






https://zhuanlan.zhihu.com/p/521631165
Nvidia H100 中的FP8
首先,矩阵乘法中的每个乘加操作(Multiply-Add)通常涉及两个步骤:乘法和累加。例如,在计算C = A*B时,每个元素的计算是A的行元素与B的列元素对应相乘,然后将这些乘积相加得到C中的一个元素。这里的“相乘”和“相加”操作分别涉及到不同的精度处理。
如果输入矩阵是FP8,那么乘法操作的结果会是FP8乘以FP8的结果。这里需要考虑FP8的精度限制。两个8位浮点数相乘的结果可能超过8位的表示范围,所以需要扩展精度来保存中间结果。此时,累加器的精度(FP16或FP32)就派上用场了。累加器需要足够的位宽来存储多个乘积的和,避免溢出或精度损失。
例如,假设两个FP8数相乘后的结果需要更多的位数来表示,这时候如果立即转换为FP8来累加,可能会导致精度损失或溢出。而如果用更高精度的累加器(如FP32)来保存中间结果,多次累加后的总和会更准确。在最终存储结果时,可能再将其转换为较低的精度(如FP16或FP8),但中间过程的累加器保持高精度可以提升整体计算的准确性。

GiantPandaCV浅谈 NVIDIA-H100 白皮书
引入FP8 Thread Block Cluster 多个Block 共享一个SM及其共享内存。 引入TMA
FP8 量化基础 - 英伟达
数值范围越大,量化误差越大。
FP8 量化-原理、实现与误差分析
FP8 量化误差与scale 容错率高, INT8 需要认真选择scale, 但是Int8 合试scale 下, 量化精度更高, 远超过Fp8
FP8 FORMATS FOR DEEP LEARNING 学习
3 FP8二进制交换格式
FP8包含两种编码格式——E4M3和E5M2,其名称明确表示指数位(E)和尾数位(M)的数量。我们使用通用术语“尾数”(mantissa)作为IEEE 754标准中“尾随有效数字段”(trailing significand field)的同义词(即不包含规格化浮点数隐含的前导1的位)。FP8编码的推荐使用方式为:权重和激活张量采用E4M3格式,梯度张量采用E5M2格式。尽管某些网络仅使用E4M3或E5M2类型即可完成训练,但也有一些网络需要同时使用两种类型(或必须大幅减少FP8中维护的张量数量)。这与文献[20, 16]的结论一致,其中训练的推理和前向传播采用E4M3的变体,而训练反向传播中的梯度则使用E5M2的变体。
FP8编码细节在表1中定义。我们使用S.E.M符号描述表中的二进制编码,其中S为符号位,E为指数字段(包含4或5位有偏指数),M为3位或2位尾数。下标含2的值为二进制(如1.0102),其余为十进制。
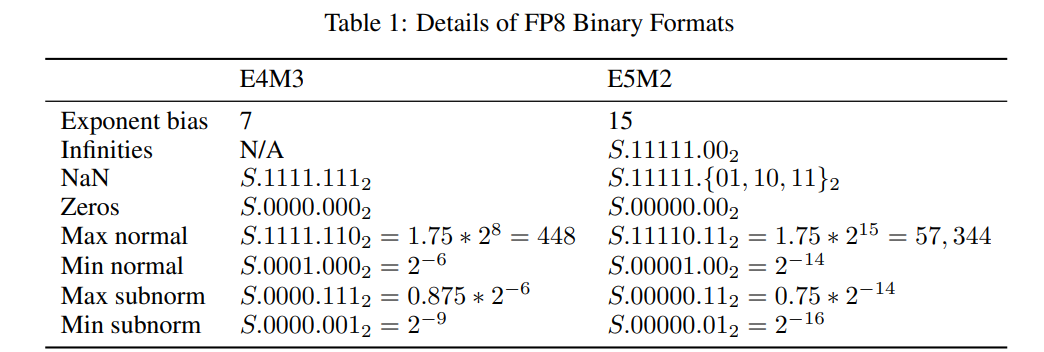
FP8格式的设计遵循与IEEE-754标准保持一致的原则,仅当对深度学习(DL)应用的精度有显著提升时才进行调整。因此,E5M2格式完全遵循IEEE 754的指数规则和特殊值定义,可视为一种减少尾数位的IEEE半精度格式(类似于bfloat16和TF32作为减少位数的IEEE单精度格式)。这使得E5M2与IEEE FP16格式之间的转换简单直接。相比之下,E4M3格式通过回收大部分用于特殊值的位模式来扩展动态范围,因为在深度学习场景中,更大的数值范围比支持多种特殊值编码更为重要。
即不包含规格化浮点数隐含的前导1的位, 什么意思?
*

