







一、YOLO12论文解读

官方论文地址:https://arxiv.org/pdf/2502.12524
官方代码地址: https://github.com/sunsmarterjie/yolov12
摘要:2025 年 2 月 18 日,布法罗大学与中国科学院大学联合发布了 YOLOv12。作为一款以注意力机制为核心的实时目标检测器,YOLOv12 在保持与传统 CNN 框架相当速度的同时,充分发挥了注意力机制在建模能力方面的优势。一直以来,提升 YOLO 框架的网络结构至关重要,但由于注意力模型的速度较难与 CNN 相抗衡,研究大多仍停留在基于 CNN 的改进上。YOLOv12 的出现,则成功将注意力机制与高效实时检测深度结合,进一步推动了 YOLO 在速度与精度上的平衡与突破。实验表明,YOLOv12 在准确率上超越了所有主流的实时目标检测器,并且速度同样具备竞争力。以 YOLOv12-N 为例,在 T4 GPU 上的推理延迟只有 1.64 毫秒,mAP 达到 40.6%,在相似推理速度下分别比先进的 YOLOv10-N 和 YOLOv11-N 高出 2.1% 和 1.2% 的 mAP。这种优势在其他模型规模上也同样存在。并且,YOLOv12 也超越了对 DETR 进行改进的端到端实时检测器(如 RT-DETR 与 RT-DETRv2):YOLOv12-S 对比 RT-DETR-R18 / RT-DETRv2-R18 时,在推理速度快 42% 的同时,仅使用了它们 36% 的计算量和 45% 的参数量。
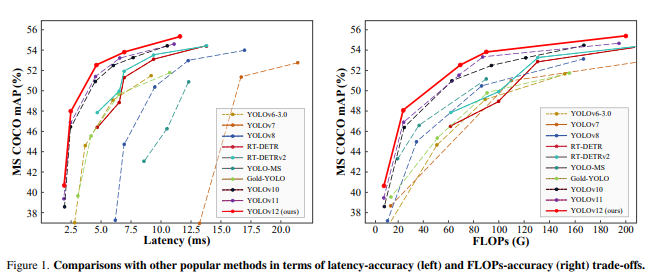
模型结构:
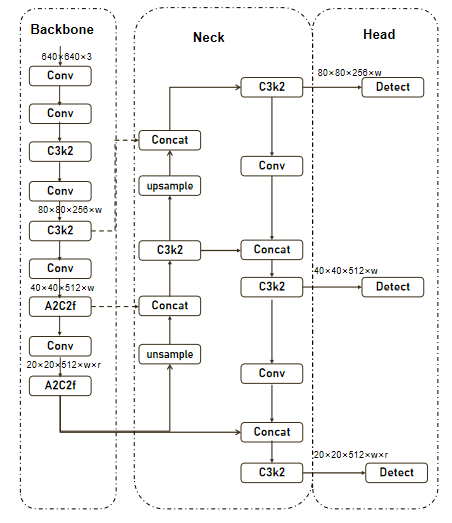
Backbone(主干网络):由Conv(卷积层)、C3k2 和 A2C2f 模块组成,C3k2是YOLO11中提出的模块,用于辅助特征提取,A2C2f 为YOLO12中首次提出的结构,用于特征提取,进一步处理和提炼特征。
Neck(颈部网络):包含 Concat(拼接层)、Upsample(上采样层)和 A2C2f 模块。对 Backbone 提取的特征进行融合和调整,通过上采样和拼接操作,整合不同层次的特征信息,增强特征的表达。
Head(头部网络):与YOLO11的结构相同,由多个 Detect(检测层)组成,负责最终的目标检测任务,输出检测到的目标的类别和位置信息。
主要贡献:
