







文章目录
本文翻译整理自 https://dzone.com/articles/chunking-strategies-for-optimizing-llms
1. 概述
LLM 通过生成类似人类的文本、回答复杂问题以及准确分析大量信息,改变了 NLP 领域。它们处理多样化查询和产生详细回答的能力,使它们在许多领域变得不可或缺,从客户服务到医学研究。然而,随着 LLM 扩展以处理更多数据,它们在管理长文档和高效检索最相关信息方面遇到了挑战。
尽管 LLM 擅长处理和生成类似人类的文本,但它们有一个有限的“上下文窗口”。这意味着它们一次只能在记忆中保持一定量的信息,这使得管理非常长的文档变得困难。此外,LLM 很难从大型数据集中快速找到最相关信息。除此之外,LLM 是在固定数据上训练的,所以随着新信息的出现,它们可能会变得过时。为了保持准确和有用,它们需要定期更新。
检索增强生成(Retrieval-augmented generation ,RAG)解决了这些挑战。RAG 工作流程中有许多组件,如查询、嵌入、索引等,本文重点阐述分块(Chunking)策略。
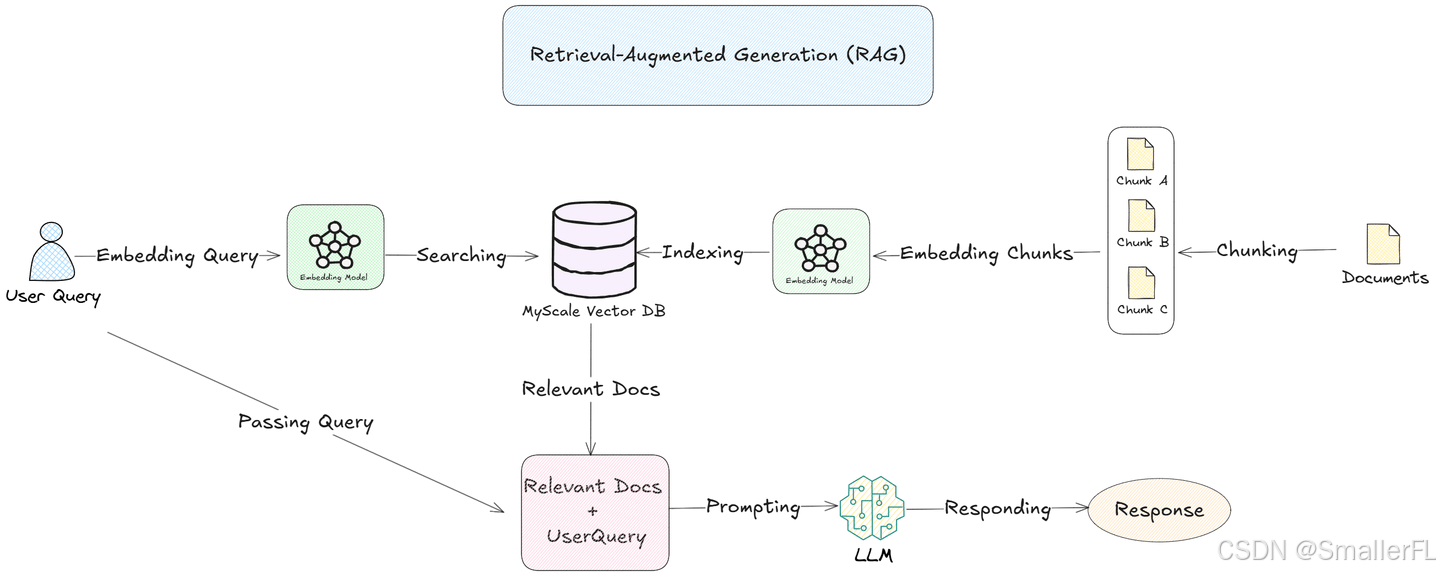
通过将文档分解成更小、有意义的段落,并将它们嵌入到向量数据库中,RAG 系统可以搜索并检索每个查询最相关的段落。这种方法允许 LLM 专注于特定信息,提高响应的准确性和效率。
2. 什么是分块(Chunking)
分块是将大数据源分解成更小、可管理的片段或“块”。这些块存储在向量数据库中,允许基于相似性进行快速有效的搜索。当用户提交查询时,向量数据库找到最相关的块并将它们发送给语言模型。这样,模型只需要关注最相关的信息,使其响应更快、更准确。
分块有助于语言模型更平滑地处理大型数据集,并通过缩小它需要查看的数据范围来提供精确的答案。
对于需要快速、精确答案的应用——如客户支持或法律文件搜索——分块是一个重要的策略,它提高了性能和可靠性。
以下是在RAG中使用的主要分块策略:
- 固定大小分块
- 递归分块
- 语义分块
- 代理分块
2.1 固定大小分块(Fixed-Size Chunking)
固定大小分块涉及将数据分成等大小的部分,使得处理大型文档变得更容易。
有时,开发人员会在块之间添加轻微的重叠,一个段落的一小部分在下一个段落的开头重复。这种重叠方法有助于模型在每个块的边界上保持上下文,确保关键信息不会丢失在边缘。这种策略特别适用于需要连续信息流的任务,因为它使模型能够更准确地解释文本,理解段落之间的关系,从而产生更连贯、更有上下文意识的响应。

