









【通俗理解】Transformer复杂度解析——从注意力机制到计算成本
关键词提炼
#Transformer #复杂度 #注意力机制 #自注意力 #序列长度 #特征维度 #计算成本 #时间复杂度 #空间复杂度 #模型优化
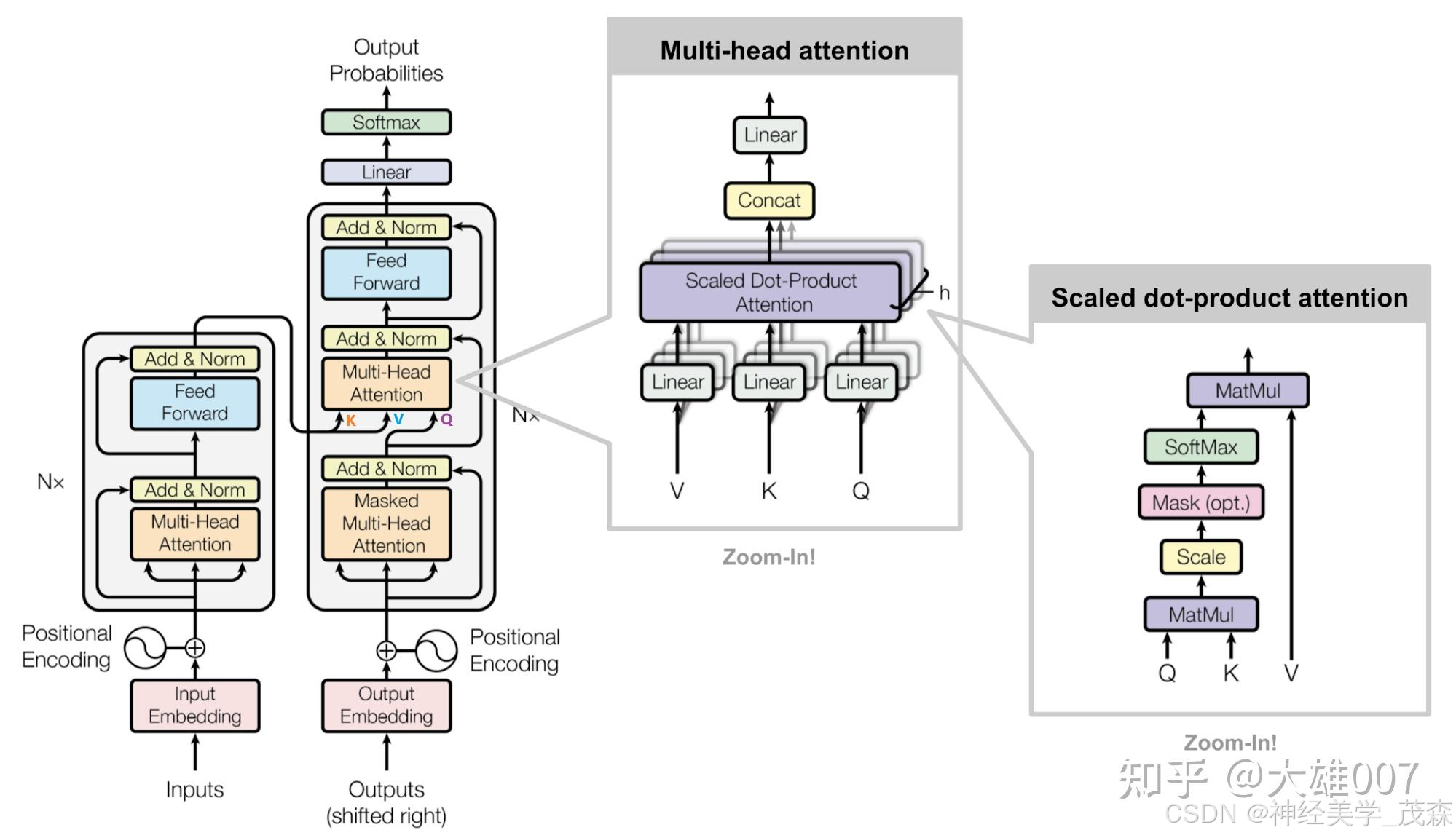
第一节:Transformer复杂度的类比与核心概念
1.1 Transformer复杂度的类比
Transformer的复杂度就像是一场盛大的舞会,其中的舞者(数据点)需要通过注意力机制来相互交流和互动。
舞会的热闹程度(复杂度)取决于舞者的数量(序列长度)和他们交流的复杂程度(特征维度)。

1.2 相似公式比对
- 线性复杂度: O ( n ) O(n) O(n),描述了一种简单的线性关系,适用于直接且不变的情况。
- Transformer复杂度: O ( n 2 ⋅ d ) O(n^2 \cdot d) O(n2⋅d),其中n是序列长度,d是特征维度,描述了一个更为复杂的二次关系,适用于Transformer中注意力机制的计算成本。

第二节:Transformer复杂度的核心概念与应用
2.1 核心概念
- 序列长度n:在Transformer中,序列长度指的是输入数据的长度,它决定了需要处理的数据点的数量。
- 特征维度d:特征维度是指每个数据点所包含的信息的丰富程度,它影响了处理每个数据点所需的计算量。
- 自注意力机制:自注意力机制是Transformer的核心,它允许每个数据点与其他所有数据点进行交互,从而捕捉到序列中的长距离依赖关系。
2.2 应用
- 模型优化:通过理解和分析Transformer的复杂度,我们可以对模型进行优化,例如通过减少序列长度或特征维度来降低计算成本。
- 计算资源分配:在实际应用中,了解Transformer的复杂度可以帮助我们更合理地分配计算资源,确保模型的训练和推理过程能够高效进行。
2.3 优势
- 量化分析:通过具体的公式和计算,我们可以量化Transformer的计算成本,为模型优化和资源分配提供明确的指导。
- 动态调整:根据实际应用场景的需求,我们可以动态地调整Transformer的复杂度,以达到最佳的性能和资源利用平衡。
2.4 与深度学习模型的类比
Transformer的复杂度在深度学习模型中扮演着“计算器”的角色,它能够帮助我们精确地计算出模型的计算成本,就像计算器能够帮助我们进行数学运算一样。
第三节:公式探索与推演运算
3.1 Transformer复杂度的基本形式
Transformer的复杂度主要由自注意力机制的计算成本决定,其基本形式为:
Complexity = O ( n 2 ⋅ d ) \text{Complexity} = O(n^2 \cdot d) Complexity=O(n2⋅d)
其中,n是序列长度,d是特征维度。
3.2 具体实例与推演
假设我们有一个序列长度为100,特征维度为512的Transformer模型,那么其自注意力机制的计算复杂度为:
Complexity = 10 0 2 ⋅ 512 = 5120000 \text{Complexity} = 100^2 \cdot 512 = 5120000 Complexity=1002⋅512=5120000