这篇论文旨在突破传统基于 CNN(卷积神经网络)的 YOLO 系列在网络结构层面的改进思路,转而将注意力机制(Attention Mechanism)引入 YOLO 主干网络,提出了名为 YOLOv12 的“注意力中心”实时目标检测器。作者认为,尽管注意力机制在视觉建模上有更强的表达能力,但过去一直存在在速度上落后于 CNN 的问题,因此并未被主流 YOLO 采纳。为解决“注意力机制+实时检测”中效率不足的难题,作者在网络结构和核心组件上都做出了若干改进,包括:
1,Area Attention(区域注意力)
将特征图按照竖向或者横向简单分块,再分别计算局部注意力,与常规的全局自注意力相比,极大地降低了计算量和存储访问开销,又能够维持较大的感受野。再结合 FlashAttention 等技术,实现了与卷积网络相当甚至更快的推理速度。

2,Residual Efficient Layer Aggregation Networks(R-ELAN)
针对 YOLO 系列中常见的 ELAN 模块,作者引入了残差连接(并加上一个缩放因子)来缓解注意力网络在大模型上难以收敛的优化问题。此外,修改特征聚合方式后,也减少了参数与计算量,并改善了特征融合质量。
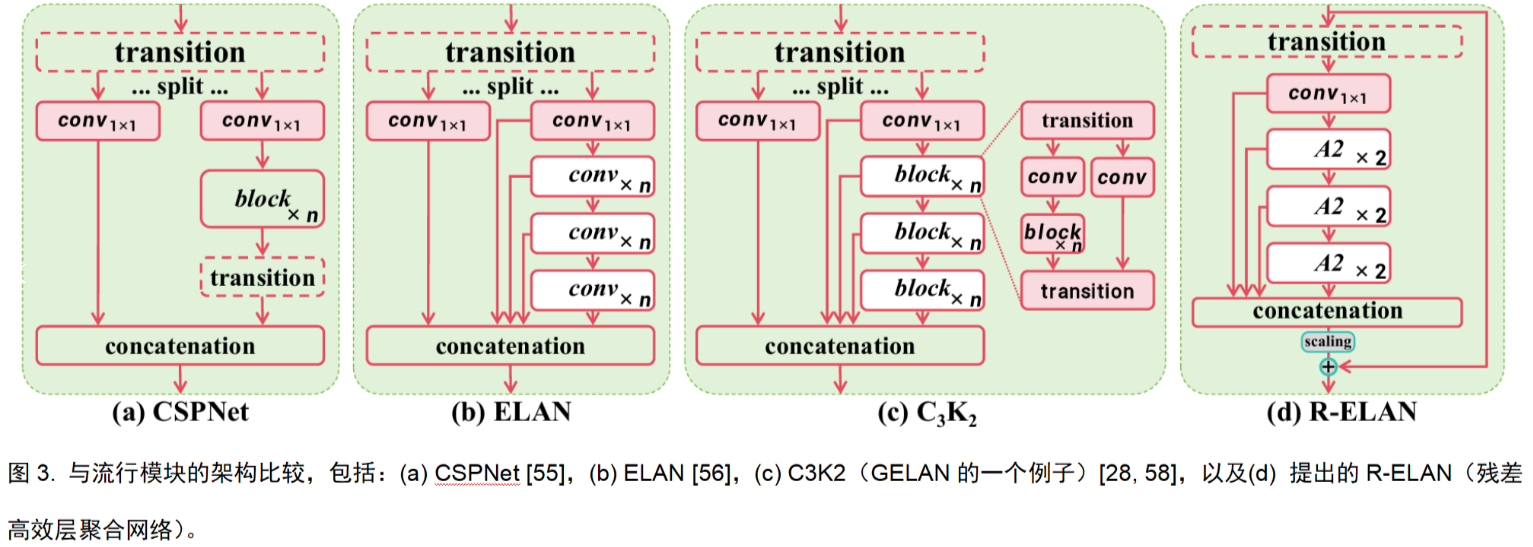
3,其它针对注意力机制的优化
-
减小 MLP Ratio(例如从传统的 4 减小到 1.2),使注意力的计算在模型中占更大比例;
-
去除位置编码,改用大卷积核(如 7×7)来在注意力值上做平滑(“position perceiver”),以帮助网络获取部分位置信息;
-
依然采取分阶段(stage-wise)的层次化设计,而非纯 Transformer 的平铺式结构,以更好地适配 YOLO 对多尺度特征的需求;
-
结合硬件优化,如 FlashAttention,显著降低了注意力计算的显存访问开销并提升推理速度。
实验:
在COCO数据集上的结果:
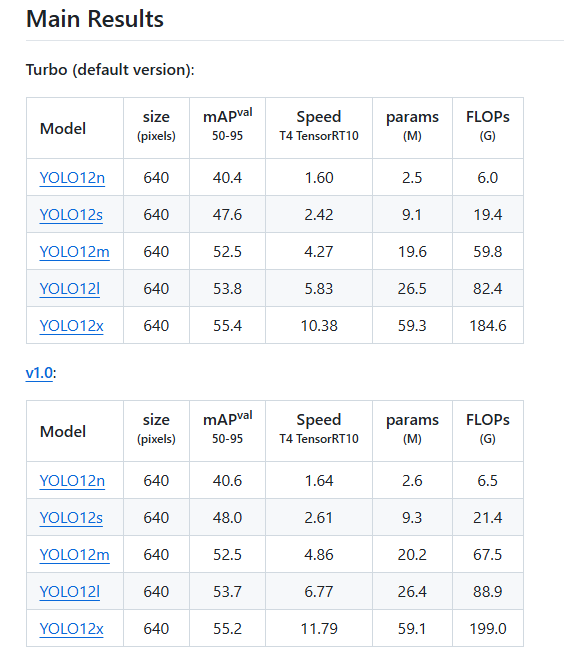
在仅消耗 6.5G FLOPs 和 2.6M 参数的前提下,YOLO12-N 即可获得 40.6% mAP,推理延迟低至 1.64ms/image。它非常适用于对计算资源苛刻、但对检测精度要求相对有限的实时场景,例如移动端或低配嵌入式系统的目标检测,能够保证快速响应并提供较为准确的结果。
YOLO12-S 规模略大(21.4G FLOPs、9.3M 参数),可达 48.0 mAP,推理延迟约 2.61ms/image。相较同类 S 规模模型,它在速度和精度之间达成了良好平衡。以智能交通系统为例,需要在短时间内处理大量视频帧并准确识别车辆、行人等多类目标,YOLO12-S 在此类场景中能提供高效且稳定的检测性能,为交通管理和安全决策提供及时信息。