上面的插图是固定大小分块的完美示例,每个块由独特的颜色表示。绿色部分表示块之间的重叠部分,确保模型在处理下一个块时能够访问一个块的相关上下文。
这种重叠提高了模型处理和理解全文的能力,在摘要或翻译等任务中表现更好,这些任务需要在块边界之间保持信息流。
2.2 递归分块(Recursive Chunking)
递归分块是一种通过反复将文本分解成子块来系统地将大量文本分成更小、可管理部分的方法。这种方法特别适合复杂或层次化的文档,确保每个段落保持连贯和上下文完整。该过程继续进行,直到文本达到适合有效处理的大小。
例如,考虑一个需要由具有有限上下文窗口的语言模型处理的冗长文档。递归分块首先将文档分成主要部分。如果这些部分仍然太大,该方法会进一步将它们分成子部分,并继续这个过程,直到每个块适合模型的处理能力。这种层次化的分解保留了原始文档的逻辑流程和上下文,使模型能够更有效地处理长文本。
在实践中,递归分块可以使用各种策略实现,例如根据标题、段落或句子进行分割,这取决于文档的结构和任务的具体要求。

在上图中,文本被分成四个块,每个块用不同的颜色表示,使用递归分块。文本被分解成更小、可管理的部分,每个块包含多达80个单词。块之间没有重叠。颜色编码有助于显示内容如何被分割成逻辑部分,使模型更容易处理和理解长文本,而不会丢失重要的上下文。
2.3 语义分块(Semantic Chunking)
语义分块是指根据内容的含义或上下文将文本分成块。这种方法通常使用机器学习或自然语言处理技术,如句子嵌入,来识别具有相似含义或语义结构的文本部分。

