






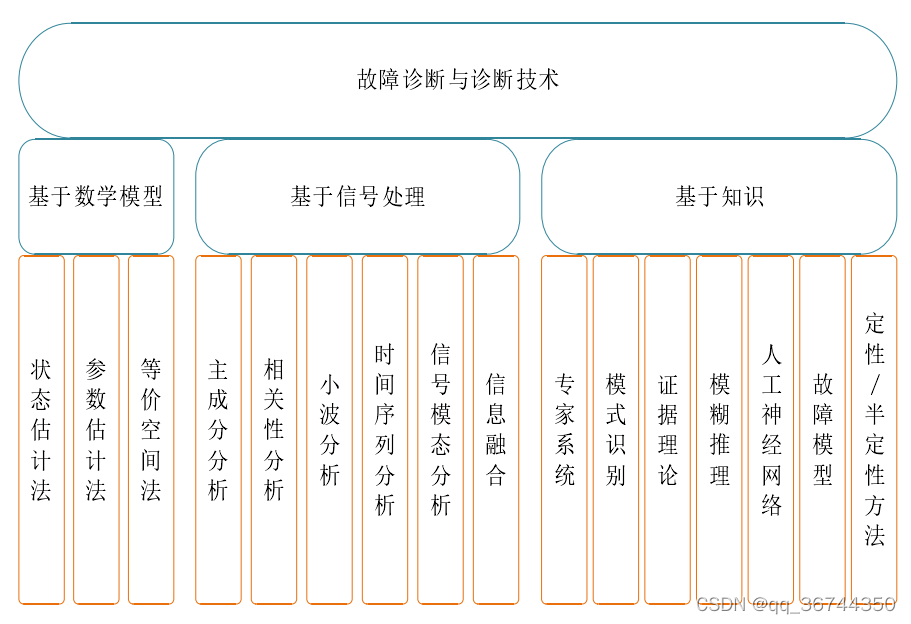
列车速度的提升不仅仅带来了快捷的外出方式,也为铁路系统的运行维护带来了全
新的挑战。为了保证铁路系统运行的安全性和高效性,确保铁路信号设备的安全可靠是
重中之重。针对铁路信号设备安全性和可靠性的增强,首当其冲的任务则是铁路信号
设备的故障诊断能力以及故障维修效率的提高。目前,道岔转换设备是铁路信号设备中重要的驱动设备,对于保护交通安全和提高铁路运输效率起着至关重要的作用。目前我国分布着大量的道岔设备,暴露在户外,这些铁路道岔具有数量众多,种类繁多,结构复杂,使用寿命短,运行环境多样等特点,这使检修工作往往耗费大量人力物力。当前绝大部分铁路的道岔设备运行状态的检测,都是依靠定期的常规预防性测试和人工计划维护,这导致现场维修的工作人员难以及时地发现有故障的道岔,从根本上存在着安全隐患的问题。与此同时,手动测试需要维护人员具有丰富的经验,而缺乏经验的员工易在诊断中造成人为错误。所以,铁路道岔的维护需要向着更加可靠,高效和自动化的方向发展。
当道岔工作时,依靠电力驱动转辙机,实现道岔的开合动作。伴随着物联网的发展,
传感器和微型计算机已嵌入铁路道岔设备中,可以实时监视工作状态并收集转辙机功率、
电流和传递力等模拟信号数据。这些获取的监视信号数据可以作为一种判断道岔故障与
否的依据。道岔的动作过程主要是被划分解锁,转换和锁闭这三个阶段。当发生故障时,
例如在道岔动作路径中卡有一块石头的情况下,道岔无法正常锁定,电动机的电压将相
对正常情况多保持几秒钟。锁闭阶段的动作功率曲线可能会显示一个额外的峰值,之后
将保持一个恒定值,与正常情况相比,该值不会降为零。因此,道岔的监视数据诸如动
作功率可以反映出道岔的工作状态,通过对此类数据进行分析,实现故障诊断是理论可
行的。
1 道岔系统简述
就像汽车上的方向盘一样,道岔可以控制火车的方向,并且是轨道交通系统的核心
基础设施之一。确保道岔正常运行是火车安全的重要任务。由于道岔分布在户外,连接
着不同的轨道,并在火车经过时承受巨大的压力,这使得道岔成为铁路系统中最常见的
易损设备之一。道岔的主要组成部分包括转辙机,导轨,护轨等。转辙机控制尖轨将火
车引导至目标轨道的导轨的位置;导轨负责列车从基本轨向护轨的过渡;护轨的作用是
保护列车安全通过两条轨道的交叉点。图 展示的是单开道岔的基本结构。