当对目标检测精度要求更高,且硬件算力相对充足时,YOLO12-M(67.5G FLOPs、20.2M 参数)在 4.86ms/image 的速度下可实现 52.5 的 mAP,在中等规模模型中具备显著精度优势。比如工业生产线的缺陷检测,需要抓取微小特征且保证一定的实时性,YOLO12-M 可在高精度与合理速度间取得良好兼顾,不会因检测过慢而影响生产效率。
至于规模更大的 YOLOv12-L 与 YOLOv12-X,其 mAP 分别可达 53.7 和 55.2,尽管在计算量和推理延迟上相应有所提升,但对于医学影像中微小病灶检测或卫星图像中特定目标识别等对准确度要求极高的场景,更高精度能大幅降低漏检与误检,为专业分析和决策提供更可靠的支持。
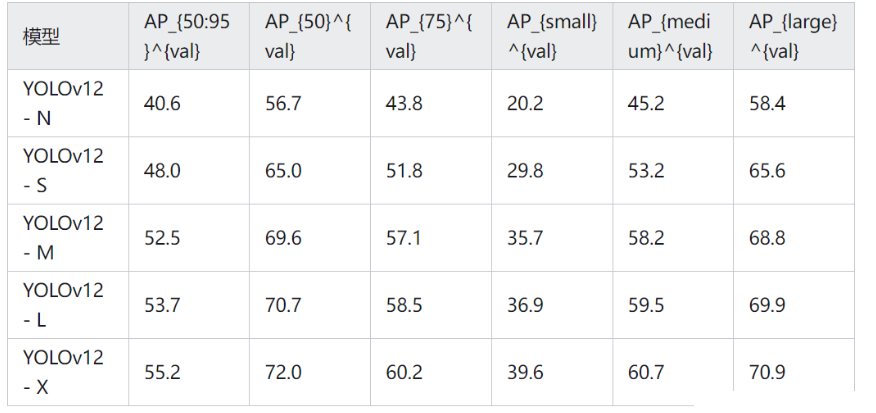
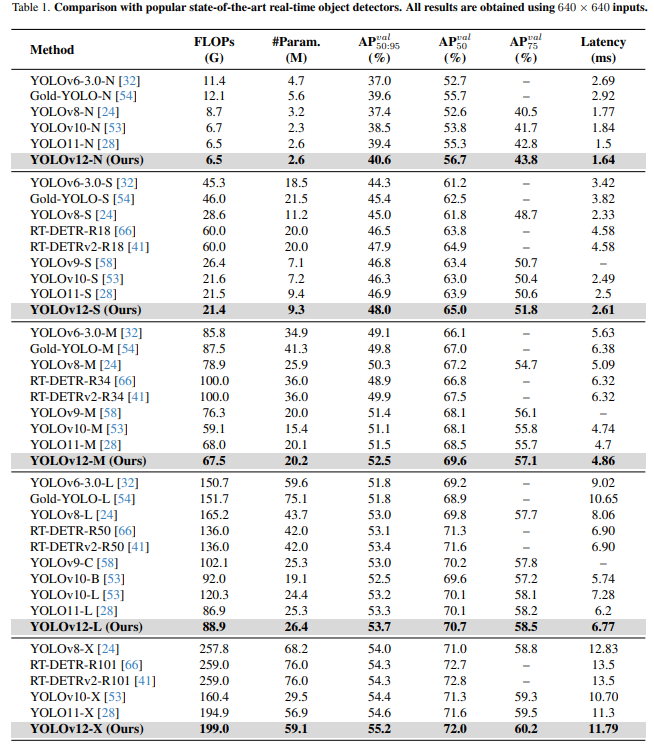
和主流模型的对比实验:
与 RT-DETR 系列相比,YOLOv12-S 相较于 RT-DETR-R18 / RT-DETRv2-R18 的 mAP 分别提升了 1.5% 和 0.1%,推理速度快 42%,而所需的计算量和参数分别仅为对方的 36% 和 45%。这意味着 YOLOv12-S 不仅达成了更高的检测精度,也以更少的资源与参数实现了更快的推理速度。在模型结构上,YOLOv12 采用的区域注意力机制与 R-ELAN 设计有效降低了计算复杂度,并优化了特征提取与聚合过程,从而在提升性能的同时减少了资源消耗。
与其他同属 YOLO 系列的版本相比,YOLOv12 在各个模型规模下也同样展现了性能提升:YOLOv12-N 比 YOLOv10-N 的 mAP 高出 2.1%,推理速度更优;YOLOv12-X 相较于 YOLOv10-X,mAP 增加 0.8%,速度、计算量和参数则大体相当。这些对比结果充分表明,YOLOv12 通过全新的结构设计与优化策略,突破了传统 YOLO 框架的性能瓶颈,为实时目标检测带来了新一轮的提升与突破。
总结:
YOLOv12 将注意力机制融入 YOLO 框架,在实时目标检测任务的速度与精度平衡上取得了领先成果。为实现高效推理,作者设计了新颖的网络结构:通过 区域注意力 减少计算复杂度,并利用 R-ELAN(残差高效层聚合网络) 增强特征聚合。此外,还对传统注意力机制中的关键部分加以优化,使其更好地适配 YOLO 的实时需求。将区域注意力、R-ELAN 与整体架构优化有机结合后,YOLOv12 在保持高速度的同时大幅提升了检测精度和效率。全面的消融研究进一步验证了这些创新设计的有效性。该成果不仅打破了过去 CNN 在 YOLO 系统中的垄断地位,也为注意力机制在实时目标检测中的应用提供了新的方向,推动了更高效、更强大的 YOLO 系统的发展。
二、训练自己的数据集
1,数据集准备
