









基于负例的对比学习
负例的选择策略
- 之前有介绍过基于负例的对比学习:SimCLR模型,该方法将batch内的数据都作为负例。很多实验表明,在对比学习模型中,负例越多,那么对比学习的效果就越好。但是在实际情况汇总,基于负例限制的原因,我们不可能将负例batch无限放大,基于此我们在寻找负例是不再局限于在batch中寻找,而是在整个无标注数据中来寻找负例,随机选择任意大小的数据作为负例数据。那么这在实际中是如何去做的呢?
MocoV2选择策略
- mocov2是在simCLR结构的基础上进行优化,结合了simCLR的模型结构,以及更难的图像增强策略,针对moco的改进,模型mocov2效果有明显的提升。mocov2的模型结构如下图所示:
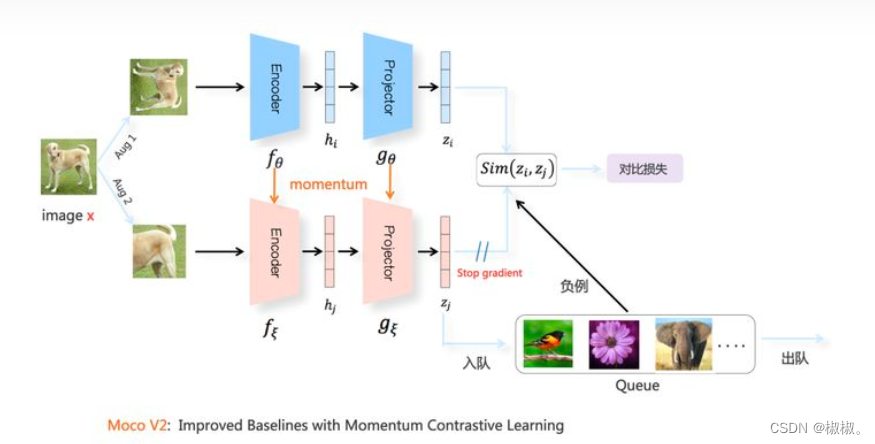
mocov2模型结构
- 模型结构主要包括:图像增强、projector、encoder编码、相似性计算以及infoNCE损失函数。主要的创新点在于:两个分支中的上下分支,在simCLr中,上下分支是对称的,两者之间的权值参数时共享的,但是在mocov2中,采用了动量更新机制。那么什么是动量更新机制?
动量更新机制
- 在mocov2中,两个分支都是由projecor和encoder编码层构成的,但是两个分支各自独有一套参数体系,这套参数更新更新并不是通过常规的损失函数BP反向传播来实现的,而是使用移动平均机制(moving
average)来进行参数更新。计算公式如下所示:
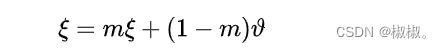
- 其中,在公式中,v为上分支的权重参数,ε为下分支的参数权重,m为权重调节系数。也就是意味着,在模型开始训练之后,随机初始化一个下分支权重参数ε,然后上分支通过反向传播进行梯度更新,参数发生变化之后,在进行下分支参数调节。一般在实际中,m的取值为0.9到0.99,这就意味着,相对于上分值参数,下分值参数变化缓慢而稳定,实现了小步慢行且向目标函数前进。
- mocov2维护了一个比较大的负例队列。当对比学习小选择正例对和负例对时,就需要从上述的负例计算公式中选择k个负例对,不再局限于batch中。实现上下分值参数动态调整的优势在于:一方面能够将第二组数据增强视图aug2中的图像,映射到对应的表示空间中,为第一组aug1提供正例,第二个作用就是更新负例队列中数据的图像表示编码,一般会将最新的aug2中的对应的特征表示编码放入到队列中,而最老的那个batch对应的图像编码进行出队,这样就可以一直更新负例队列中的编码内容。
**为什么要负例队列中的图像编码不用上分支对应的最新模型参数v,要用缓慢移动的参数εl来进行更新呢?
通过实验表明,假设动量更新公式中的m取值很小,意味着更多依赖更新参数v来更新负例队列的编码,对比学习模型效果将会急剧下降。**通俗来说就是,对比学习模型效果变动幅度比较大,不容易控制,小的参数变动会引起大的效果变化。
通过缓慢更新模型参数变化,给队列中来自不同batch内的实例表征编码相对稳定而统一的改变,增加了表示空间的一致性。
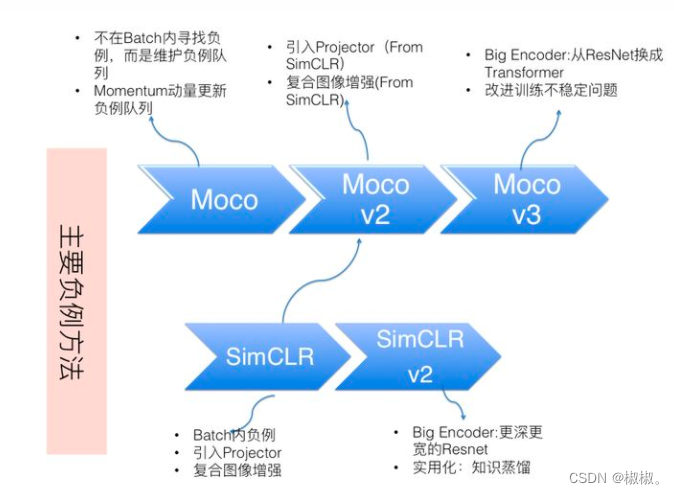
- 以mocov2为代表,介绍了全局数据范围内选择负例的典型做法。目前主流的基于负例的对比学习方法主要是一下这两类:以simCLR为代表的batch内负例,以及以moco为代表的全局选择负例方法。我们知道,simCLR和Moco不断做技术迭代,形成了系列版本。有很多实验表明,encoder特征编码部分,模型越复杂,模型效果越好。所以simCLR-v3和moco-v3都不约而同的选择了这条技术改进路线:SimCLR-v3增加了encoder的复杂度,采用了更深更宽的resnet,而mocov3则直接使用viT这种transformer模型替换掉了resnet。


















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











