







1. 论文思想
在之前的经典分类论文中,作者么着力创新的点是“网络层次结构”,那么网络层中的channel有没有什么可以改进的呢?这篇论文正是从这点出发提出了一种新的结构SE(Squeeze-and-Excitation)块,从而构建了SENets。SENets在ILSVRC 2017分类中赢得了第一名,并将top-5错误率显著减少到2.251%,相对于2016年的获胜成绩取得了大约25%的相对改进。
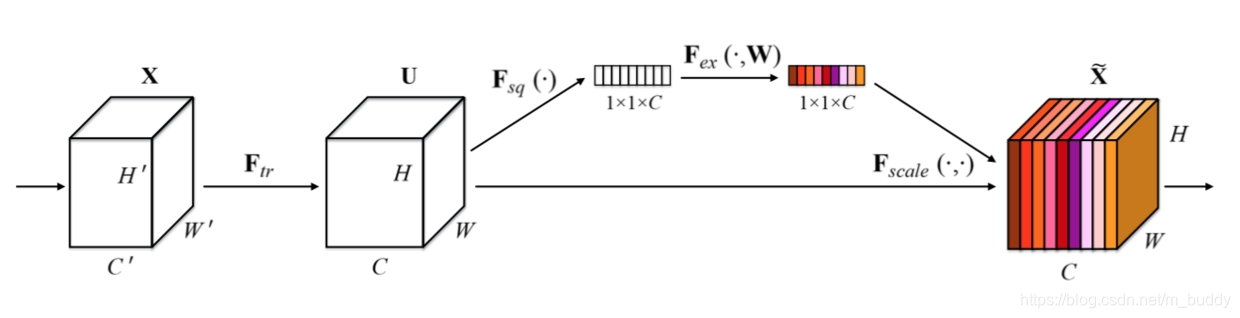
上图中是SE块的基本结构,对于任何给定的变换
F
t
r
:
X
→
U
,
X
∈
R
W
‘
×
H
‘
×
C
‘
,
U
∈
R
W
×
H
×
C
F_{tr}:X→U, X \in R^{W^{‘}×H^{‘}×C^{‘}},U \in R^{W×H×C}
Ftr:X→U,X∈RW‘×H‘×C‘,U∈RW×H×C,(例如卷积或一组卷积),我们可以构造一个相应的SE块来执行特征重新校准,如下所示。特征
U
U
U首先通过squeeze操作,该操作跨越空间维度
W
×
H
W×H
W×H聚合特征映射来产生通道描述符。这个描述符嵌入了通道特征响应的全局分布,使来自网络全局感受野的信息能够被其较低层利用。这之后是一个excitation操作,其中通过基于通道依赖性的自门机制为每个通道学习特定采样的激活,控制每个通道的激励。然后特征映射
U
U
U被重新加权以生成SE块的输出,然后可以将其直接输入到随后的层中。
2. SE块
在上面的那幅图中看到输入
X
X
X到
U
U
U之间存在变换
F
t
r
F_{tr}
Ftr,在这里可以将变换
F
t
r
F_{tr}
Ftr看成是一个卷积操作。使用
V
=
[
v
1
,
v
2
,
…
,
v
C
]
V=[v_1, v_2, \dots, v_C]
V=[v1,v2,…,vC]表示学习的一组滤波器的核,将
F
t
r
F_{tr}
Ftr的输出协作
U
=
[
u
1
,
u
2
,
…
,
u
C
]
U=[u_1, u_2, \dots, u_C]
U=[u1,u2,…,uC],它里面的每个元素是通过下面的方式计算出来的
u
c
=
v
c
∗
X
=
∑
s
=
1
C
‘
v
c
s
∗
x
s
u_c=v_c*X=\sum_{s=1}^{C^{‘}}v_c^s * x^s
uc=vc∗X=s=1∑C‘vcs∗xs
这里
∗
*
∗代表卷积,
v
c
=
[
v
c
1
,
v
c
2
,
…
,
v
c
C
‘
]
v_c=[v_c^1, v_c^2, \dots, v_c^{C^{‘}}]
vc=[vc1,vc2,…,vcC‘],
X
=
[
x
1
,
x
2
,
…
,
x
C
‘
]
X=[x^1, x^2, \dots,x^{C^{‘}}]
X=[x1,x2,…,xC‘]。这里
v
c
s
v_c^s
vcs是2D空间核,因此表示
v
c
v_c
vc的一个单通道,作用于对应的通道
X
X
X。由于输出是通过所有通道的和来产生的,所以通道依赖性被隐式地嵌入到
v
c
v_c