3.1 特殊值表示
为扩展E4M3格式的有限动态范围,我们通过减少特殊值的表示数量,将其位模式重新用于常规数值。具体而言:
不表示无穷大 (溢出处理详见第2节);
仅保留一个尾数位模式用于NaN (非数)。
此调整使动态范围扩展了一个二进制数量级(binade),从17个增加到18个。新增的7个可表示数值(256、288、320、352、384、416、448)对应有偏指数1111₂(即十进制15)。若不进行此调整,E4M3的最大可表示值仅为240。
为保持与IEEE 754标准的一致性,我们仍保留零和NaN的正负表示对称性。尽管通过取消零和NaN的正负区分可额外获得一个数值(480),但这会破坏IEEE 754固有的符号对称性,导致依赖该特性的算法(如基于整数操作的浮点比较与排序)失效。由于将最大值从448提升至480对深度学习(DL)的收益有限,我们选择遵循IEEE惯例以兼容现有软件生态。
相比之下,E5M2格式完全遵循IEEE标准 ,支持所有特殊值(无穷大、NaN、正负零)。大量实证研究(第4节)表明,5位指数为深度学习提供了足够的张量级动态范围(32个二进制数量级,含非规格化值)。此外,若在E5M2中采用类似E4M3的特殊值压缩策略,仅能增加3个可表示数值(因尾数位更少),且单个二进制数量级的扩展对已有32个binade的E5M2影响微乎其微(而E4M3未调整时仅17个binade)。
3.2 指数偏置
E4M3和E5M2格式均沿用类似IEEE标准的指数偏置值:E4M3的偏置为7,E5M2为15。指数偏置 决定了数值可表示范围在实数轴上的分布位置。通过为每个张量维护独立的缩放因子(scale factor),也能实现相同的效果。
实验表明,某些神经网络无法对同类张量统一使用相同的指数偏置值,需进行逐张量调整 (例如第4.3节的案例)。因此,我们选择遵循IEEE的指数偏置惯例,而将逐张量缩放的灵活性交由软件实现 。这种设计比可编程指数偏置更具优势:
缩放因子 可为任意实数(通常以更高精度存储),而可编程指数偏置仅允许2的幂次作为缩放值;
软件实现的缩放机制能更灵活地适应不同张量的动态范围需求。

