







DVDNET: A FAST NETWORK FOR DEEP VIDEO DENOISING
https://ieeexplore.ieee.org/document/8803136
摘要
现有的最先进视频去噪算法是基于补丁的方法,以往的基于NN的算在其性能上无法与其媲美。但是本文提出NN的视频去噪算法性能要好:
- 其相比于基于补丁的算法,计算时间明显缩短
- 相比于其他神经网络算法,其占用内存小,能够使用单个模型处理各种噪声水平
介绍
我们介绍了一个用于深度视频去噪的网络:DVDnet。该算法与其他最先进的方法相比具有优势,同时它具有快速运行时间。我们算法的输出呈现出显着的时间相干性、非常低的闪烁、强大的降噪和准确的细节保留。
图像去噪
最近的图像去噪算法大多基于深度学习技术,其性能较好,但是这些性能都是 restricted to specific forms of prior基于特定形式的先验,并且需要 hand-tuned parameters手动调参。
目前多数的算法都面临一个缺点:a specific model must be trained for each noise level. 必须为每个噪声级别训练一个模型
视频去噪
基于神经网络的算法并不多,其性能可能还不如基于补丁的方法,但是通过发展VBM4D/VNLB等等,其目前VNLB能够获得相对最好的去噪效果,但是其问题是:需要很长的运行时间——即使处理单帧也需要几分钟。但是本文提出的算法要比VNLB更好。
本文方法
发展现状:most previous approaches based on deep learning have failed to employ the temporal information existent in image sequences effectively.
去噪关键:Temporal coherence and the lack of flickering(无闪烁) vital aspects in the perceived quality of a video.
强制输出时间冗余相关的办法:
- the extension of search regions from spatial neighborhoods to volumetric neighborhoods
- the use of motion estimation.

