







摘要:首先简单介绍多任务学习的方法,然后结合【1】给出权重自适应变化代价函数的原理与论文源码进行实现。使用Keras框架,参考论文链接。
目录
- 多任务学习简介
- 不确定性加权的多任务学习
主要参考文献
【1】“Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”。
【2】“Deep learning”,花书。
1. 多任务学习简介
多任务学习通过合并几个任务重的样例提高模型的泛化能力,因此可作为一种正则化的手段。
多任务学习的模型通常包括:1. 具体任务独立的参数;2. 所有任务共享的参数。训练过程中两部分参数同时更新。
底层参数通常为共享参数,学习不同任务共有的底层表示。利用相同数据集的不同任务,底层表示可能存在某些统计关系,因此能缓解过拟合,提高泛化能力。
多任务学习常见的代价函数是不同任务的加权和
L
(
W
)
=
∑
I
=
1
n
α
i
L
i
(
W
)
L({\bf{W}})=\sum_{I=1}^n\alpha_iL_i({\bf{W}})
L(W)=I=1∑nαiLi(W)
其中
α
i
\alpha_i
αi是每个任务的权重,通常是手工选择或者用网格搜索的方式确定,属于额外的超参数。
2. 不确定性加权的多任务学习
文章应用在场景理解的CityScapes数据集,用不确定性加权的方式实现自适应权重的多任务学习代价函数,结论为**方法性能优于手工权重及单任务学习。 **
- 研究背景
多任务学习性能受权重影响较大,但手工加权的代价太大。如下图所示: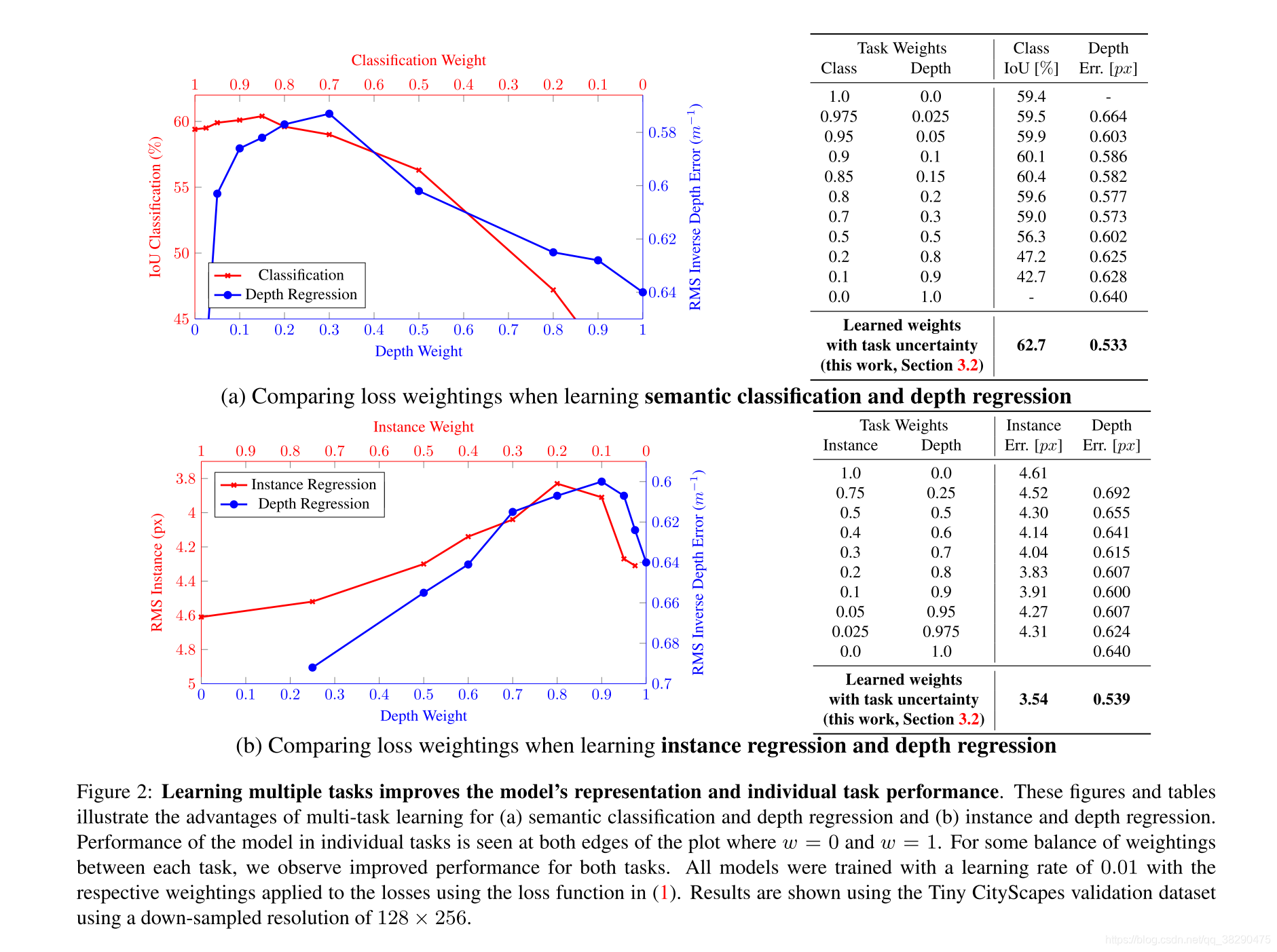
- 研究问题
有效的多任务损失加权方式。
- 研究思路
在贝叶斯模型中,有两类可以建模的不确定性,即认知不确定性(缺少训练数据)、偶然不确定性(数据不能解释信息),认知不确定性可以通过增加训练数据缓解,偶然不确定性可以通过增加观察所有可解释变量的能力缓解。
偶然不确定性又可以分为两类,即数据依赖的异方差不确定性、任务依赖的同方差不确定性,异方差不确定性取决于模型输入并作为模型输出被预测,同方差不确定性对所有输入数据保持不变而在不同任务之间变化,因此可以描述为任务依赖的不确定性。
基于最大化同方差不确定性的高斯似然,可以推导得到多任务代价函数。
具有同方差任务不确定性的多任务代价函数最终为:
L
(
W
,
σ
1
,
σ
2
,
…
,
σ
n
)
=
∑
I
=
1
n
1
2
σ
i
2
L
i
(
W
)
+
log
σ
i
2
L({\bf{W}},\sigma_1,\sigma_2,\dots,\sigma_n)=\sum_{I=1}^n\frac{1}{2\sigma_i^2}L_i({\bf{W}})+\log\sigma_i^2
L(W,σ1,σ2,…,σn)=I=1∑n2σi21Li(W)+logσi2
其中
σ
i
\sigma_i
σi为可学习参数,作为每个任务的权重。最后一项作为正则项防止权重
σ
\sigma
σ无限制增大。
- 方法成果
在场景理解任务中,对语义分割,实例分割,深度回归三个任务进行多任务学习,并与单任务,两个任务,之间进行对比,得到优于已有方法的结果,对比统计结果如下表所示:
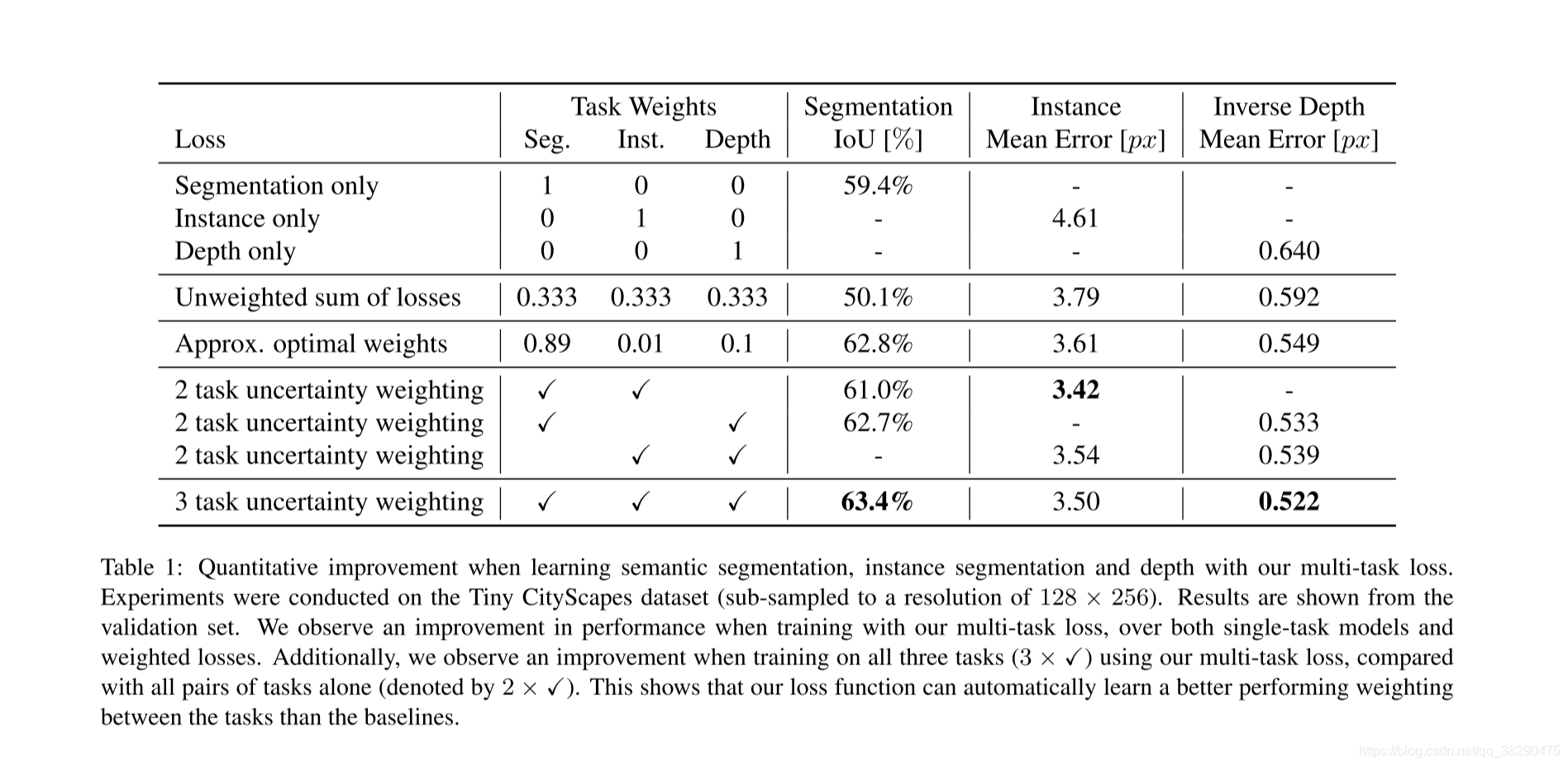
同时在附录中说明该方法对权重的初始化值不敏感。
- 创新点
提出一种能根据任务同方差不确定性自适应变化的多任务代价函数,并用统一的网络结构实现三种不同的任务。
- 源码链接
