







前言
在阅读了一系列Activation Funtion论文之后,其中Dynamic Relu的论文提到了基于注意力机制的网络,因此先来看看经典的SE-Net的原理
Introduction
对于CNN,卷积核在局部感受野中将空间和通道信息融合得到信息组合.通过堆叠一系列非线性交错的卷积层和下采样,CNN能够获取具有全局感受野的分层模式,作为强大的图像描述。
最近的研究表明,网络的性能可以通过显式嵌入学习机制来提高,这有助于捕获空间相关性,而无需需要额外的监督。其中一种方法是由Inception推广的,这表明网络可以通过在其模块中嵌入多尺度过程来实现具有竞争力的准确性。
最近的工作试图更好地模拟空间依赖[1,31],并纳入空间注意[19]。
其中上述参考的论文如下
- [1]S. Bell, C. L. Zitnick, K. Bala, and R. Girshick. Inside- outside net: Detecting objects in context with skip pooling and
recurrent neural networks. InCVPR, 2016.1- [31]A. Newell, K. Y ang, and J. Deng. Stacked hourglass networks for human pose estimation. InECCV, 2016.1,2
- [19]M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In NIPS, 2015.1,2
该篇论文研究了网络结构设计的一个不同的方面-通道关系,通过引入一个新的结构单元,称之为“Squeeze-and-
Excitation” (SE) block。
作者目标是将卷积特征通道之间的相互依赖性显式地建模出来,以提高网络的表示能力。为了实现这一点,我们提出了一种机制,允许网络执行特征重新校准,通过该机制,网络可以学习使用全局信息来选择性地强调信息性特征,并抑制不太有用的特征。

SE-block的基本结构如上图所示。有如下定义:
对任何给定的变换
F
t
r
:
X
→
U
,
X
∈
R
H
′
×
W
′
×
C
′
,
U
∈
R
H
×
W
×
C
F_{tr}:X\to U,X\in \mathbb{R}^{H^{'}\times W^{'}\times C^{'}},U\in \mathbb{R}^{H\times W\times C}
Ftr:X→U,X∈RH′×W′×C′,U∈RH×W×C
以上给定的变换针对一个卷积或者一组卷积而言。
我们可以构造一个相应的SE块来执行特征重新校准,如下所示。
特征
U
U
U首先通过一个
s
q
u
e
e
z
e
squeeze
squeeze操作,该操作将空间维度上的特征映射聚合,生成通道descriptor。
该descriptor嵌入了通道特征响应的全局分布,使来自网络全局感受野的信息能够被其较低层利用。
然后经过一个
e
x
c
i
t
a
t
i
o
n
excitation
excitation操作,在该操作中,通过基于通道依赖性的self-gating机制为每个通道学习的样本特定激活控制每个通道的
e
x
c
i
t
a
t
i
o
n
excitation
excitation
然后对特征映射
U
U
U重新加权以生成SE-block的输出,然后将其直接输入后续的layers。
SE-network可以通过简单地堆叠SE building block的集合来生成。SE-block 也可以作为架构中任何深度中original block的替代。
SE-block在计算上是轻量级的,只会稍微增加模型的复杂性和计算负担。
使用SENets,作者赢得了2017年ILSVRC分类比赛的第一名。
表现最好的模型组合实现了2.251% top-5 error在ILSVRC测试集上。比前一年的winner提高了25%(前一年的winner的top-5 error是2.991%)
Related Work
Attention and gating mechanisms
从广义上讲,注意力可以被视为一种工具,使可用处理资源的分配偏向于输入信号中信息量最大的成分。它通常与gating功能(例如softmax或sigmoid)和sequential技术结合使用。(这里指的sequential技术没有深入了解,有兴趣看如下参考文献)
- S. Hochreiter and J. Schmidhuber. Long short-term memory.Neural computation, 1997.2
- M. F. Stollenga, J. Masci, F. Gomez, and J. Schmidhuber.Deep networks with internal selective attention through feedback
connections. In NIPS, 2014.2
在这些应用中,它通常用于表示更高层次抽象的一个或多个层之上,以便在不同的模式之间进行适配。
Related work的详细描述我没有全贴出来,原因是讲述的领域有点广,或者不太重要的描述,我们主要关注SE-block是怎么实现的。
Squeeze-and-Excitation Blocks
SE-block是一个计算单元,可以构造任何给定变换:
F
t
r
:
X
→
U
,
X
∈
R
H
′
×
W
′
×
C
′
,
U
∈
R
H
×
W
×
C
\textbf{F}_{tr}:\textbf{X}\to \textbf{U},\textbf{X}\in\mathbb{R}^{H^{'}\times W^{'}\times C^{'}},\textbf{U}\in\mathbb{R}^{H\times W\times C}
Ftr:X→U,X∈RH′×W′×C′,U∈RH×W×C
其中,
F
t
r
\textbf{F}_{tr}
Ftr是一个卷积算子,令
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
\textbf{V}=[\textbf{v}_1,\textbf{v}_2,...,\textbf{v}_C]
V=[v1,v2,...,vC]表示学习的滤波器核集,其中
v
c
v_c
vc指的是第c个滤波器参数。
F
t
r
\textbf{F}_{tr}
Ftr的输出可以写成
U
=
[
u
1
,
u
2
,
.