vc中,但是这些依赖性与滤波器捕获的空间相关性纠缠在一起。我们的目标是确保能够提高网络对信息特征的敏感度,以便后续转换可以利用这些功能,并抑制不太有用的功能。我们建议通过显式建模通道依赖性来实现这一点,以便在进入下一个转换之前通过两步重新校准滤波器响应,两步为:squeeze和excitation。
2.1 Sequence 全局信息嵌入
为了解决利用通道依赖性的问题,我们首先考虑输出特征中每个通道的信号。每个学习到的滤波器都对局部感受野进行操作,因此变换输出
U
U
U的每个单元都无法利用该区域之外的上下文信息。在网络较低的层次上其感受野尺寸很小,这个问题变得更严重。
为了减轻这个问题,我们提出将全局空间信息压缩成一个通道描述符。这是通过使用全局平均池化生成通道统计实现的。形式上,统计
z
∈
R
C
z \in R^C
z∈RC是通过在空间维度
W
×
H
W×H
W×H上收缩
U
U
U生成的,其中
z
z
z的第
c
c
c个元素通过下式计算:
z
c
=
F
s
q
(
u
c
)
=
1
W
×
H
∑
i
=
1
W
∑
j
=
1
H
u
c
(
I
,
j
)
z_c=F_{sq}(u_c)=\frac{1}{W×H}\sum_{i=1}^{W} \sum_{j=1}^{H}u_c(I,j)
zc=Fsq(uc)=W×H1i=1∑Wj=1∑Huc(I,j)
转换输出
U
U
U可以被解释为局部描述子的集合,这些描述子的统计信息对于整个图像来说是有表现力的。
2.2 Excitation:自适应重新校正
为了利用压缩操作中汇聚的信息,我们接下来通过第二个操作来全面捕获通道依赖性。为了实现这个目标,这个功能必须符合两个标准:第一,它必须是灵活的(特别是它必须能够学习通道之间的非线性交互);第二,它必须学习一个非互斥的关系,因为独热激活相反,这里允许强调多个通道。为了满足这些标准,我们选择采用一个简单的门机制,并使用sigmoid激活:
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s=F_{ex}(z, W)=\sigma (g(z, W))=\sigma (W_2\delta (W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
其中
σ
\sigma
σ是指ReLU函数,
W
1
∈
R
C
r
×
C
W_1\in R^{\frac{C}{r}×C}
W1∈RrC×C和
W
2
∈
R
C
×
C
r
W_2\in R^{C×\frac{C}{r}}
W2∈RC×rC。为了限制模型复杂度和辅助泛化,我们通过在非线性周围形成两个全连接(FC)层的瓶颈来参数化门机制,即降维层参数为
W
1
W_1
W1,降维比例为
r
r
r(我们把它设置为16),一个ReLU,然后是一个参数为
W
2
W_2
W2的升维层。块的最终输出通过重新调节带有激活的变换输出
U
U
U得到:
x
c
^
=
F
s
c
a
l
e
(
u
c
,
s
c
)
=
s
c
⋅
u
c
\hat{x_c}=F_{scale}(u_c, s_c)=s_c \cdot u_c
xc^=Fscale(uc,sc)=sc⋅uc
其中
X
^
=
[
x
1
^
,
x
2
^
,
…
,
x
C
^
]