这是一个相对较大的计算量,说明该模型在处理长序列或高维度特征时可能会面临较高的计算成本。
3.3 与其他模型复杂度的对比
-
卷积神经网络(CNN):CNN的复杂度通常与输入数据的尺寸、卷积核的大小和数量有关,但其计算方式通常不涉及序列长度的二次方,因此在处理序列数据时可能相对更高效。
-
循环神经网络(RNN):RNN的复杂度主要与时间步长和隐藏层维度有关,虽然也涉及序列的处理,但其计算方式通常不涉及特征维度的直接乘法,因此在某些情况下可能比Transformer更高效。
第四节:公式推导与相似公式比对(扩展)
-
矩阵乘法复杂度 与 Transformer复杂度:
- 共同点:都涉及两个维度的乘法运算。
- 不同点:矩阵乘法复杂度是固定的两个矩阵的乘法,而Transformer复杂度涉及序列长度和特征维度的动态变化。
-
点积注意力复杂度 与 Transformer中的自注意力复杂度:
- 相似点:都涉及点积运算,即两个向量的对应元素相乘后求和。
- 差异:点积注意力通常用于两个向量之间的运算,而自注意力涉及序列中每个数据点与其他所有数据点的运算,因此复杂度更高。
第五节:核心代码与可视化
import numpy as np
import matplotlib.pyplot as plt
# 定义计算Transformer复杂度的函数
def transformer_complexity(n, d):
complexity = n**2 * d
print(f"Transformer complexity for sequence length {n} and feature dimension {d} is: {complexity}")
return complexity
# 示例:计算不同序列长度和特征维度下的Transformer复杂度
sequence_lengths = [10, 50, 100, 500]
feature_dimensions = [128, 512, 1024]
complexities = []
for n in sequence_lengths:
for d in feature_dimensions:
complexity = transformer_complexity(n, d)
complexities.append((n, d, complexity))
# 可视化结果
plt.figure(figsize=(10, 6))
for n, d, complexity in complexities:
plt.scatter([n], [complexity], label=f'Feature Dimension {d}')
plt.xlabel('Sequence Length n')
plt.ylabel('Transformer Complexity')
plt.title('Transformer Complexity vs Sequence Length and Feature Dimension')
plt.legend()
plt.grid(True)
plt.show()
print("Transformer complexity plot has been generated and displayed.")