.
.
,
u
C
]
\textbf{U}=[\textbf{u}_1,\textbf{u}_2,...,\textbf{u}_C]
U=[u1,u2,...,uC],其中
u
c
=
v
c
∗
X
=
∑
s
=
1
C
′
v
c
s
∗
x
s
.
−
−
−
(
1
)
\textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1)
uc=vc∗X=s=1∑C′vcs∗xs.−−−(1)
这里∗表示卷积,
v
c
=
[
v
c
1
,
v
c
2
,
.
.
.
,
v
c
C
′
]
\textbf{v}_c=[\textbf{v}_c^1,\textbf{v}_c^2,...,\textbf{v}_c^{C^{'}}]
vc=[vc1,vc2,...,vcC′]和
X
=
[
x
1
,
x
2
,
.
.
.
,
x
C
′
]
\textbf{X}=[\textbf{x}^1,\textbf{x}^2,...,\textbf{x}^{C{'}}]
X=[x1,x2,...,xC′](简化符号,省略偏置项)
其中
v
c
s
v_c^s
vcs是一个二维的卷积核,表示
v
c
v_c
vc的一个通道,作用于
X
X
X对应的通道。由于输出是通过所有通道的求和产生的,因此通道依赖性是隐式嵌入到
v
c
v_c
vc中,但是这些依赖关系与滤波器捕获的空间相关性纠缠在一起。
我们的目标式确保网络能够提高其对信息特征的敏感性,以便它们可以被后续的转换利用,并抑制不太有用的特征。
我们建议通过显式建模通道相互依赖来实现这一点,在它们被馈送到下一个变换之前,在Squeeze和Excitation两个步骤中重新校准滤波器响应。图1显示了一个SE构建块的示意图。
Squeeze: Global Information Embedding
为了解决利用通道依赖性的问题,我们首先考虑信号到每个通道输出特征。每个学习过的滤波器都有一个局部感受野,因此每一个转换输出的单元 U U U是无法利用该感受野之外的上下文信息。
这里通俗的说可以有两种解释:
1.学习过的滤波器之间无法互相利用之间的信息,即如下公式中的 v c v_c vc之间无法通信。
2.每个转换输出的单元 U U U的公式如下:
u c = v c ∗ X = ∑ s = 1 C ′ v c s ∗ x s . − − − ( 1 ) \textbf{u}_c=\textbf{v}_c\ast \textbf{X}=\sum_{s=1}^{C^{'}}\textbf{v}_c^s\ast \textbf{x}^s.---(1) uc=vc∗X=s=1∑C′vcs∗xs.−−−(1)
对于转换输出的单元 u c \textbf{u}_c uc无法利用其他转换输出单元的上下文,只能捕获当前 v c \textbf{v}_c vc感受野的信息。
这个问题在感受野较小的网络低层变得更加严重。
为了缓解这个问题,我们建议将全局空间信息放入通道descriptor(原论文为channel descriptor,这里我不知道咋翻译,将原单词copy过来,防止引起歧义)中。这是通过使用全局平均池化生成通道统计信息来实现的。
形式上,统计量
z
∈
R
C
z\in \mathbb{R}^C
z∈RC是由压缩输出
U
U
U的空间维度
H
×
W
H\times W
H×W生成的,其中
z
\textbf{z}
z的第
c
c
c个元素可以被计算为:
z
c
=
F
s
q
(
u
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
,
−
−
−
(
2
)
z_c=\textbf{F}_{sq}(\textbf{u}_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j),---(2)
zc=Fsq(uc)=H×W1i=1∑Hj=1∑Wuc(i,j),−−−(2)
简洁地说:统计量 z c z_c zc就是第 c c c个输出单元的全局平均池化输出。这个信息是通道统计信息的一部分,作为每个通道的统计量。
作者的讨论: 变换输出 U \textbf{U} U可以解释为一个局部descriptors的集合,这些descriptors的统计量可以表达整个图像。在特征工程工作中,利用这些信息是很普遍的[35,38,49]。
[35] J. Sanchez, F. Perronnin, T. Mensink, and J. V erbeek. Image classification with the fisher vector: Theory and practice.RR-8209, INRIA, 2013.3
