







 本文探讨了数据预处理的重要性,包括数值特征的归一化和类别特征的编码,如One-hot编码。提到了高维组合特征的处理策略和寻找组合特征的方法,并介绍了文本表示模型,如词袋模型、TF-IDF和Word2Vec。Word2Vec的CBOW和Skip-gram模型被提及,以及它们在处理文本数据时的作用。此外,还讨论了在图像数据不足时采用的迁移学习、生成对抗网络等方法。
本文探讨了数据预处理的重要性,包括数值特征的归一化和类别特征的编码,如One-hot编码。提到了高维组合特征的处理策略和寻找组合特征的方法,并介绍了文本表示模型,如词袋模型、TF-IDF和Word2Vec。Word2Vec的CBOW和Skip-gram模型被提及,以及它们在处理文本数据时的作用。此外,还讨论了在图像数据不足时采用的迁移学习、生成对抗网络等方法。
数据和特征是“米”,模型和算法则是“巧妇”。
数据和特征决定了结果的上限,模型和算法的选择以及优化逐步接近这个上限。
两种常用的数据类型:
(1)结构化数据:每一行数据表示一个样本信息
(2)非结构化数据:主要包括文本、图像、音频、视频数据
一、特征归一化
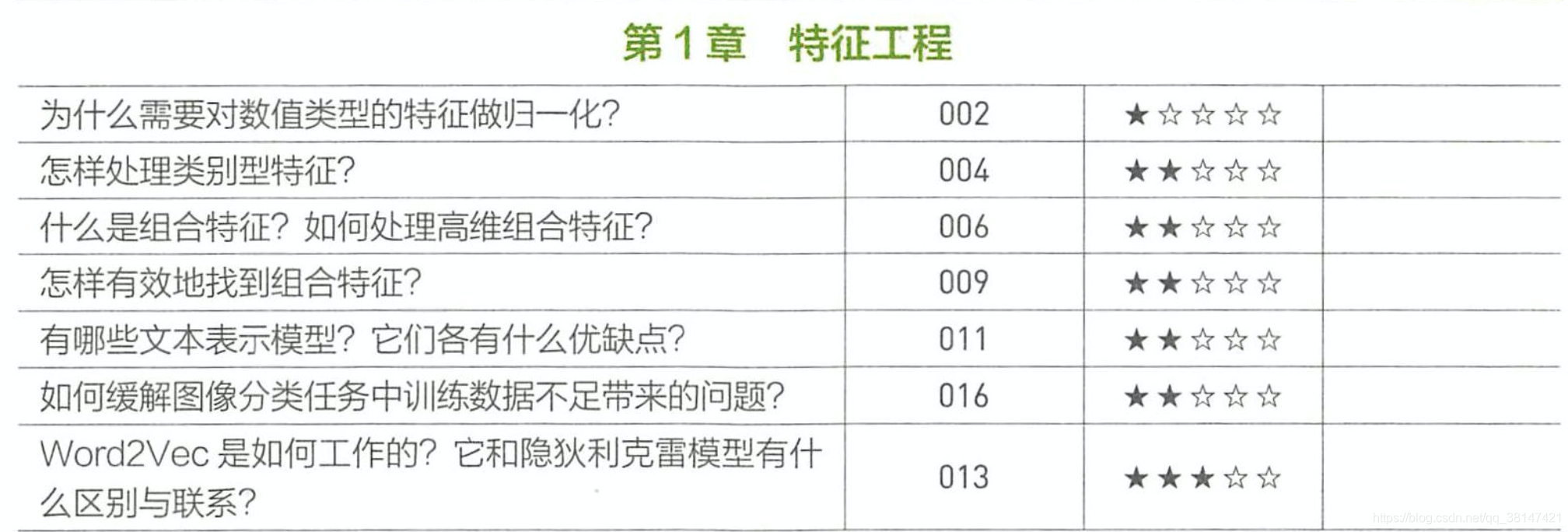
1、为什么需要对数值类型的特征做归一化?
归一化之后,在相同的学习率下,各个特征的更新速度会变得一致,可以更快的通过梯度下降找到最优解。常用两种归一化:Min-Max 归一化和零均值归一化。
但也并不是所有的模型都需要对数据归一化,比如决策树C4.5,决策树的分裂依据是信息增益,但信息增益跟特征是够归一化无关,所以归一化并不会改变样本在特征x上的信息增益。