在上图中,每个块由不同的颜色表示——蓝色代表一类语义,黄色代表提另一类语义。这些块因为它们涵盖不同的想法而被分开。这种方法确保模型可以清楚地理解每个主题,而不将它们混合在一起。
2.4 代理分块(Agentic Chunking)
代理分块是这些策略中的强大策略。在这种策略中,我们利用 LLM(如GPT)作为分块过程中的代理。与手动确定如何分割内容不同,LLM 根据其理解输入主动组织或分割信息。LLM 确定将内容分割成可管理部分的最佳方法,受任务上下文的影响。
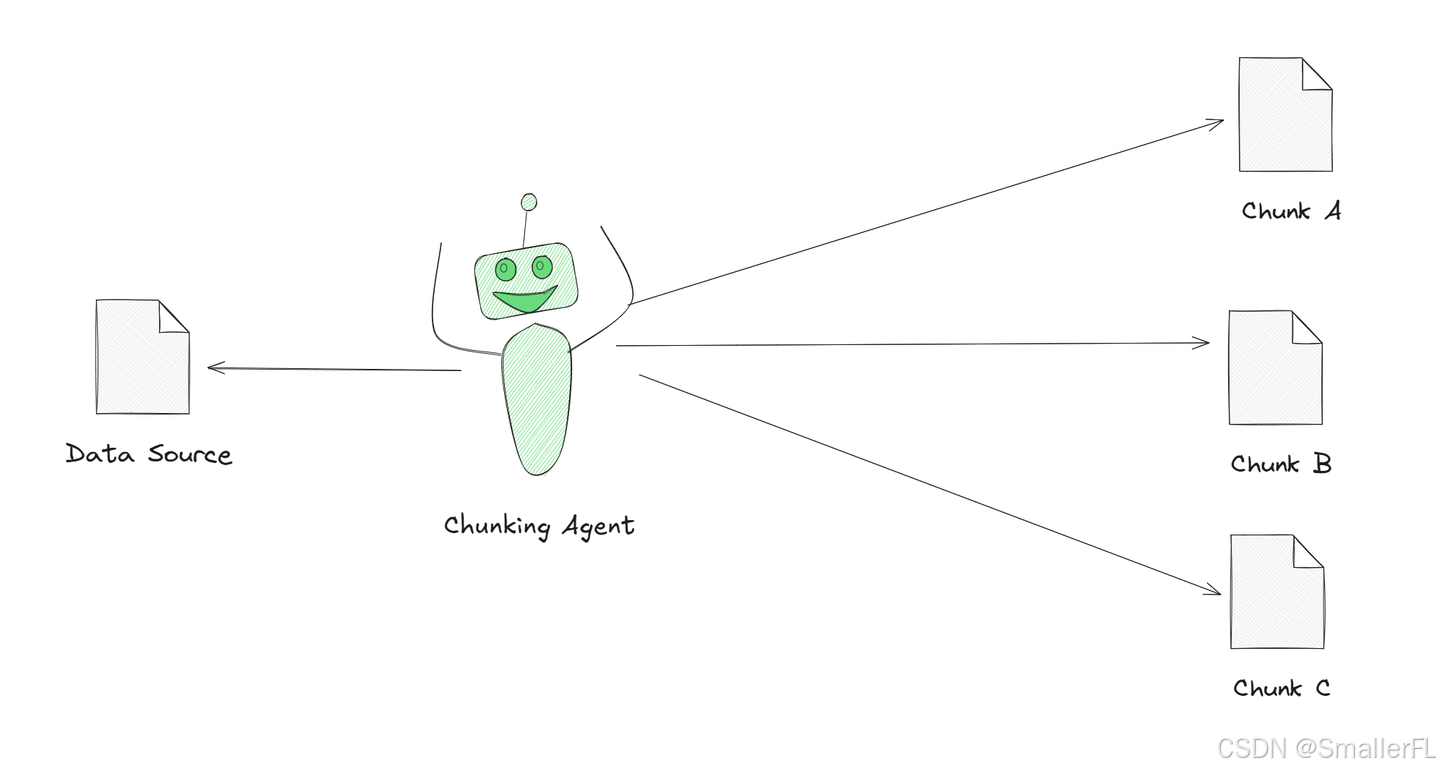
上图显示了一个分块代理将大型文本分解成更小、有意义的部分。这个代理由 AI 驱动,帮助它更好地理解文本并将其分割成有意义的块。这被称为代理分块,与简单地将文本切成相等部分相比,这是一种更智能的文本处理方式。
3. 总结
为了更容易理解不同的分块方法,下面的表格比较了固定大小分块、递归分块、语义分块和代理分块。它突出了每种方法的工作原理、何时使用它们以及它们的局限性。
| 分块类型 | 描述 | 方法 | 最佳用途 | 限制 |
|---|---|---|---|---|
| 固定大小分块 | 将文本分成等大小的块,不考虑内容。 | 根据固定的单词或字符限制创建块。 | 简单、结构化的文本,其中上下文连续性不太重要。 | 可能会丢失上下文或分割句子/想法。 |
| 递归分块 | 持续将文本分成更小的块,直到达到可管理的大小。 | 分层分割,如果部分太大,则进一步分解。 | 长、复杂或层次化的文档(例如,技术手册)。 | 如果部分太宽泛,可能仍会丢失上下文。 |
| 语义分块 | 根据含义或相关主题将文本分成块。 | 使用NLP技术,如句子嵌入,对相关内容进行分组。 | 上下文敏感任务,其中连贯性和主题连续性至关重要。 | 需要NLP技术;更复杂的实现。 |
| 代理分块 | 利用AI模型(如GPT)自主地将内容分成有意义的部分。 | 基于模型的理解和特定于任务的上下文的AI驱动分割。 | 内容结构变化复杂,AI可以优化分割的任务。 | 可能不可预测,需要调整。 |
分块策略和 RAG 对于增强 LLM 至关重要。分块有助于将复杂数据简化为更小、可管理的部分,从而更有效地处理,而 RAG 通过在生成工作流程中整合实时数据检索来改进 LLM。总的来说,这些方法允许 LLM 通过合并组织数据和活跃的最新信息,提供更精确、上下文敏感的回复。
参考
[1] https://dzone.com/articles/chunking-strategies-for-optimizing-llms
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤


















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