[38] L. Shen, G. Sun, Q. Huang, S. Wang, Z. Lin, and E. Wu.Multi-level discriminative dictionary learning with application to large scale image classification.IEEE TIP, 2015.3
[49] J. Y ang, K. Y u, Y . Gong, and T. Huang. Linear spatial pyramid matching using sparse coding for image classification.InCVPR, 2009.3
我们选择了最简单的全局平均池,注意到这里也可以使用更复杂的聚合策略。
Excitation: Adaptive Recalibration
为了利用squeeze操作(上一节提到的全局平均池化为一种squeeze)中聚集的信息,我们随后进行第二次操作,目标是完全捕获通道依赖性。
为了实现这一目标,该function必须符合两个准则:
- 首先,它必须是灵活的(特别是,它必须能够学习通道之间的非线性相互作用)
- 其次,它必须学会一种非互斥的关系,因为我们想要确保多个通道被允许被强调,而不是一次性激活。
为了满足这些标准,我们选择采用简单的sigmoid激活gating机制:
s
=
F
e
x
(
z,W
)
=
σ
(
g
(
z,W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
,
−
−
−
(
3
)
\textbf{s}=\textbf{F}_{ex}(\textbf{z,W})=\sigma(g(\textbf{z,W}))=\sigma(\textbf{W}_2\delta(\textbf{W}_1\textbf{z})),---(3)
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z)),−−−(3)
其中
δ
\delta
δ为ReLU激活函数,
W
1
∈
R
C
r
×
C
\textbf{W}_1\in\mathbb{R}^{\frac{C}{r}\times C}
W1∈RrC×C,
W
2
∈
R
C
×
C
r
\textbf{W}_2\in\mathbb{R}^{C\times\frac{C}{r}}
W2∈RC×rC
为了限制模型的复杂性并助于推广,我们通过围绕非线性形成两个完全连接(FC)层的bottleneck来参数化gating机制,换句话说,带有参数
W
1
\textbf{W}_1
W1和降维比
r
r
r的降维层(这个参数的选择后续会提到),接着一个ReLU,还有一个参数为
W
2
\textbf{W}_2
W2的升维层。
这里回顾下图1,注意输入输出的维度变化:
- Squeeze- F s q \textbf{F}_{sq} Fsq之后, U [ H × W × C ] U[H\times W\times C] U[H×W×C]经过全局平均池化得到特征输出维度为 [ 1 × 1 × C ] [1\times 1\times C] [1×1×C]
- Excitation- F e x \textbf{F}_{ex} Fex得到特征输出维度为 [ 1 × 1 × C ] [1\times 1\times C] [1×1×C], F e x \textbf{F}_{ex} Fex的详细操作中, W 1 \textbf{W}_1 W1表示第一个FC层的权重参数, W 2 \textbf{W}_2 W2表示第二个FC层的权重参数。
公式(3) F e x \textbf{F}_{ex} Fex的具体操作:FC+ReLU+FC+Sigmoid
- FC:论文里提到 W 1 \textbf{W}_1 W1是降维的,首先通过一个全连接层(FC)将统计量 z \textbf{z} z从特征维度 C C C降维到特征维度 C r \frac{C}{r} rC
- ReLU+FC:将1步骤得到的特征经过ReLU激活后再传入一个全连接层(FC),论文里提到 W 2 \textbf{W}_2 W2是升维的,该FC将特征维度 C r \frac{C}{r} rC升维到特征维度 C C C,相当于恢复到统计量 z z z的特征维度
- Sigmoid:将1,2步骤得到的特征经过Sigmid归一化成0-1的权重
上述提到的FC层的处理相当于对统计量 z \textbf{z} z的通道信息经过全连接层提取通道的相关性特征
block的最终输出是通过使用激活缩放变换输出
U
U
U来得到的:
x
~
c
=
F
s
c
a
l
e
(
u
c
,
s
c
)
=
s
c
⋅
u
c
,
−
−
−
(
4
)
\widetilde{\textbf{x}}_c=\textbf{F}_{scale}(\textbf{u}_c,s_c)=s_c\cdot \textbf{u}_c,---(4)
x
c=Fscale(uc,sc)=sc⋅uc,−−−(4)
其中
X
~
=
[
x
~
1
,
x
~
2
,
.