二、类别型特征

1、在对数据进行预处理时,应该怎样处理类别型特征?
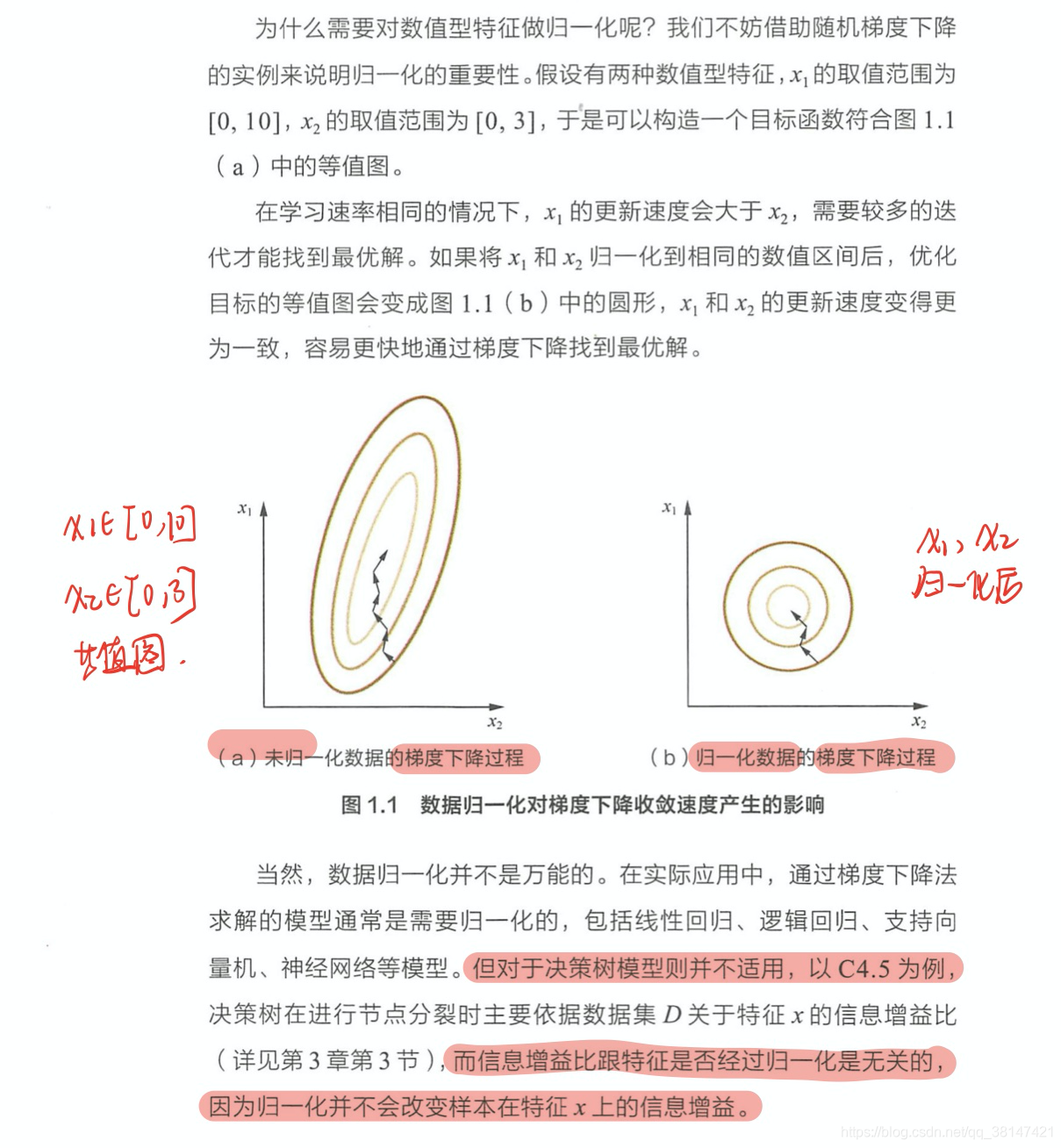
序号编码(Ordinal Encoding)、独热编码(One-hot Encoding)、二进制编码(Binary Encoding)
对于One-hot编码,(1)使用稀疏向量节省空间(2)配合特征选择来降低维度。补充:(为什么呢?因为高维度特征会带来三个问题。第一:在KNN算法中,高维空间下两点距离很难得到有效的衡量。第二:逻辑回归模型中,参数的数量会随着维度高而多,会引起过拟合。第三:通常只有部分维度对分类、预测有帮助。)