常用的基于电驱的转辙机由电动机、传感器和控制电路组成,这些电路可以控制道
岔的运动并在工作时报告状态数据。在道岔动作过程中,铁路信号监控系统会收集伴随
整个动作的电流和功率值。然后将捕获的信号数据(如功率值)显示在监视中心的功率
时间平面中,该时间平面将时间作为水平轴,将功率值作为垂直轴。因此,这些曲线可
以帮助分析道岔动作行为,并吸引了大多数关于故障诊断的研究。在道岔工作过程中,根据其动作过程可分为三个阶段:解锁阶段、转换阶段、锁闭阶段。
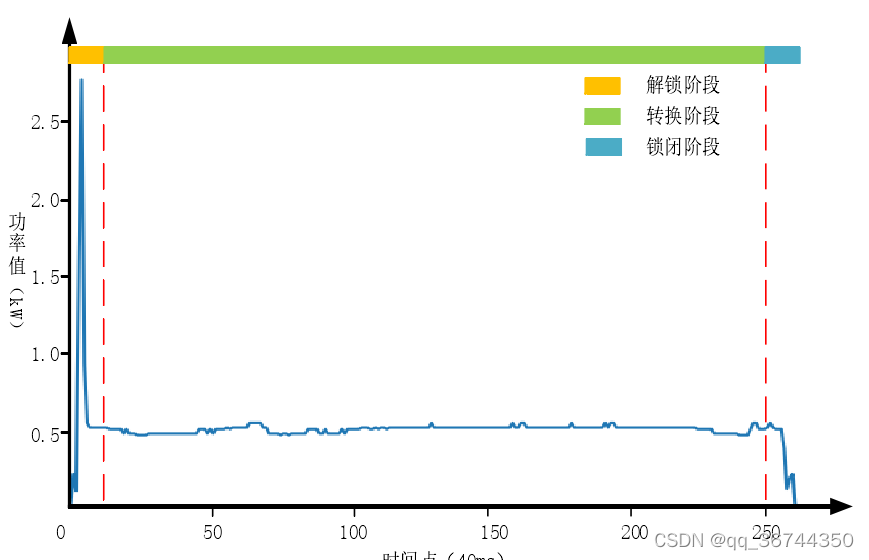
图 2-2 显示了道岔的典型工作功率曲线。𝑥轴表示时间采样点,采样点的时间间隔
为 40ms。𝑦轴以 k W 为单位表示功率值。如图 2-2 所示,曲线可以依据道岔动作过程阶
段大致分为三个窗口。第一曲线窗口与道岔动作的解锁阶段有关,启动后,向道岔施加
一小段较大的功率以抵抗静摩擦并启动尖轨,因此功率曲线主要显示为陡峭的峰值。对
应于转换阶段的第二窗口,该阶段是指在成功解锁阶段道岔正常开始运行后,尖轨从起
始位置旋转到目标位置的过程。在此期间,道岔将具有持续的动力来支撑尖轨运动,因此相应的动力曲线相对时间较长且平坦。第三个窗口表示尖轨最终到达其目标位置的锁
定阶段。道岔已成功完成一次动作,转辙机将不再通电,最终平缓曲线急剧下降至零。
以上是功率曲线为正常状态下的动作过程,但实际应用中,由于环境、转弯幅度等因素
影响,导致即使同型号道岔的每个动作阶段的持续时间可能会有所不同。
2 道岔典型故障类型
根据分析已有真实数据以及查阅相关文献,本文所提出的道岔故障诊断方法将面向以下六种道岔故障模式,分别记为𝑓1-𝑓6,图 2-3 展示了 6 种故障模式下的道岔动作功率曲线。
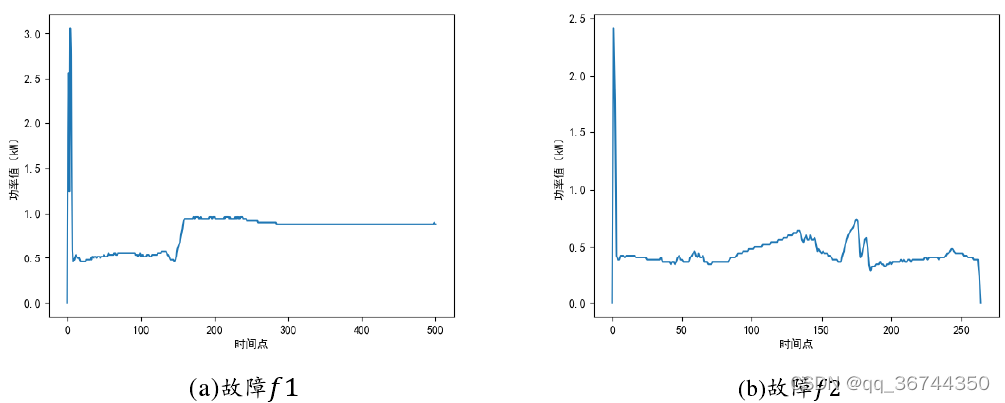
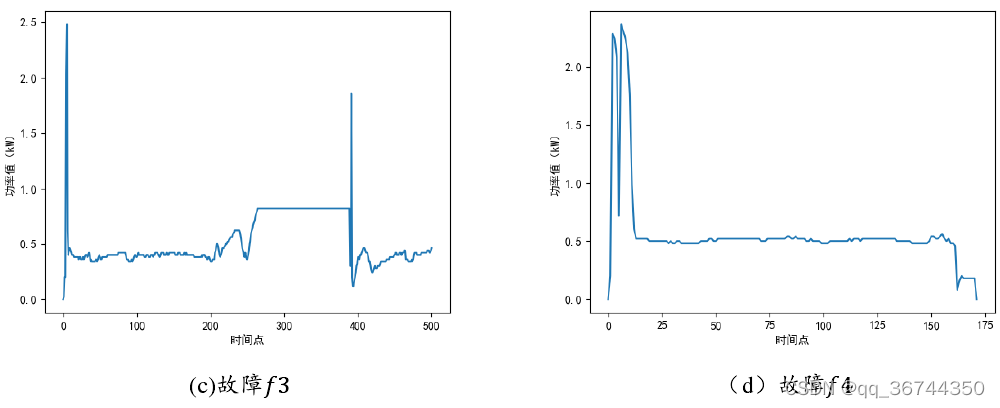
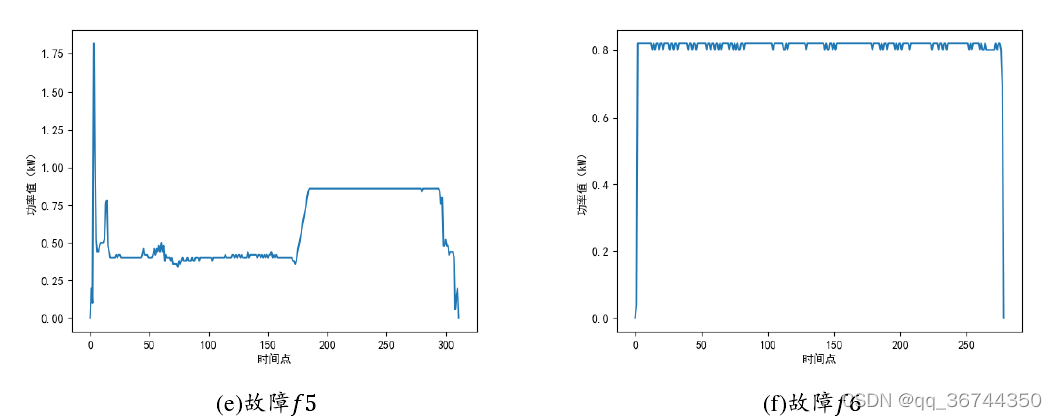
在道岔实际运行过程中,由于道岔动作频繁性以及道岔工作过程中的恶劣条件,可
能发生的故障种类往往不止上述六种。例如故障模式𝑓3,可以继续细分为三种可能的
故障模式。但是,这种细分下的故障模式尚且没有一个稳定的故障分类。且上述六种道
岔故障模式已涵盖大多数道岔发生故障时可能的类型,对应的故障信号曲线往往包含了
大多数故障信号曲线的变化特征。因此,本文只研究上述六种典型故障的故障诊断方法。