YOLOv12 的标注方式通常与其他 YOLO 系列保持一致,每张图片对应一个 .txt 文件,其中每一行包含“类别索引 + 边界框 x_center, y_center, width, height”这五个值,均为归一化坐标。数据集的目录结构如下图所示。

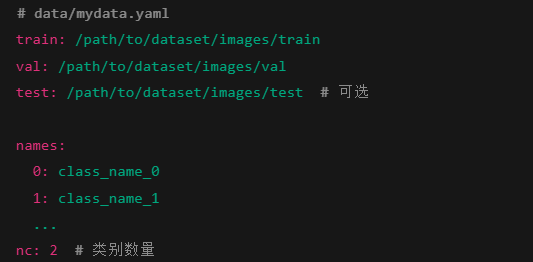
通常通过一个 .yaml 配置文件指定数据集路径、类别数量及类别名称列表,如下图所示。
2,下载模型,配置实验环境。
官方代码的下载地址为:https://github.com/sunsmarterjie/yolov12
下载之后创建个虚拟环境,命令如下:
conda create -n yolov12 python=3.11然后激活虚拟环境,并安装相应的包,命令如下:
conda activate yolov12
pip install torch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 --index-url https://download.pytorch.org/whl/cu118
pip install ultralytics
pip install timm==1.0.7 thop efficientnet_pytorch==0.7.1 einops dill==0.3.8 albumentations==1.4.11 pytorch_wavelets==1.3.0 tidecv PyWavelets opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
到这一步,环境就基本安装好了。
接着,我们可以在代码中新建train.py、val.py、detect.py用以训练、验证、检测。代码如下所示:
train.py:
import warnings, os
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/12/yolov12.yaml') #在这里选择使用的模型配置文件
# model.load('yolo11n.pt') # loading pretrain weights
model.train(data='ultralytics\cfg\datasets\coco128.yaml',#在这里选择数据集的配置文件
imgsz=640,
epochs=100,
batch=16,
close_mosaic=0,
device='0',
