以确保基本兼容性。最终,只有最佳MCP的描述(包括其工具使用参数)会被注入到LLMs的提示中或通过函数调用API执行。
这种方法通过以下方式提高工具选择的准确性:
- 减少提示大小:只提供相关的MCP元数据,避免了上下文窗口过载。
- 降低认知负荷:LLMs不再需要筛选大量无关的干扰项,提高了选择准确性并减少了幻觉。
- 资源效率:只激活选定的MCP,降低了启动成本,支持任意大的工具集而不受基础设施瓶颈的限制。
问题2:MCP压力测试是如何设计的?它揭示了什么问题?
MCP压力测试的设计如下:
- 数据收集:使用MCPBench的web搜索子集,包含超过4400个公开的MCP服务器。
- 实验设置:在每个试验中,模型被呈现N个MCP模式(一个真实值和N-1个干扰项),并要求其选择和调用正确的WebSearch MCP。通过变化N的值(从1到11100),测量选择准确性、任务成功率、提示令牌使用和延迟。
MCP压力测试揭示了以下问题:
- 提示膨胀:随着MCP池大小的增加,提供所有MCP描述会导致提示膨胀,模型难以区分和回忆正确的工具。
- 决策开销:随着工具数量的增加,模型在选择工具时的决策开销也会增加,可能导致错误的选择。例如,GPT-4在某些场景下会幻觉出一个不存在的API,Anthropic的Claude也会选择错误的库。
这些结果表明,简单地扩展工具集可能会降低LLMs的性能,需要通过有效的工具管理和选择机制来解决这些问题。
问题3:RAG-MCP框架在实验中表现如何?与其他基线方法相比有哪些优势?
RAG-MCP框架在实验中表现优异,具体优势如下:
- 选择准确性:RAG-MCP的选择准确性为43.13%,显著高于实际匹配的18.20%和空白条件的13.62%。
- 提示令牌使用:RAG-MCP的平均提示令牌数为1084,远低于空白条件的2133.84,反映了显著的减少。
- 完成令牌使用:尽管RAG-MCP的完成令牌数(78.14)略高于实际匹配(23.60),但这与更高的准确性和整体任务成功率相关。
总体而言,RAG-MCP通过动态检索最相关的MCP模式,有效地应对了LLMs在外部工具选择中的提示膨胀和决策复杂性问题,显著提高了工具选择的准确性和系统的可扩展性。
思考与见解
简单来说,RAG-MCP是一种通过仅包含真正相关的内容来压缩提示的智能方法。虽然这是一种创新的方法,但我对技术和实施方面有一些担忧。
首先,该方法严重依赖于语义检索器的准确性。如果检索器不够强大或遭遇语义漂移,整个系统可能会难以找到正确的工具。
其次,核心机制检索前K个最相关的工具(K通常设置为1),并仅将该工具的模式注入LLM。然而,RAG-MCP并没有探讨当K > 1时会发生什么,或者如果多个工具按顺序调用,性能可能会如何变化。这似乎是一个错失的机会,可以研究潜在的权衡或性能提升。
最后,RAG-MCP的一个卖点是它不需要重新训练语言模型——只需更新向量索引。但在实践中,如果检索器(例如Qwen-max)和生成器(另一个LLM)具有不同的风格或推理模式,它们的语义理解可能不一致,这可能导致误解或不一致的输出。



















 1632
1632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