道岔数据集展示,

这里有某铁路局一年的道岔运行数据记录txt,直接可用。
基于粒子群优化深度核极限学习机的到道岔故障诊断方法 代码示例
%% DKELM
close all;clear;format compact;format short;clc;rng('default')
%%
load data_feature_fft
[train_x,train_ps]=mapminmax(train_X',-1,1);
test_x=mapminmax('apply',test_X',train_ps);
P_train = double(train_x)' ;
P_test = double(test_x)' ;
T_train = double(train_Y);
T_test = double(test_Y);
%%
%elm-ae的参数
h=[100 ,50];%各隐含层节点数,里面有几个数就是几个隐含层,即有几个ELM-AE参与无监督预训练,数字代表隐含层节点数
% 比如 h=[100,50],假如输入是200,输出是5类,则DKELM网络结构为200-100-50-5。
% 比如 h=[100,50,20],假如输入是200,输出是5类,则DKELM网络结构为200-100-50-20-5。
TF='sig';%ELM-AE激活函数
lambda=inf;%ELM-AEL2正则化系数
%顶层核极限学习的惩罚系数与核参数
kernel='RBF_kernel';%核函数类型 RBF_kernel lin_kernel poly_kernel wav_kernel
% kernelpara中第一个参数是惩罚系数
if strcmp(kernel,'RBF_kernel')
kernelpara=[1 1]; %rbf有一个核参数
elseif strcmp(kernel,'lin_kernel')
kernelpara=[1]; %线性没有核参数
elseif strcmp(kernel,'poly_kernel')
kernelpara=[1,1,1]; %多项式有2个核参数
elseif strcmp(kernel,'wav_kernel')
kernelpara=[1,1,1,1]; %小波核有3个核参数
end
%%
delm=dkelmtrain(P_train,T_train,h,lambda,TF,kernelpara,kernel);
