







参考: 拜师资源博客,2021-09-06 机器学习中的数学基础–第四天
随机变量与概率分布
-
均匀分布:
每个事件的概率是一样的,例如骰子的六面,每一面的概率都是1/6
-
随机变量:
1.离散随机变量:投骰子时,当P(X=1)=1/6,此时x=1为, 随机变量具有可加性(P(X=1)和P(X=2)不会同时出现,可求P(X=1,2))
2.连续随机变量:坐标轴x轴0→1.
P(0≤x≤0.5)=1/2→P(X≤0.5)=1/2(CDF(Cumulative Distribution Function))→P(X≤θ)=θ(定义为F(θ)),对F(θ)求导之后得f(θ),f(θ)为概率密度(PDF(Probability Density Function)),P(θ1<X≤θ2)=F(θ2)-F(θ1)= ∫(θ1→θ2)f( θ)dθP(θ1<X≤θ2)=F(θ2)-F(θ1)= ∫(θ1→θ2)f( θ)dθ就是牛顿莱布尼茨公式,定义为:为一个连续函数在区间[a,b]上的定积分等于它的任意一个原函数在区间[a,b]上的增量
-
联合分布
 独立同分布(idd)
独立同分布(idd) -
伯努利分布
伯努利分布定义:X~B(n,p)(其中,X为成功次数,n为实验次数,p为成功概率) -
泊松分布
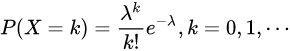
(λ=np),表示为某一段时间内某个事件发生的概率,(P(x=0)+P(x=1)…P(x=∞)=1)
贝叶斯定理
- 贝叶斯公式
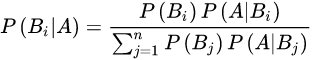
期望、方差与条件数学期望
- 期望:
在概率论和统计学中,一个离散性随机变量的期望值(或数学期望,亦简称期望,物理学中称为期待值)是试验中每次可能的结果乘以其结果概率的总和。换句话说,期望值像是随机试验在同样的机会下重复多次,所有那些可能状态平均的结果,便基本上等同“期望值”所期望的数。期望值可能与每一个结果都不相等。换句话说,期望值是该变量输出值的加权平均。期望值并不一定包含于其分布值域,也并不一定等于值域平均值。 - 方差:

- 条件数学期望:

大数定理

特征函数与中心极限定理
中心极限定理 (Central limit theorem, 简作 CLT) 是概率论中的一组定理。中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于标准正态分布。这组定理是数理统计学和误差分析的理论基础,指出了大量随机变量之和近似服从正态分布的条件。
统计学基本概念
- p-value:假定值,假设几率
- P(precosion)-R(recall)曲线:
P=TP/(TP+FP)(在预测正确中,真正正确的概率),
R=TP/(TP+FN)(在真正正确中,预测正确的概率) - ROC曲线:TPR(真阳率(True postive rate))-FPR(假阳率(False positive rate))
FPR=FP/(FP+TN)(所有负样本中有多少被预测为正例)
TPR=TP/(TP+FN)(等同于recall - AUC:AUC(Area Under Curve) 被定义为ROC曲线下的面积,因为ROC曲线一般都处于y=x这条直线的上方,所以取值范围在0.5和1之间,使用AUC作为评价指标是因为ROC曲线在很多时候并不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值,其值越大代表分类器效果更好
极大似然估计
最大后验估计
蒙特卡洛方法
砸点















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