4.2 推理
FP8训练极大简化了8位推理的部署,因为推理和训练使用相同的数值类型。这与使用32位或16位浮点训练后转为int8推理的情况形成鲜明对比——后者通常需要训练后量化(PTQ)校准,甚至量化感知训练(QAT)来维持模型精度。此外,即使采用量化感知训练,某些int8量化模型仍可能无法完全恢复浮点运算的精度[1]。
我们评估了16位浮点训练模型转为FP8的训练后量化效果。表5列出了FP16训练模型量化为int8或E4M3格式后的推理精度。两种量化方式均采用权重的每通道缩放因子和激活值的每张量缩放因子(与int8定点数惯例一致)。所有矩阵乘法操作(包括注意力机制中的批量矩阵乘法)的输入张量均被量化。权重采用最大值校准(通过缩放因子确保张量最大幅值可表示),激活张量则从最大值、百分位数和均方误差(MSE)方法中选择最佳校准方式。BERT语言模型在斯坦福问答数据集(SQuAD)上的评估显示,FP8 PTQ保持了精度,而int8 PTQ导致显著的精度损失。我们还尝试了不使用缩放因子直接转换为FP8张量,结果出现严重精度下降,困惑度升至11.0。GPT模型在wikitext103数据集上的评估表明,FP8 PTQ在保持模型精度方面显著优于int8 PTQ。
表5:16位浮点训练模型的训练后量化结果。F1指标值越高越好,困惑度越低越好。最佳8位结果以粗体显示。
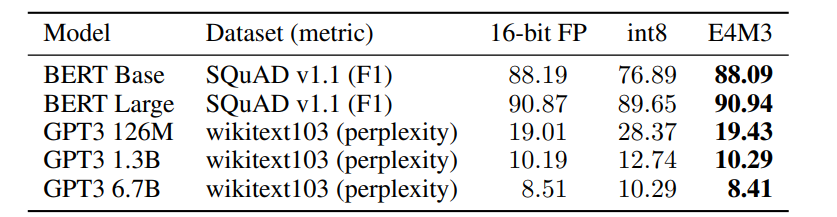
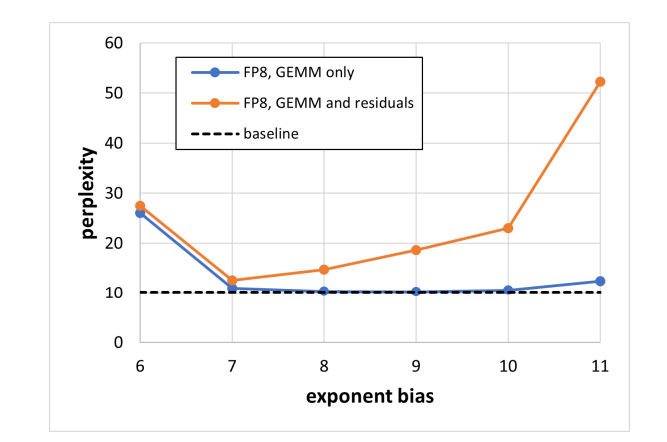
意思就是,使用多个bias, 缩放因子。per tensor sacle. . 尤其当 张量个数增加时, 更需要多个bias, 如图黄色, 量化增加了residual 的add 输入张量, 量化误差增加, 在不校准的情况下。
4.3 每张量缩放因子
虽然许多网络的训练和推理在FP8中使用相同张量类型的统一缩放因子(即选择单一指数偏置)即可成功完成,但在某些情况下需要为每个张量单独设置缩放因子以保持精度。当我们需要将更多张量(而不仅仅是GEMM操作的输入)以FP8存储时,这种需求变得更加显著。图2展示了使用训练后量化将bfloat16训练的网络转换为FP8时的困惑度(在wikitext103数据集上测量)。实验未进行校准,权重和激活张量直接通过对应指数偏置从bfloat16转换为E4M3格式。可以看出,当仅将GEMM操作的输入(包括加权GEMM以及仅涉及激活值的两次注意力批量矩阵乘法)转换为FP8时,[7, 10]范围内的多个指数偏置值均可达到与bfloat16基线相当的结果。然而,若进一步将残差连接(Add操作的输入张量,这能进一步降低存储和内存带宽压力)也量化为FP8,则没有任何单一指数偏置值能满足精度要求——即使指数偏置为7时困惑度达到12.59,显著高于bfloat16基线的10.19。不过,若遵循int8量化的惯例(对权重和激活值分别使用每通道和每张量缩放因子)进行张量校准,则能有效解决这一问题。
delayed scale 和即时scale
https://www.53ai.com/news/finetuning/2024071113904.html

















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