T1=dkelmpredict(delm,kernelpara,kernel,P_train,P_train);
[~, J]=max(T1,[],2);
[~, J1]=max(T_train,[],2);
train_accuracy=sum(J==J1)/length(J)
figure
stem(J,'bo');hold on
plot(J1,'r*');
title('训练集分类结果')
legend('实际输出','期望输出')
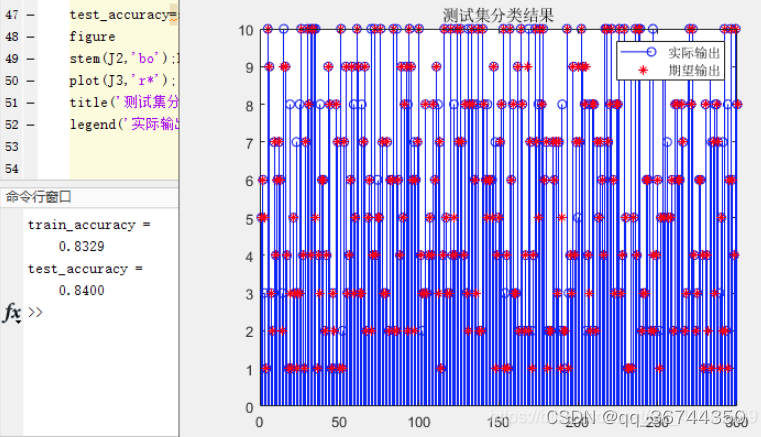
% 测试集;
T2=dkelmpredict(delm,kernelpara,kernel,P_test,P_train);
[~, J2]=max(T2,[],2);
[~, J3]=max(T_test,[],2);
test_accuracy=sum(J2==J3)/length(J2)
figure
stem(J2,'bo');hold on
plot(J3,'r*');
title('测试集分类结果')
legend('实际输出','期望输出')
PSO-DKELM分类,采用PSO优化DKELM(各隐含层节点数,正则化系数,顶层kelm的惩罚系数与核参数),如下,现在只需要设置几个隐含层、ELM-AE激活函数与顶层KELM的核函数类型即可。
%% 优化DKELM超参数,包括各隐含层节点数,正则化系数,顶层kelm的惩罚系数与核参数,
close all;clear;format compact;format short;clc;warning off
%%
load data_feature_fft
[train_x,train_ps]=mapminmax(train_X',-1,1);
test_x=mapminmax('apply',test_X',train_ps);
P_train = double(train_x)' ;
P_test = double(test_x)' ;
T_train = double(train_Y);
T_test = double(test_Y);
%% 参数设置
layers=3;%隐含层层数
TF='sig';%ELM-AE激活函数
%顶层核极限学习机参数
kernel='RBF_kernel';%核函数类型 RBF_kernel lin_kernel poly_kernel wav_kernel