三、高维组合特征的处理
(待补充)
四、组合特征

1、怎样有效地找到组合特征?
(待总结)
五、文本表示模型
文本是非结构化数据。
如何表示文本数据一直是机器学习领域内的一个很重要的研究方向。
1、有哪些文本表示模型?它们各有什么优缺点?
词袋模型(Bag of words)、TF-IDF(Term Frequency-Inverse Document Frequency)、主题模型(Topic Model)、词嵌入模型(Word Embedding)




word2vec是word embedding的一种。
六、Word2Vec
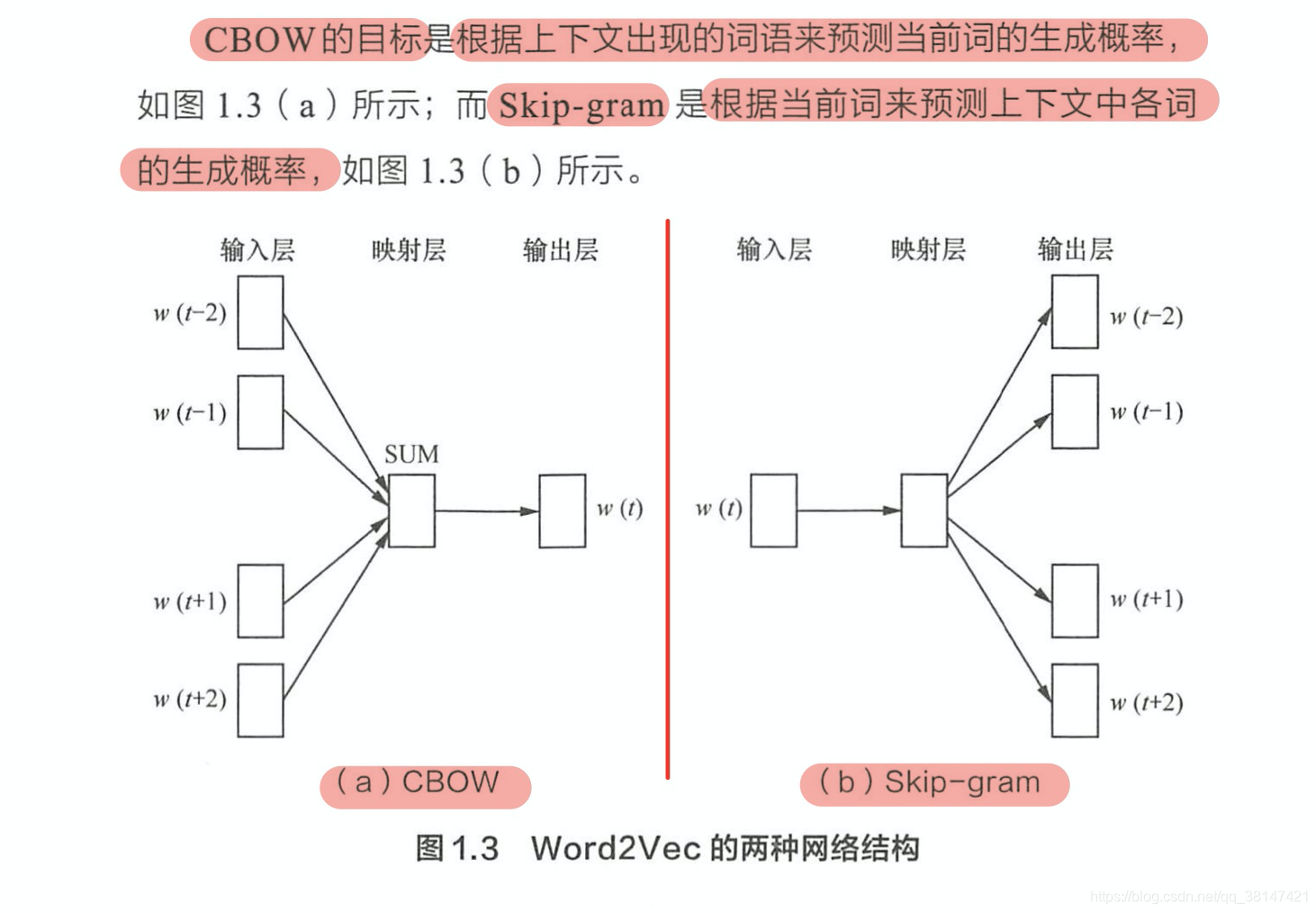
Word2Vec是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW(Continue Bags of Words)和Skip-gram
具体看下面两篇博客