给出论文作者提供的源码,使用Keras框架,在实验中使用了相关的方法,可以直接调用类CustomMultiLossLayer。
import sys
import numpy as np
np.random.seed(0)
from keras import backend as K
from keras.layers import Input, Dense, Lambda, Layer
from keras.models import Model
from keras.initializers import Constant
class CustomMultiLossLayer(Layer):
"""Multi-task losses. Paper: https://arxiv.org/pdf/1705.07115v3.pdf. """
def __init__(self, n_tasks=2, **kwargs):
self.n_tasks = n_tasks
self.is_placeholder = True
super(CustomMultiLossLayer, self).__init__(**kwargs)
def build(self, input_shape=None):
"""initialize log_var value for each task."""
self.log_vars = []
for i in range(self.n_tasks):
self.log_vars += [self.add_weight(name='log_var' + str(i), shape=(1,),
initializer=Constant(0.), trainable=True)]
super(CustomMultiLossLayer, self).build(input_shape)
def multi_loss(self, ys_true, ys_pred):
"""Def multi-task loss as shown in paper."""
assert len(ys_true) == self.n_tasks and len(ys_pred) == self.n_tasks
loss = 0
for y_true, y_pred, log_val in zip(ys_true, ys_pred, self.log_vars):
precision = K.exp(-log_val[0])
loss += K.sum(precision * (y_true - y_pred) ** 2. + log_val[0], -1)
return K.mean(loss)
def call(self, inputs):
ys_true = inputs[:self.n_tasks]
ys_pred = inputs[self.n_tasks:]
loss = self.multi_loss(ys_true, ys_pred)
self.add_loss(loss, inputs=inputs)
return K.concatenate(inputs, -1)
def get_trainable_model(prediction_model):
""" Trainable model
# Arguments
prediction_model: Model, standard multi-task model
# Returns
Model for training
"""
inp = Input(shape=(Q, ), name='inp')