.
.
,
x
~
C
]
\widetilde{X}=[\widetilde{x}_1,\widetilde{x}_2,...,\widetilde{x}_C]
X
=[x
1,x
2,...,x
C]和
F
s
c
a
l
e
(
u
c
,
s
c
)
\textbf{F}_{scale}(\textbf{u}_c,s_c)
Fscale(uc,sc)是指特征映射
u
c
∈
R
H
×
W
\textbf{u}_c\in \mathbb{R}^{H\times W}
uc∈RH×W和标量
s
c
s_c
sc之间的通道乘积
这里scale操作中的 s c s_c sc指 F e x \textbf{F}_{ex} Fex的输出, u c \textbf{u}_c uc指未经squeeze和excitation的输出 U \textbf{U} U的一部分,用 s c s_c sc加权到 u c \textbf{u}_c uc的每个通道特征上,论文中用到的加权是乘法,逐通道乘以权重系数,完成在通道维度上引入attention机制
讨论:激活充当适应于特定输入描述 z \textbf{z} z的通道权重。在这一点上,SE-block本质上引入了动态输入条件,有助于提高特征辨别能力。
Inception和ResNet对应的网络结构


网络模型和计算复杂性
In aggregate,SE-ResNet-50 requires∼3.87GFLOPs, corresponding to a 0.26%relative increase over the original ResNet-50.In practice, with a training mini-batch of256images, a single pass forwards and backwards through ResNet-50 takes190ms, compared to209ms for SE-ResNet-50 (both timings are performed on a server with 8 NVIDIA Titan X GPUs).
我们认为,这是一个合理的开销,特别是因为在现有的GPU库中,全局池和小型内部产品操作的优化程度较低。此外,由于其对于嵌入式设备应用的重要性,我们还对每个模型的CPU推理时间进行了基准测试:对于224×224像素的输入图像,ResNet-50需要164毫秒,而SE-ResNet-50只需要167毫秒。SE块所需的少量额外计算开销因其对模型性能的贡献而被证明是合理的。
SE-ResNet-50引入了多250万参数量,相比原来包含了2500万参数量的ResNet-50而言。
实验






超参数取值
Reduction ratio:

The role of Excitation:

对于上图,作者在论文进行了解释
- 首先,在较低的层中,不同类别的分布几乎相同,例如SE_2_3。这表明在网络的早期阶段,通道特征的重要性很可能被不同类别共享。
- 然而,有趣的是,第二个观察结果是,在更深的深度,每个通道的值变得更加特定于类别,因为不同的类别表现出对特征的区别性值的不同偏好,例如SE_4_6和SE_5_1。
- 这两个观察结果与以前工作[23,50]中的发现是一致的,即较低层的特征通常更一般(即在分类的上下文中与类别无关),而较高层的特征具有更大的特异性。
[23] H. Lee, R. Grosse, R. Ranganath, and A. Y . Ng. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. InICML, 2009.8
[50] J. Y osinski, J. Clune, Y . Bengio, and H. Lipson. How transferable are features in deep neural networks? InNIPS, 2014.8
- 因此,表示学习受益于SE-block诱导的重新校准,这自适应地促进了特征提取和适应化到需要的程度。
- 最后,我们在网络的最后阶段观察到了一个略有不同的现象。SE_5_2呈现出一种有趣的趋向于饱和状态,在这种状态下,大多数激活接近于1,其余的接近于0。在所有激活取值1时,该块将成为标准残差块。在SE53的网络末端(紧随其后的是在分类器之前的全局池化),类似的模式出现在不同的类上,直到规模上的微小变化(这可以通过分类器进行调整)。
- 这表明SE_5_2和SE_5_3在向网络提供重新校准方面不如先前块重要。这一发现与第四节的实证研究结果是一致的,该调查结果表明,通过去除最后一级的SE块可以显著减少总体参数计数,而性能只会有轻微的损失。
结论
在本文中,我们提出了SE块,这是一种新的结构单元,旨在通过使网络执行动态通道特征重新校准来提高网络的表征能力。大量的实验证明了SENets的有效性,在多个数据集上实现了最先进的性能。此外,它们还提供了一些对先前体系结构在建模通道特征依赖方面的局限性的见解,我们希望这对其他需要强区分特征的任务是有用的。最后,SE块所诱导的特征重要性可能有助于网络剪枝压缩等相关领域的研究。
一些理解
论文认为在Excitation操作中用两个全连接层比直接用一个全连接层的好处在于:1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;2)极大地减少了参数量和计算量。
源码
SE-ResNet代码:
import torch
from torch import nn
from torchvision.models import resnet
from torchsummary import summary
# 这个模型是将SE模块加入每个ResBlock中了,还可以只加在模型开头和结尾,到底是怎么加入模型还是要看实验结果的
def conv3x3(in_channel, out_channel, stride=1, padding=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=padding, bias=False)
def conv1x1(in_channel, out_channel, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, bias=False)
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