%%
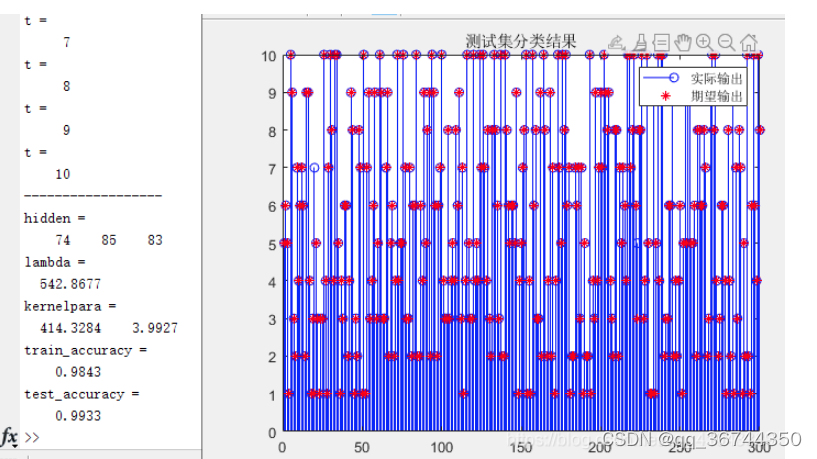
[x,trace,result]=psofordeepkelm(P_train,P_test,T_train,T_test,layers,TF,kernel); %优化DKELM超参数,包括各隐含层节点数,正则化系数,顶层kelm的惩罚系数与核参数
%将优化结果放到h中
figure
plot(trace)
title('适应度曲线')
xlabel('优化代数')
ylabel('适应度值')
hidden=x(1:layers) %各隐含层节点数
lambda=x(layers+1) %L2正则化系数
kernelpara=x(layers+2:end) %顶层kelm惩罚系数与核参数
%% 重新训练ML-KELM,看训练集误差
rng('default')
delm=dkelmtrain(P_train,T_train,hidden,lambda,TF,kernelpara,kernel);
T1=dkelmpredict(delm,kernelpara,kernel,P_train,P_train);
[~, J]=max(T1,[],2);
[~, J1]=max(T_train,[],2);
train_accuracy=sum(J==J1)/length(J)
figure
stem(J,'bo');hold on
plot(J1,'r*');
title('训练集分类结果')
legend('实际输出','期望输出')
% 测试集;
T2=dkelmpredict(delm,kernelpara,kernel,P_test,P_train);
[~, J2]=max(T2,[],2);
[~, J3]=max(T_test,[],2);
test_accuracy=sum(J2==J3)/length(J2)
figure
stem(J2,'bo');hold on
plot(J3,'r*');
title('测试集分类结果')
legend('实际输出','期望输出')
有需求请留言,添加微信公众号lieche650


















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