这段代码计算了不同序列长度和特征维度下的Transformer复杂度,并绘制了复杂度随序列长度变化的散点图。通过可视化,我们可以直观地看到Transformer复杂度与序列长度和特征维度的关系。
输出内容:
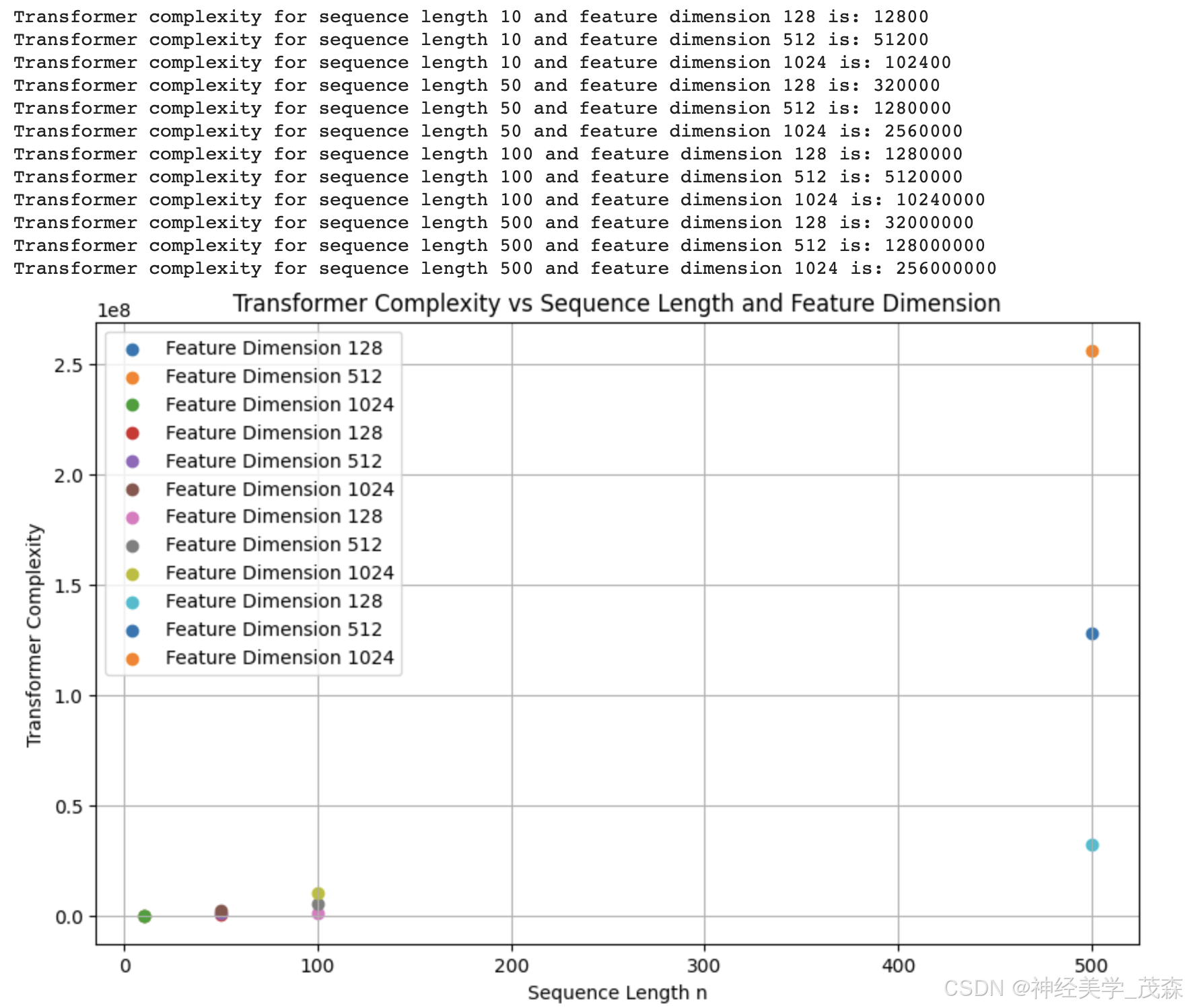



















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