# https://github.com/moskomule/senet.pytorch/blob/master/senet/se_resnet.py
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size() # x=[b,256,56,56]
y = self.avg_pool(x).view(b, c) # self.avg_pool(x)=>[b,256,1,1] .view=>[b,256]
y = self.fc(y).view(b, c, 1, 1) # self.fc(y)=>[b,256] .view=>[b,256,1,1]
return x * y.expand_as(x) # 复制[b,256,1,1] => [b,256,56,56]
class SE_BasicBlock(nn.Module):
# resnet18 + resnet34(resdual1) 实线残差结构+虚线残差结构
expansion = 1 # 残差结构中主分支的卷积核个数是否发生变化(倍数) 第二个卷积核输出是否发生变化
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
"""
: params: in_channel=第一个conv的输入channel
: params: out_channel=第一个conv的输出channel
: params: stride=中间conv的stride
: params: downsample=None:实线残差结构/Not None:虚线残差结构
"""
super(SE_BasicBlock, self).__init__()
self.conv1 = conv3x3(in_channel=in_channel, out_channel=out_channel, stride=stride)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
self.se = SELayer(out_channel)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
out += identity
out = self.relu(out)
return out
class SE_Bottleneck(nn.Module):
# resnet50+resnet101+resnet152(resdual2) 实线残差结构+虚线残差结构
expansion = 4 # 残差结构中主分支的卷积核个数是否发生变化(倍数) 第三个卷积核输出是否发生变化
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
"""
: params: in_channel=第一个conv的输入channel
: params: out_channel=第一个conv的输出channel
: params: stride=中间conv的stride
resnet50/101/152:conv2_x的所有层s=1 conv3_x/conv4_x/conv5_x的第一层s=2,其他层s=1
: params: downsample=None:实线残差结构/Not None:虚线残差结构
"""
super(SE_Bottleneck, self).__init__()
# 1x1卷积一般s=1 p=0 => w、h不变 卷积默认向下取整
self.conv1 = conv1x1(in_channel=in_channel, out_channel=out_channel, stride=1)
self.bn1 = nn.BatchNorm2d(out_channel)
# ----------------------------------------------------------------------------------
# 3x3卷积一般s=2 p=1 => w、h /2(下采样) 3x3卷积一般s=1 p=1 => w、h不变
self.conv2 = conv3x3(in_channel=out_channel, out_channel=out_channel, stride=stride)
self.bn2 = nn.BatchNorm2d(out_channel)
# ---------------------------------------------------------------------------------
self.conv3 = conv1x1(in_channel=out_channel, out_channel=out_channel * self.expansion, stride=1)
self.bn3 = nn.BatchNorm2d(out_channel * self.expansion)
# ----------------------------------------------------------------------------------
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.se = SELayer(out_channel * self.expansion)
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out)
out += identity
out = self.relu(out)
return out
class SE_ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000):
"""
: params: block=BasicBlock/Bottleneck
: params: blocks_num=每个layer中残差结构的个数
: params: num_classes=数据集的分类个数
"""
super(SE_ResNet, self).__init__()
self.in_channel = 64 # in_channel=每一个layer层第一个卷积层的输出channel/第一个卷积核的数量
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 池化默认向下取整
# 第1个layer的虚线残差结构只需要改变channel,长、宽不变 所以stride=1
self.layer1 = self._make_layer(block, blocks_num[0], channel=64, stride=1)