首先去噪分为两个阶段:
- individually denoised with a spatial denoiser. 空间去噪 单独进行去噪
- egistered with respect to the central fram
(1)虽然在spatial denoising阶段的单帧去噪结果较好,但是作为一个序列来说,有明显的闪烁现象;因此,在二阶段通过光流变形将相邻帧向中心帧对齐,完成运动补偿后。
(2)将 2T + 1 个对齐的帧连接起来并输入到时间去噪块中。在对每帧进行去噪时使用时间邻居有助于减少闪烁,因为每帧中的残差是相关的。
原文:Finally, the 2T + 1 aligned frames are concatenated and input into the temporal denoising block. Using temporal neighbors when denoising each frame helps to reduce flickering as the residual error in each frame will be correlated.
此外,添加了一个噪声图作为空间和时间降噪器的输入。包含噪声图作为输入允许处理空间变化的噪声[18]。与其他去噪算法相反,我们的去噪器除了图像序列和输入噪声的估计外,没有其他参数作为输入。
时间和空间去噪块
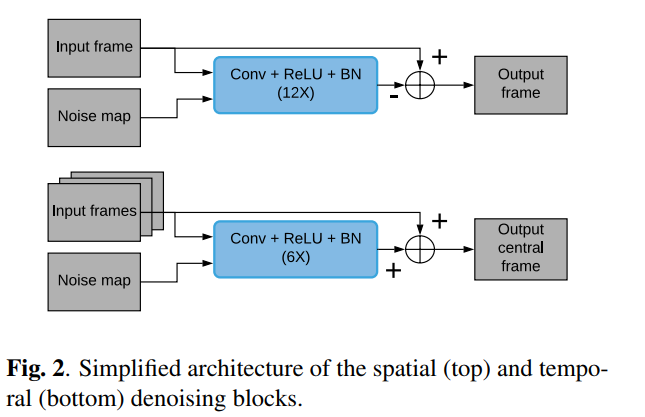
空间和时间块的设计特点在性能和快速运行时间之间做出了很好的
a good compromise折衷。这两个模块都被实现为标准的前馈网络,空间降噪器的架构受到[8, 9]中架构的启发,而时间降噪器也借鉴了[13]中的一些元素。
空间和时间去噪块分别由 D [ s p a t i a l ] D_[spatial] D[spatial] = 12 和 D [ t e m p o r a l ] D_[temporal] D[temporal]= 6 个卷积层组成。特征图的数量设置为 W = 96。卷积层的输出之后是逐点 ReLU [19] 激活函数 ReLU(·) = max(·, 0)。在训练时,批量归一化层(BN [20])放置在卷积层和 ReLU 层之间。
在测试时,the batch normalization layers 被移除,并由an affine layer that applies the learned normalization应用学习归一化的仿射层代替。卷积核的空间大小为 3 × 3,步幅设置为 1。
在两个块中,输入首先被缩小到四分之一分辨率。以较低分辨率执行去噪的主要优点是大大减少了运行时间和内存需求,而不会牺牲去噪性能 [8, 18]。使用 [21] 中描述的技术执行放大回全分辨率。两个块都具有残差连接 [10],据观察可以简化训练过程 [18]
训练细节
空间去噪块和时间去噪块单独训练,其中空间去噪优先进行;训练均采用图像裁剪的crop or patchs。通过添加σ∈[0,55]的AWGN对给定序列的patch
空间去噪块:WaterExploration DataBase数据集,共随机裁剪10240000个patchs,噪声patch=50,个人认为损失函数使用的是L2损失函数,其中运动估计采用的DeepFlow,从而进行补偿。
时间去噪块:DAVIS数据集
共同结构:the ADAM algorithm [25] is applied to min-imize the loss function,with all its hyper-parameters set to
their default values.所有超参数都设置为默认值。epoch=80, mini-batch=128,learning-rate前50轮
1
e
−
3
1e-3
1e−3,50-60轮
1
e
−
4
1e-4
1e−4,最后
1
e
−
6
1e-6
1e−6。
data augment通过引入不同的比例因子和随机翻转,数据增加了五倍。
结果
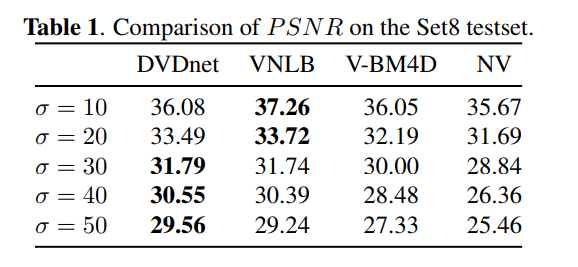
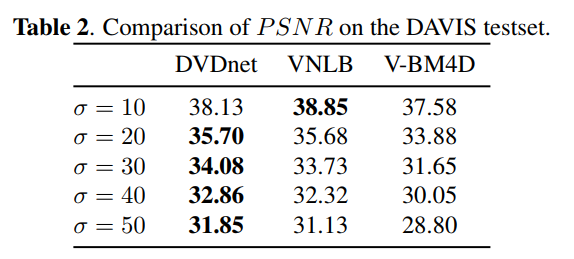
测试集:DAVIS /Sets8 (第一段阐述其数据集的参数)
比较:VBM4D VNLB NeatVideo(商业化去噪软件)

一般来说,DVDnet 输出的序列具有显着的时间连贯性。我们的方法渲染的闪烁非常小,尤其是在平坦区域,基于补丁的算法通常会留下低频残留噪声。可以在图 1 中观察到一个示例。 3(最好以数字格式查看)。平坦区域中的时间去相关低频噪声在观察者眼中显得特别烦人。更多视频示例可以在算法的网站上找到。

结论
com/imgs/20220402-1109-483.png" alt=“image-20220402110938126” style=“zoom:67%;” />
结论
DVDnet 的去噪结果具有显着的时间相干性、极低的闪烁和出色的细节保留。该算法实现的运行时间至少比其他最先进的竞争对手快一个数量级。尽管本文提出的结果适用于高斯噪声,但我们的方法可以扩展到去噪其他类型的噪声















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