博客1
博客2
1、Word2Vec是如何工作的?
CBOW(Continue Bags of Words)和Skip-gram都可以表示为输入层(Input)、映射层(Projection)、输出层(Output)组成的神经网络。
(这块另外总结)
当一句话为两个词的时候,那么:
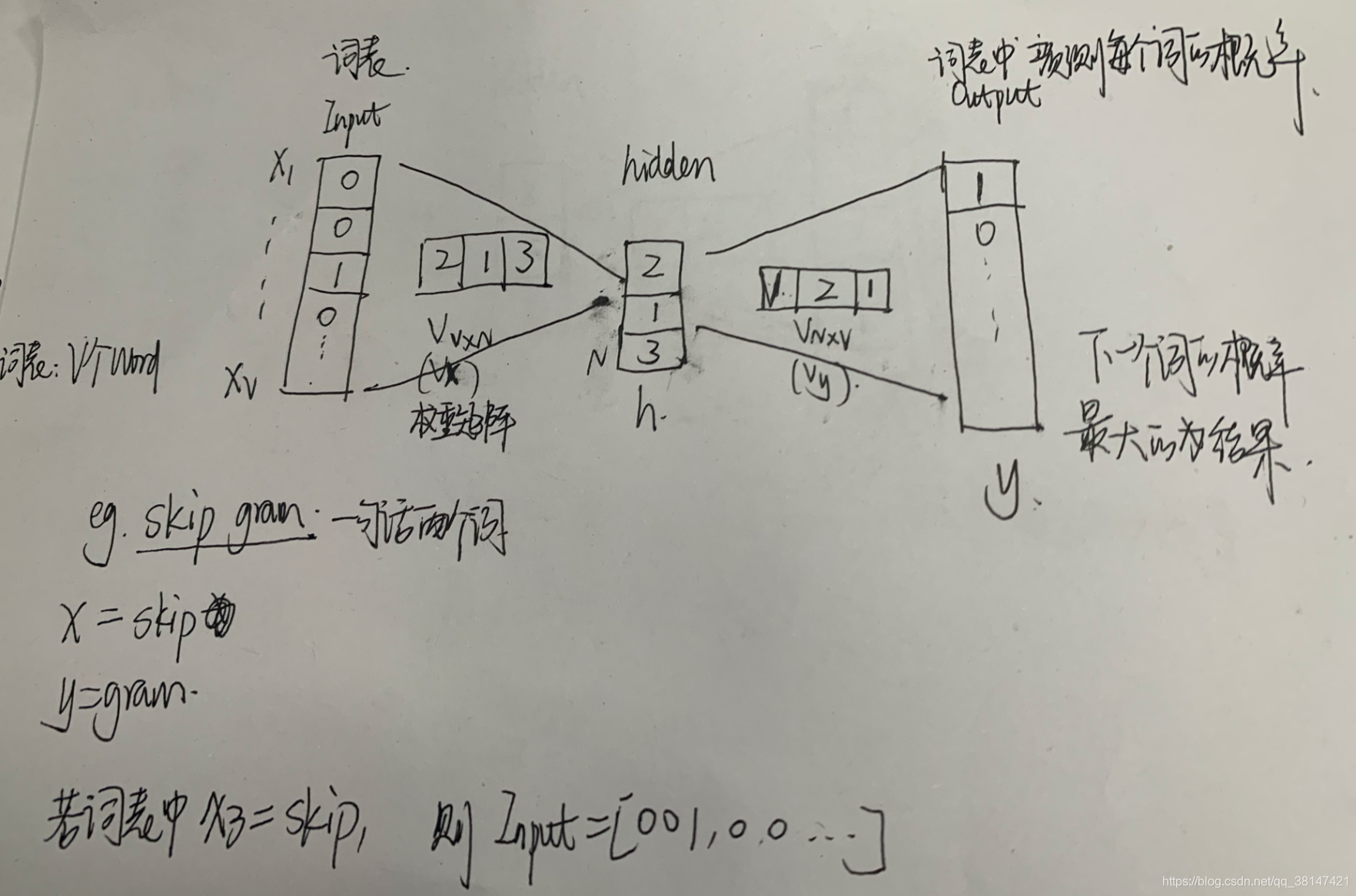
当一句话很长,相当于多对一(CBOW),或者一对多(Skip-gram)的时候。
在训练时候的两个Trick:层级softmax(跟哈夫曼树有关)和负采样。
2、Word2Vec和LDA有什么区别和联系?

七、图像数据不足时的处理方法
迁移学习、生成对抗网络、图像处理、上采样技术、数据扩充

















 2856
2856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









