






常用生物学数据库:
1 大型数据库
(1)NCBI:NCBI 提供了各种生物信息学资源,包括基因组注释、基因组浏览器等工具,
(2)UniProt:整合了多种来源的蛋白质序列和注释信息。
(3)KEGG:是一个帮助研究人员了解生物代谢途径、信号通路和细胞过程的数据库,提供了多种分析和可视化工具
2 专用数据库
(1)miRBase数据库专注于 miRNA 序列和注释,提供了多种物种的 miRNA 序列,以及 miRNA 基因组定位、文献引用和实验验证等相关信。
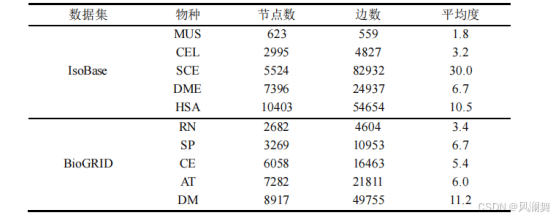
(2)IsoBase是一个关注特定物种直系同源的数据库,通过人工的方式从多个生物数据库中筛选出可信度较高的蛋白质及相互作用,是网络比对领域常用的数据集之一。
(3)NAPAbench2合成网络数据库。常用来作为PPI NA 合成网络数据库使用。
3 工具:
(1)Cytoscape,输入图的节点对信息,生成图的可视化,用的较多。
(2)Networkx,Python库,包括大量有关图论的方法和函数,如获取当前图的最大degree,聚类系数,直径等信息。
(3)STRING和 BioGRID则分别提供了蛋白质相互作用和相互作用网络方面的数据和工具,有助于预测和分析蛋白质相互作用网络。
4 常用数据库的详细情况:
(1)IsoBase数据库中的网络包括:家鼠(M.musculus,MUS),线虫(C.elegans,CEL),啤酒酵母(S.cerevisiae,SCE),果蝇(D.melanogaster,DME)和人类(H.sapiens,HSA)。
(2)BioGRID数据库中的网络包括:褐家鼠(R.norvegicus,RN)粟酒裂殖酵母(S.pombe,SP),秀丽隐杆线虫(C.elegans, CE),拟南芥(A.thaliana,AT),黑腹果蝇(D.melanogaster,DM)四种生物网络。

















 5016
5016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