# 第2/3/4个layer的虚线残差结构不仅要改变channel还要将长、宽缩小为原来的一半 所以stride=2
self.layer2 = self._make_layer(block, blocks_num[1], channel=128, stride=2)
self.layer3 = self._make_layer(block, blocks_num[2], channel=256, stride=2)
self.layer4 = self._make_layer(block, blocks_num[3], channel=512, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # AdaptiveAvgPool2d 自适应池化层 output_size=(1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 凯明初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, block_num, channel, stride=1):
"""
: params: block=BasicBlock/Bottleneck 18/34用BasicBlock 50/101/152用Bottleneck
: params: block_num=当前layer中残差结构的个数
: params: channel=每个convx_x中第一个卷积核的数量 每一个layer的这个参数都是固定的
: params: stride=每个convx_x中第一层中3x3卷积层的stride=每个convx_x中downsample(res)的stride
resnet50/101/152 conv2_x=>s=1 conv3_x/conv4_x/conv5_x=>s=2
"""
downsample = None
# in_channel:每个convx_x中第一层的第一个卷积核的数量
# channel*block.expansion:每一个layer最后一个卷积核的数量
# res50/101/152的conv2/3/4/5_x的in_channel != channel * block.expansion永远成立,所以第一层必有downsample(虚线残差结构)
# 但是conv2_x的第一层只改变channel不改变w/h(s=1),而conv3_x/conv4_x/conv5_x的第一层不仅改变channel还改变w/h(s=2下采样)
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion)
)
layers = []
# 第一层(含虚线残差结构)加入layers
layers.append(block(self.in_channel, channel, stride=stride, downsample=downsample))
# 经过第一层后channel变了
self.in_channel = channel * block.expansion
# res50/101/152的conv2/3/4/5_x除了第一层有downsample(虚线残差结构),其他所有层都是实现残差结构(等差映射)
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel)) # channel在Bottleneck变化:512->128->512
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
def se_resnet18(num_classes=5):
return SE_ResNet(SE_BasicBlock, [2, 2, 2, 2], num_classes=num_classes)
def se_resnet34(num_classes=5):
# 预训练权重 https://download.pytorch.org/models/resnet34-333f7ec4.pth
return SE_ResNet(SE_BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def se_resnet50(num_classes=5):
# 预训练权重 https://download.pytorch.org/models/resnet50-19c8e357.pth
return SE_ResNet(SE_Bottleneck, [3, 4, 6, 3], num_classes=num_classes)
def se_resnet101(num_classes=5):
# 预训练权重 https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return SE_ResNet(SE_Bottleneck, [3, 4, 23, 3], num_classes=num_classes)
def se_resnet152(num_classes=5):
return SE_ResNet(SE_Bottleneck, [3, 8, 36, 3], num_classes=num_classes)
if __name__ == '__main__':
# 权重测试
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
model = se_resnet50().to(device)
print(model)
summary(model, (3, 224, 224)) # params:26,033,221 Total Size (MB): 428.90
个人实验
数据集采用花分类,取其中5类,3700多张图片,超参跟论文差不多,模型取SE2016ResNet50,SEResNet50和ResNet50对比
batch-size设为32,epoch设为50,实验设备RTX3060 12GB
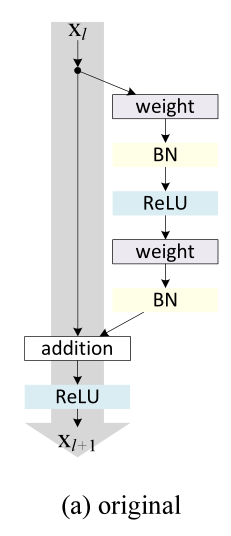
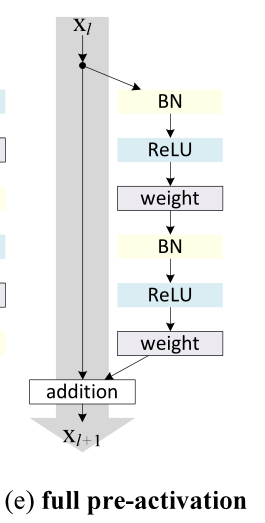
以上图(a)指的是原始的2015ResNet的结构,图(e)指的是2016ResNet结构

















 1857
1857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