y1_pred, y2_pred = prediction_model(inp)
y1_true = Input(shape=(1,), name='y1_true')
y2_true = Input(shape=(1,), name='y2_true')
out = CustomMultiLossLayer(n_tasks=2)([y1_true, y2_true, y1_pred, y2_pred])
return Model([inp, y1_true, y2_true], out)
def get_prediction_model():
inp = Input(shape=(Q,), name='inp')
x = Dense(nb_features, activation='relu', name='x')(inp)
y1_pred = Dense(D1, name='y1_pred')(x)
y2_pred = Dense(D2, name='y2_pred')(x)
return Model(inp, [y1_pred, y2_pred])
N = 100
nb_epoch = 2000
batch_size = 20
nb_features = 1024
Q = 1
D1 = 1 # first output
D2 = 1 # second outpu
prediction_model = get_prediction_model()
trainable_model = get_trainable_model(prediction_model)
trainable_model.compile(optimizer='adam', loss=None)
assert len(trainable_model.layers[-1].trainable_weights) == 2
assert len(trainable_model.losses) == 1
def gen_data(N):
X = np.random.randn(N, Q)
w1 = 2.
b1 = 8.
sigma1 = 1e1 # ground truth
Y1 = X.dot(w1) + b1 + sigma1 * np.random.randn(N, D1)
w2 = 3
b2 = 3.
sigma2 = 1e0 # ground truth
Y2 = X.dot(w2) + b2 + sigma2 * np.random.randn(N, D2)
return X, Y1, Y2
import pylab
%matplotlib inline
X, Y1, Y2 = gen_data(N)
pylab.figure(figsize=(3, 2))
pylab.scatter(X[:, 0], Y1[:, 0])
pylab.scatter(X[:, 0], Y2[:, 0])
pylab.show()
hist = trainable_model.fit([X, Y1, Y2], nb_epoch=nb_epoch, batch_size=batch_size, verbose=0)
# Found standard deviations (ground truth is 10 and 1):
[np.exp(K.get_value(log_var[0]))**0.5 for log_var in trainable_model.layers[-1].log_vars]

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