# patience=0, # set 0 to close earlystop.
# resume=True, # 断点续训,YOLO初始化时选择last.pt
# amp=False, # close amp | loss出现nan可以关闭amp
# fraction=0.2,
project='runs/train',
name='exp',
)val.py:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model_path = 'runs/train/exp/weights/best.pt'
model = YOLO(model_path) # 选择训练好的权重路径
result = model.val(data='ultralytics\cfg\datasets\coco128.yaml',
split='val', # split可以选择train、val、test
imgsz=640,
batch=16,
# iou=0.7,
# rect=False,
# save_json=True, # if you need to cal coco metrice
project='runs/val',
name='exp',
)detect.py:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('runs/train/exp/weights/best.pt') # select your model.pt path
model.predict(source='dataset/images/test',
imgsz=640,
project='runs/detect',
name='exp',
save=True,
# conf=0.2,
# iou=0.7,
# agnostic_nms=True,
# visualize=True, # visualize model features maps
# line_width=2, # line width of the bounding boxes
# show_conf=False, # do not show prediction confidence
# show_labels=False, # do not show prediction labels
# save_txt=True, # save results as .txt file
# save_crop=True, # save cropped images with results
)之后,我们使用train.py就可以进行训练,val.py可以进行验证,detect.py可以进行推理。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