\hat{X}=[\hat{x_1},\hat{x_2},\dots,\hat{x_C}]
X^=[x1^,x2^,…,xC^]和
F
s
c
a
l
e
(
u
c
,
s
c
)
F_{scale}(u_c,s_c)
Fscale(uc,sc)指的是特征映射
u
c
∈
R
W
×
H
u_c\in R^{W×H}
uc∈RW×H和标量
s
c
s_c
sc之间的对应通道乘积。
激活作为适应特定输入描述符
z
z
z的通道权重。在这方面,SE块本质上引入了以输入为条件的动态特性,有助于提高特征辨别力。
2.3 使用示例
在上面的第一幅图中已经给出了普通的串联卷积中使用SE块的例子,那么在比较经典的inception与ResNet结构中如何修改网络结构呢?下面给出在inception结构中使用SE之后的结构
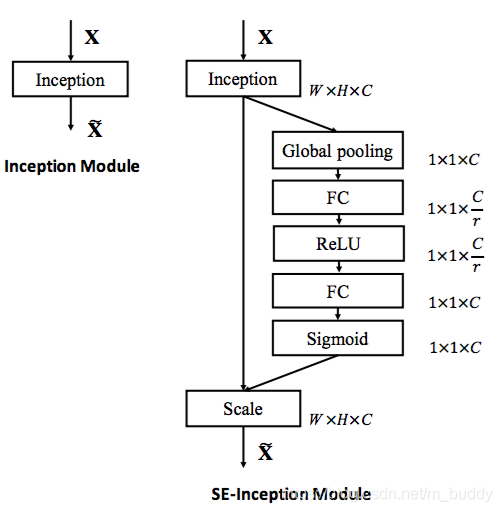
接下来是ResNet中:
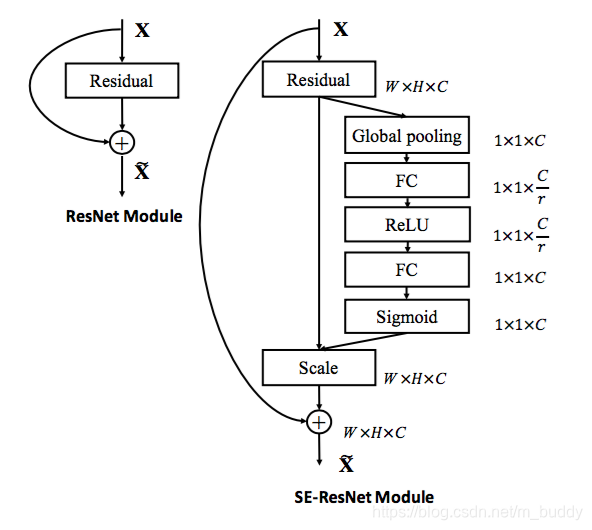
3. Caffe中使用
作者在github上给出了这个网络的实现层,地址为:链接。使用也比较简单,将src\caffe\layers下的axpy_layer.*拷贝到你所使用的caffe的对应位置处,再将include\caffe\layers下的axpy_layer.hpp拷贝到caffe对应的位置处,这里不需要修改caffe.proto。然后重新编译caffe就可以来了。
使用的时候的网络定义例子:
layer {
name: "conv3_1"
type: "Axpy"
bottom: "conv3_1_1x1_up"
bottom: "conv3_1_1x1_increase"
bottom: "conv3_1_1x1_proj"
top: "conv3_1"
}
再来看看它的源代码,其实它的源代码很简单,一个hpp与cpp文件就完事。内容也是遵循如下公式,这里就不多说了。
/**
* @param Formulation:
* F = a * X + Y
* Shape info:
* a: N x C --> bottom[0]
* X: N x C x H x W --> bottom[1]
* Y: N x C x H x W --> bottom[2]
* F: N x C x H x W --> top[0]
*/
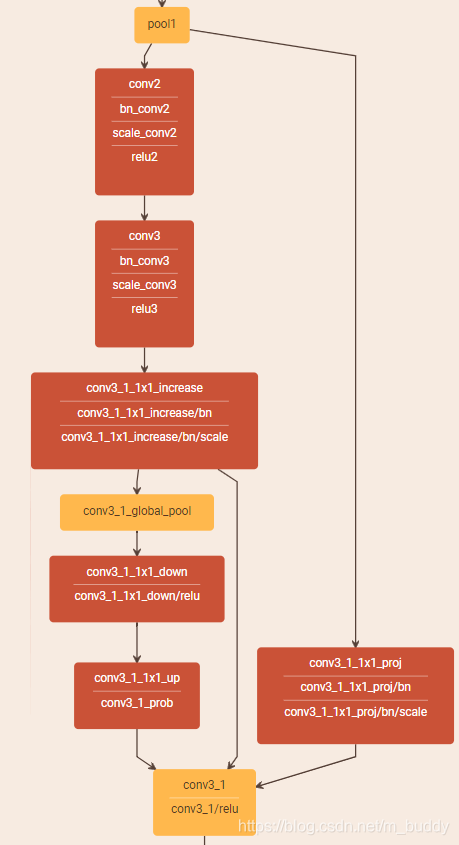
下面这幅是我使用的时候绘制出的SE块结构,上面说到的a, X, Y就是下面Axpy层从左到右输入的三个箭头。
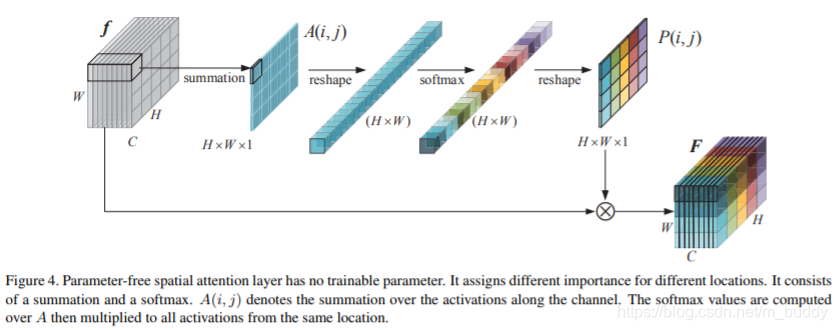
PS:这里补充一下spatial上的attention。在上面提到了如何在channel上做类似于attention的操作,那么在spatial上是怎么做的呢?下面的这幅图就解释得很清楚了,来源文章:Parameter-Free Spatial Attention Network for Person Re-Identification















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









